確率分布
この記事では、統計における確率分布とは何かについて説明します。ここでは、確率分布の定義、確率分布の例、さまざまな種類の確率分布について説明します。
確率分布とは何ですか?
確率分布は、確率変数の各値の発生確率を定義する関数です。簡単に言うと、確率分布は、ランダムな実験で考えられるすべての結果の確率を記述する数学関数です。
たとえば、
したがって、確率分布はサンプル空間内のさまざまな事象の確率を計算するために使用されるため、確率理論や統計で頻繁に使用されます。
確率分布の種類
確率分布は、離散分布と連続分布という 2 つの大きなタイプに分類できます。
- 離散確率分布:分布は、区間内で可算数の値のみを取ることができます。通常、離散確率分布は整数値のみを取ることができます。つまり、小数点以下の桁はありません。
- 連続確率分布:分布は区間内で無限の数の値を取ることができます。一般に、連続確率分布は 10 進数値を取ることができます。
離散確率分布
離散確率分布は、離散確率変数の確率を定義する分布です。したがって、離散確率分布は有限数の値 (通常は整数値) のみを取ることができます。
離散一様分布
離散一様分布は、すべての値が等確率である離散確率分布です。つまり、離散一様分布では、すべての値が同じ発生確率を持ちます。
たとえば、考えられるすべての結果 (1、2、3、4、5、または 6) の発生確率が同じであるため、サイコロの目は離散一様分布で定義できます。
一般に、離散一様分布には、分布が取り得る値の範囲を定義する 2 つの特性パラメータaとbがあります。したがって、変数が離散一様分布で定義されている場合は、 Uniform(a,b)と書かれます。

すべての結果が同じ確率を持つ場合、実験がランダムであることを意味するため、離散一様分布を使用してランダム実験を説明できます。
ベルヌーイ分布
二分分布としても知られるベルヌーイ分布は、「成功」または「失敗」という 2 つの結果のみを持つことができる離散変数を表す確率分布です。
ベルヌーイ分布では、「成功」は期待される結果であり、値は 1 ですが、「失敗」は期待以外の結果であり、値は 0 です。つまり、「」の結果の確率が「成功」がpである場合、「失敗」の結果の確率はq=1-pです。
![\begin{array}{c}X\sim \text{Bernoulli}(p)\\[2ex]\begin{array}{l} \text{\'Exito}\ \color{orange}\bm{\longrightarrow}\color{black} \ P[X=1]=p\\[2ex]\text{Fracaso}\ \color{orange}\bm{\longrightarrow}\color{black} \ P[X=0]=q=1-p\end{array}\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-384fd7d96d4d6584739b04a6e331b251_l3.png "Rendered by QuickLaTeX.com")
ベルヌーイ分布は、スイスの統計学者ジェイコブ ベルヌーイにちなんで命名されました。
統計学では、ベルヌーイ分布には主に 1 つの用途があります。それは、成功と失敗の 2 つの結果しか存在しない実験の確率を定義することです。したがって、ベルヌーイ分布を使用する実験は、ベルヌーイ テストまたはベルヌーイ実験と呼ばれます。
二項分布
二項分布 は、二項分布とも呼ばれ、一定の成功確率で一連の独立した二分実験を実行したときの成功数をカウントする確率分布です。言い換えれば、二項分布は、一連のベルヌーイ試行の成功した結果の数を記述する分布です。
たとえば、コインを 25 回投げたときに「表」が出る回数は二項分布になります。
一般に、実行される実験の総数はパラメーターnで定義され、 pは各実験の成功確率です。したがって、二項分布に従う確率変数は次のように記述されます。

二項分布では、まったく同じ実験がn回繰り返され、実験は互いに独立しているため、各実験の成功確率は同じ(p)であることに注意してください。
魚の分布
ポアソン分布は、一定期間内に特定の数のイベントが発生する確率を定義する確率分布です。言い換えれば、ポアソン分布は、時間間隔内で現象が繰り返される回数を表す確率変数をモデル化するために使用されます。
たとえば、電話交換局が 1 分間に受信する通話の数は、ポアソン分布を使用して定義できる離散確率変数です。
ポアソン分布には、ギリシャ文字 λ で表される特徴的なパラメーターがあり、特定の間隔中に調査対象のイベントが発生すると予想される回数を示します。

多項分布
多項分布(または多項分布) は、いくつかの相互に排他的なイベントが数回の試行後に所定の回数発生する確率を記述する確率分布です。
つまり、ランダムな実験により 3 つ以上の排他的なイベントが発生する可能性があり、各イベントが個別に発生する確率がわかっている場合、多項分布を使用して、複数の実験が実行されたときに特定の数のイベントが発生する確率を計算します。毎回の時間。
したがって、多項分布は二項分布を一般化したものです。
幾何分布
幾何分布は、最初の成功結果を得るために必要なベルヌーイ試行回数を定義する確率分布です。つまり、幾何分布モデルでは、ベルヌーイ実験のいずれかが肯定的な結果が得られるまで反復されるプロセスをモデル化します。
たとえば、黄色い車が見えるまで高速道路を通過する車の数は幾何分布になります。
ベルヌーイ テストは、「成功」と「失敗」という 2 つの結果が考えられる実験であることに注意してください。したがって、「成功」の確率がpの場合、「失敗」の確率はq=1-pです。
したがって、幾何学的分布は、実行されたすべての実験の成功確率であるパラメーターpに依存します。さらに、確率p はすべての実験で同じです。

負の二項分布
負の二項分布は、指定された数の肯定的な結果を得るために必要なベルヌーイ試行回数を表す確率分布です。
したがって、負の二項分布には 2 つの特徴的なパラメーターがあります。rは望ましい成功結果の数、 pは実行された各ベルヌーイ実験の成功確率です。

したがって、負の二項分布は、正の結果を得るために必要な数のベルヌーイ試行が実行されるプロセスを定義します。さらに、これらのベルヌーイ試行はすべて独立しており、成功の確率は一定です。
たとえば、負の二項分布に従う確率変数は、数字の 6 が 3 回振られるまでにサイコロを振らなければならない回数です。
超幾何分布
超幾何分布は、母集団からn 個の要素を置換せずにランダムに抽出した場合に成功したケースの数を表す確率分布です。
つまり、超幾何分布は、いずれも置換せずに母集団からn個の要素を抽出するときにx 個の成功が得られる確率を計算するために使用されます。
したがって、超幾何分布には 3 つのパラメーターがあります。
- N : は母集団内の要素の数です (N = 0、1、2、…)。
- K : 成功ケースの最大数です (K = 0、1、2、…、N)。超幾何分布では要素は「成功」または「失敗」としか考えられないため、 NKは失敗ケースの最大数です。
- n : は、実行される非置換フェッチの数です。

連続確率分布
連続確率分布は、小数値を含む間隔内の任意の値を取ることができる分布です。したがって、連続確率分布は連続確率変数の確率を定義します。
均一かつ連続的な分布
連続一様分布は、長方形分布とも呼ばれ、すべての値が同じ出現確率を持つ連続確率分布の一種です。換言すれば、連続一様分布とは、確率が区間にわたって一様に分布する分布である。
連続一様分布は、確率が一定である連続変数を記述するために使用されます。同様に、すべての結果が同じ確率を持つ場合、結果にランダム性があることを意味するため、連続一様分布はランダム プロセスを定義するために使用されます。
連続一様分布には、等確率区間を定義する 2 つの特性パラメーターaとbがあります。したがって、連続一様分布の記号はU(a,b)です。ここで、 aとbは分布の特性値です。

たとえば、ランダムな実験の結果が 5 から 9 までの任意の値をとり、考えられるすべての結果が同じ確率で発生する場合、実験は連続一様分布 U(5.9) でシミュレートできます。
正規分布
正規分布は連続確率分布であり、そのグラフは釣鐘型で平均に対して対称です。統計学では、正規分布は非常に異なる特性を持つ現象をモデル化するために使用されます。そのため、この分布は非常に重要です。
実際、統計学では、正規分布はすべての確率分布の中で最も重要な分布であると考えられています。正規分布は、現実世界の多数の現象をモデル化できるだけでなく、他のタイプの現象を近似するためにも使用できるためです。配布物。特定の条件下で。
正規分布の記号は大文字の N です。したがって、変数が正規分布に従うことを示すために、変数は文字 N で示され、その算術平均と標準偏差の値が括弧内に追加されます。

正規分布には、ガウス分布、ガウス分布、ラプラス ガウス分布など、さまざまな名前があります。
対数正規分布
対数正規分布、または対数正規分布 は、対数が正規分布に従う確率変数を定義する確率分布です。
したがって、変数 X が正規分布を持つ場合、指数関数 e x は対数正規分布になります。

対数は正の引数を 1 つだけ受け入れる関数であるため、対数正規分布は変数の値が正の場合にのみ使用できることに注意してください。
統計における対数正規分布のさまざまな用途の中で、この分布を金融投資の分析と信頼性分析の実行に使用することを区別します。
対数正規分布は、ティノー分布としても知られ、対数正規分布または対数正規分布とも呼ばれます。
カイ二乗分布
カイ二乗分布は、記号が χ² である確率分布です。より正確には、カイ二乗分布は、正規分布を持つk 個の独立確率変数の二乗の合計です。
したがって、カイ二乗分布にはk 個の自由度があります。したがって、カイ二乗分布は、それが表す正規分布変数の二乗和と同じくらいの自由度を持ちます。
![\displaystyle X\sim\chi^2_k \ \color{orange}\bm{\longrightarrow}\color{black}\ \begin{array}{l}\text{Distribuci\'on chi-cuadrado}\\[2ex]\text{con k grados de libertad}\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-9ea0bf7a87071883ceae5e419bae9e71_l3.png "Rendered by QuickLaTeX.com")
カイ二乗分布は、ピアソン分布としても知られています。
カイ二乗分布は、仮説検定や信頼区間などの統計的推論で広く使用されています。このタイプの確率分布がどのように応用されるかを以下で見ていきます。
学生の t 分布
スチューデントの t 分布は、統計で広く使用されている確率分布です。具体的には、スチューデントの t 分布はスチューデントの t 検定で使用され、2 つのサンプルの平均間の差を決定し、信頼区間を確立します。
スチューデントの t 分布は、統計学者ウィリアム シーリー ゴセットによって 1908 年に「スチューデント」という仮名で開発されました。
スチューデントの t 分布は、観測値の総数から 1 単位を減算することで得られる自由度の数によって定義されます。したがって、スチューデントの t 分布の自由度を決定する式はν=n-1です。
![\begin{array}{c}\nu=n-1\\[2ex]X\sim t_\nu\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-1c805dc2d6ca050feb70dad99de53402_l3.png "Rendered by QuickLaTeX.com")
スネデコール F ディストリビューション
スネデコール F 分布 は、フィッシャー・スネデコール F 分布または単にF 分布とも呼ばれ、統計的推論、特に分散分析で使用される連続確率分布です。
Snedecor F 分布の特性の 1 つは、自由度を示す 2 つの実数パラメーターmとnの値によって定義されることです。したがって、Snedecor 分布 F のシンボルはF m,nです。ここで、 mとnは分布を定義するパラメーターです。
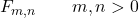
![\left.\begin{array}{c} X\sim \chi_m^2\\[2ex] Y\sim \chi_n^2\end{array}\right\}\color{orange}\bm{\longrightarrow}\color{black}\ F_{m,n}= \cfrac{X/m}{Y/n}](https://statorials.org/wp-content/ql-cache/quicklatex.com-d407869e61ca4357ffbcb40df3bd83ab_l3.png "Rendered by QuickLaTeX.com")
フィッシャー・スネデコール F 分布の名前は、イギリスの統計学者ロナルド フィッシャーとアメリカの統計学者ジョージ スネデコールに由来しています。
統計では、Fisher-Snedecor F 分布はさまざまな用途に使用できます。たとえば、Fisher-Snedecor F 分布はさまざまな線形回帰モデルを比較するために使用され、この確率分布は分散分析 (ANOVA) で使用されます。
指数分布
指数分布は、ランダム現象の発生の待ち時間をモデル化するために使用される連続確率分布です。
より正確には、指数分布により、ポアソン分布に従う 2 つの現象の間の待ち時間を記述することが可能になります。したがって、指数分布はポアソン分布と密接に関係しています。
指数分布には、ギリシャ文字 λ で表される特徴的なパラメーターがあり、特定の期間内に調査対象のイベントが発生すると予想される回数を示します。

同様に、指数分布は障害が発生するまでの時間をモデル化するためにも使用されます。したがって、指数分布は信頼性と生存理論においていくつかの用途があります。
ベータ版の配布
ベータ分布は、区間 (0,1) で定義され、2 つの正のパラメーター α と β によってパラメーター化された確率分布です。つまり、ベータ分布の値はパラメータαとβに依存します。
したがって、ベータ分布は、値が 0 から 1 までの連続確率変数を定義するために使用されます。
連続確率変数がベータ分布によって支配されることを示す表記法がいくつかありますが、最も一般的なものは次のとおりです。
![\begin{array}{c}X\sim B(\alpha,\beta)\\[2ex]X\sim Beta(\alpha,\beta)\\[2ex]X\sim \beta_{\alpha,\beta}\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-ee1d0d8a1624a017b8ef9ce8a67c694e_l3.png "Rendered by QuickLaTeX.com")
統計では、ベータ分布は非常に多様な用途に使用されます。たとえば、ベータ分布は、さまざまなサンプルのパーセンテージの変動を調べるために使用されます。同様に、プロジェクト管理では、Pert 分析を実行するためにベータ配布が使用されます。
ガンマ分布
ガンマ分布は、 2 つの特性パラメータ α と λ によって定義される連続確率分布です。言い換えれば、ガンマ分布は 2 つのパラメータの値に依存します。α は形状パラメータ、λ はスケール パラメータです。
ガンマ分布の記号はギリシャ文字の大文字 Γ です。したがって、確率変数がガンマ分布に従う場合、次のように記述されます。

ガンマ分布は、形状パラメーター k = α と逆スケール パラメーター θ = 1/λ を使用してパラメーター化することもできます。すべての場合において、ガンマ分布を定義する 2 つのパラメーターは正の実数です。
通常、ガンマ分布は右に歪んだデータセットをモデル化するために使用されるため、プロットの左側にデータが集中します。たとえば、ガンマ分布は電気コンポーネントの信頼性をモデル化するために使用されます。
ワイブル分布
ワイブル分布は、形状パラメーター α とスケール パラメーター λ の 2 つの特性パラメーターによって定義される連続確率分布です。
統計学では、ワイブル分布は主に生存分析に使用されます。同様に、ワイブル分布にはさまざまな分野で多くの応用例があります。

著者らによると、ワイブル分布は 3 つのパラメータでパラメータ化することもできます。次に、分布グラフが始まる横座標を示す、しきい値と呼ばれる 3 番目のパラメーターが追加されます。
ワイブル分布は、1951 年に詳細に説明したスウェーデン人のワロッディ ワイブルにちなんで命名されました。ただし、ワイブル分布は 1927 年にモーリス フレシェによって発見され、1933 年にロジンとラムラーによって初めて適用されました。
パレート分布
パレート分布は、パレートの法則をモデル化するために統計で使用される連続確率分布です。したがって、パレート分布は、出現確率が残りの値よりもはるかに高いいくつかの値を持つ確率分布です。
パレートの法則は 80-20 の法則とも呼ばれ、現象の原因のほとんどは人口のごく一部によるものであるという統計原則であることを思い出してください。
パレート分布には、スケール パラメーター x mと形状パラメーター α という 2 つの特徴的なパラメーターがあります。

元々、パレート分布は人口内の富の分布を表すために使用されていました。なぜなら、その大部分は人口の少数の割合によるものだったからです。しかし現在、パレート分布は、品質管理、経済学、科学、社会分野など、多くの用途に応用されています。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る