サンプリング方法の種類 (例付き)
研究者は多くの場合、次のような 集団に関する質問に答えたいと考えています。
- 特定の植物種の平均高さはどれくらいですか?
- 特定の種類の鳥の平均体重はどれくらいですか?
- 特定の都市の住民の何パーセントが特定の法律を支持していますか?
これらの質問に答える 1 つの方法は、対象となる母集団の各個人に関するデータを収集することです。
ただし、これには通常、費用と時間がかかりすぎるため、研究者は代わりに母集団のサンプルを採取し、そのサンプルデータを使用して母集団全体についての結論を導き出します。
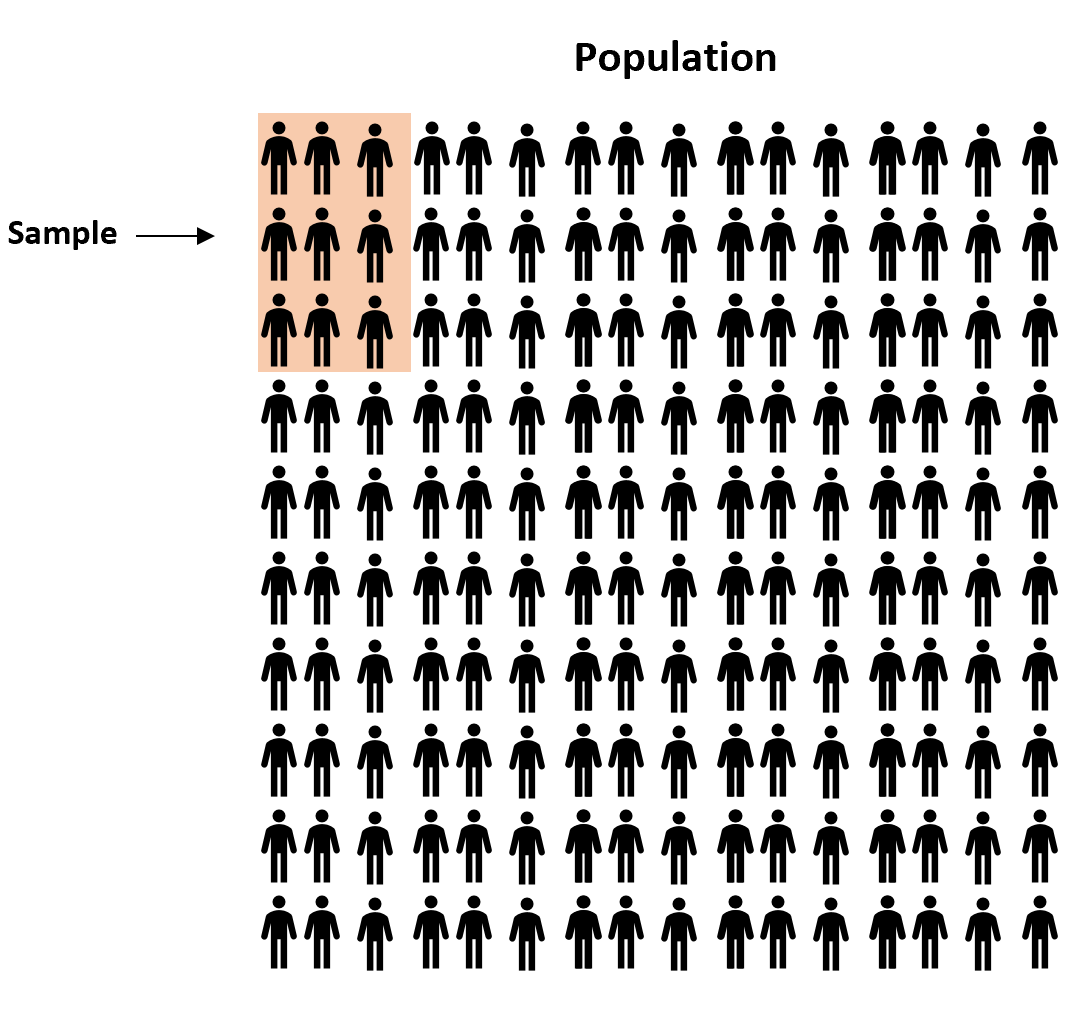
研究者が個人をサンプルに入れるために使用できる可能性のあるさまざまな方法が多数あります。これらはサンプリング方法として知られています。
この記事では、統計で最も一般的に使用されるサンプリング方法と、さまざまな方法の長所と短所を紹介します。
確率サンプリング法
サンプリング法の最初のクラスは、確率サンプリング法として知られています。これは、母集団の各メンバーがサンプル内に選択される確率が等しいためです。
単純なランダムサンプル
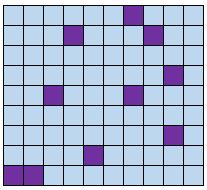
定義:母集団の各メンバーは、サンプルの一部として選択される平等なチャンスを持っています。乱数発生器またはランダム選択手段を使用してメンバーをランダムに選択します。
例:クラスの各生徒の名前を帽子の中に入れ、その名前をランダムに描画して生徒のサンプルを取得します。
利点:単純な無作為サンプルは、各メンバーがサンプルに含まれる確率が等しいため、通常、対象となる母集団を代表します。
層別ランダムサンプル
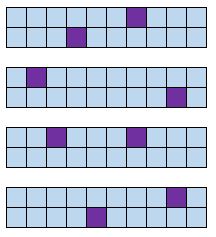
定義:集団をグループに分けること。各グループから数人のメンバーをサンプルの一部としてランダムに選択します。
例:学校の全生徒をレベルに従って、1 年生、2 年生、3 年生、4 年生に分けます。各学年 50 人の生徒に学校給食に関するアンケートに答えてもらいます。
利点:階層化された無作為サンプルにより、各母集団グループのメンバーが調査に確実に含まれるようになります。
クラスター化されたランダムサンプル
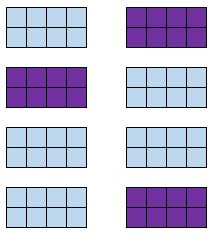
定義:集団をクラスターに分割すること。いくつかのクラスターをランダムに選択し、これらのクラスターのすべてのメンバーをサンプルに含めます。
例:ホエールウォッチングツアーを提供している会社は、顧客にアンケートをとろうとしています。 1 日に提供する 10 件のツアーの中からランダムに 4 件を選択し、各顧客に体験について尋ねます。
利点:クラスターのランダム サンプルは、特定のグループのすべてのメンバーを収集します。これは、各グループが母集団全体を反映している場合に役立ちます。
体系的なランダムサンプリング
![]()
定義:母集団の各メンバーを特定の順序で配置します。ランダムな開始点を選択し、サンプルの一部となるメンバーをn 番目ごとに選択します。
例:教師は生徒を姓のアルファベット順に並べ、開始点をランダムに選択し、サンプルに含める生徒を 5 人ごとに選択します。
利点:系統的無作為サンプルは、各メンバーがサンプルに含まれる確率が等しいため、一般に対象となる母集団を代表します。
非確率サンプリング法
別のクラスのサンプリング方法は、非確率サンプリング方法として知られています。これは、母集団のすべてのメンバーがサンプルに選択される確率が同じであるわけではないためです。
このタイプのサンプリング方法は、確率サンプリング方法よりもはるかに安価で実用的であるため、時々使用されます。これは、研究者が母集団についての初期理解を単に得たい場合に、探索的分析中によく使用されます。
ただし、これらのサンプリング方法から得られたサンプルは、一般に代表的なサンプルではないため、抽出元の母集団についての結論を引き出すために使用することはできません。
便利なサンプル
定義:サンプルに含めるために、母集団の容易に利用可能なメンバーを選択すること。
例:研究者は日中図書館の前に立って、通行人にインタビューします。
短所:場所と時間帯が結果に影響します。一部の人々 (日中働いている人など) はサンプルに示されているとおりではないため、サンプルは過少カウントのバイアスを受ける可能性が高くなります。
自主回答サンプル
定義:研究者はボランティアに研究に参加するよう依頼し、集団のメンバーはサンプルに含めるかどうかを自発的に決定します。
例:ラジオの司会者は、リスナーにオンラインにアクセスし、Web サイトでアンケートに回答するよう求めます。
短所: 自発的に回答する人々は、残りの人口よりも強い意見 (肯定的または否定的) を持っている可能性が高く、代表的ではないサンプルになります。このサンプリング方法を使用すると、サンプルは無回答バイアスを受ける可能性が高くなります。つまり、特定のグループの人々が単に回答を提供する可能性が低くなります。
雪だるまのサンプル
定義:研究者は、研究に参加する最初の被験者を募集し、その後、それらの最初の被験者に研究に参加する追加の被験者を募集するように依頼します。このアプローチを使用すると、追加の被験者がさらに多くの被験者を募集するたびに、サンプル サイズが「雪だるま式」に大きくなります。
例:研究者は希少疾患に罹患している人に関する研究を行っていますが、実際にその疾患に罹患している人を見つけるのは困難です。ただし、最初に研究に参加してくれる人を数名だけ見つけることができた場合は、民間の支援グループやその他の手段を通じて、知り合いかもしれない他の人を募集するよう依頼することができます。
短所:サンプリングバイアスが発生しやすい。最初の被験者は追加の被験者を募集するため、多くの被験者が、調査対象となるより広範な集団を代表していない可能性がある同様の特性や特性を共有する可能性があります。したがって、サンプルの結果を母集団に外挿することはできません。
雪だるま式サンプリングの詳細については、こちらをご覧ください。
純粋なサンプル
定義:研究者は、研究の目的に最も役立つと思われる人物に基づいて個人を採用します。
例:研究者は、町の広場に新しいクライミング ジムを設置する可能性について、町の住民の意見を知りたいと考えています。そこで彼らは、市内の他のクライミングジムに頻繁に通う人を意図的に探している。
短所:サンプル内の個人が母集団全体を代表しているとは考えられません。したがって、サンプルの結果を母集団に外挿することはできません。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る