デシジョン ツリーとランダム フォレスト: 違いは何ですか?
決定木は、一連の予測変数と応答変数の間の関係が非線形である場合に使用される機械学習モデルの一種です。
デシジョン ツリーの背後にある基本的な考え方は、デシジョン ルールを使用して応答変数の値を予測する一連の予測子変数を使用して「ツリー」を構築することです。
たとえば、予測変数「出場年数」と「平均本塁打」を使用して、プロ野球選手の年俸を予測できます。
このデータセットを使用すると、デシジョン ツリー モデルは次のようになります。
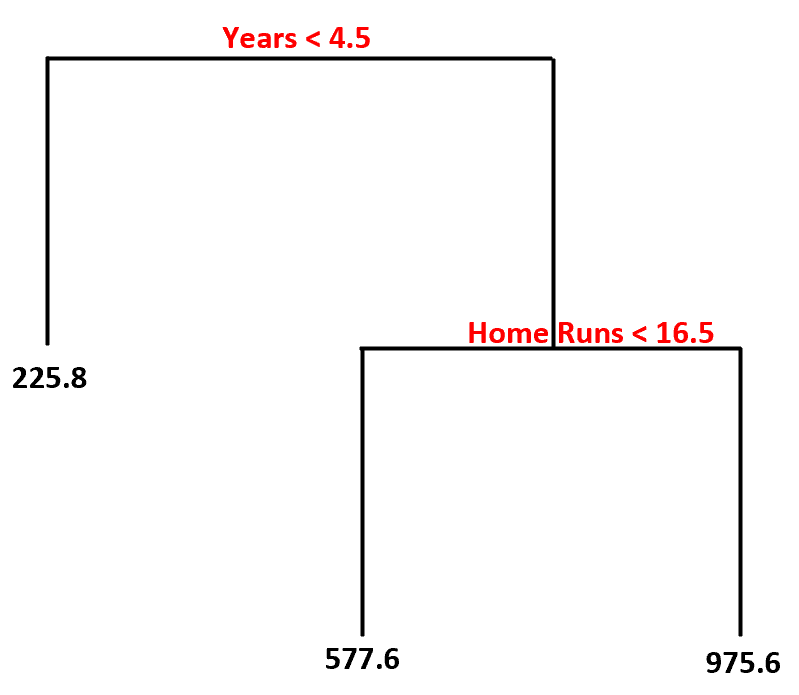
この決定木をどのように解釈するかは次のとおりです。
- プレー歴が 4.5 年未満の選手の予想年俸は225,000 ドルです。
- 4年半以上プレーし、平均本塁打数が16.5本未満の選手の予想年俸は57万7,600ドルです。
- 4.5 年以上の経験と平均 16.5 本塁打以上の選手の予想年俸は97 万 5,600 ドルです。
デシジョン ツリーの主な利点は、データ セットに迅速に適応でき、上記のような「ツリー」図を使用して最終モデルを明確に視覚化して解釈できることです。
主な欠点は、デシジョン ツリーがトレーニング データセットに過剰適合する傾向があることです。つまり、目に見えないデータではパフォーマンスが低下する可能性が高くなります。これは、データセット内の外れ値によっても大きく影響される可能性があります。
デシジョン ツリーの拡張は、ランダム フォレストとして知られるモデルであり、本質的にはデシジョン ツリーのセットです。
ランダム フォレスト モデルを作成するために使用する手順は次のとおりです。
1.元のデータセットからブートストラップされたサンプルを取得します。
2.ブートストラップ サンプルごとに、予測子変数のランダムなサブセットを使用して決定木を作成します。
3.各ツリーからの予測を平均して、最終モデルを取得します。
ランダム フォレストの利点は、目に見えないデータに対してデシジョン ツリーよりもはるかに優れたパフォーマンスを発揮する傾向があり、外れ値が発生しにくいことです。
ランダム フォレストの欠点は、最終モデルを視覚化する方法がなく、十分なコンピューティング能力がない場合、または作業しているデータセットが非常に大きい場合、モデルの構築に時間がかかる可能性があることです。
長所と短所: デシジョン ツリー vs.ランダムフォレスト
次の表は、ランダム フォレストと比較したデシジョン ツリーの長所と短所をまとめたものです。
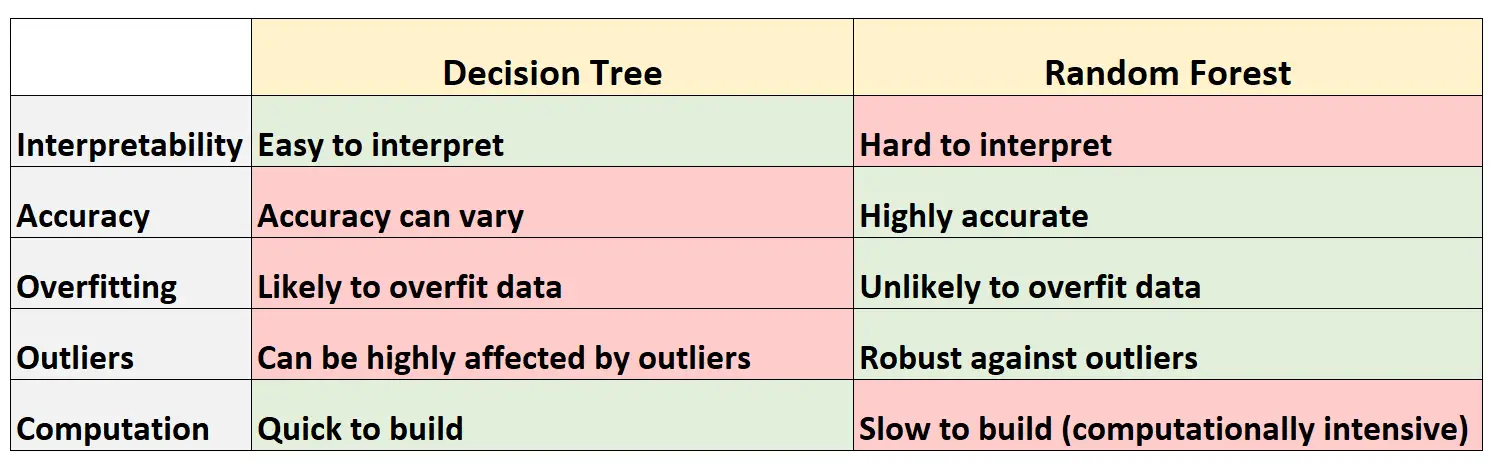
テーブルの各行の簡単な説明は次のとおりです。
1. 解釈可能性
最終モデルを視覚化して理解するための樹形図を作成できるため、デシジョン ツリーは解釈が簡単です。
逆に、ランダム フォレストを視覚化することはできず、最終的なランダム フォレスト モデルがどのように意思決定を行うかを理解することが難しい場合があります。
2. 精度
デシジョン ツリーはトレーニング データセットに過剰適合する可能性が高いため、目に見えないデータセットではパフォーマンスが低下する傾向があります。
逆に、ランダム フォレストはトレーニング データセットの過剰適合を回避するため、目に見えないデータセットに対して非常に正確になる傾向があります。
3. 過学習
前述したように、デシジョン ツリーはトレーニング データにオーバーフィットすることがよくあります。これは、実際の基礎となるモデルとは対照的に、デシジョン ツリーがデータセットの「ノイズ」に適応する可能性が高いことを意味します。
逆に、ランダム フォレストは特定の予測変数のみを使用して個別の決定木を構築するため、最終的な木は修飾される傾向があり、これはランダム フォレスト モデルがデータ セットを過剰適合する可能性が低いことを意味します。
4. 外れ値
決定木は外れ値の影響を非常に受けやすくなります。
逆に、ランダム フォレスト モデルは多数の個別のデシジョン ツリーを構築し、それらのツリーからの予測の平均を取るため、外れ値の影響を受ける可能性ははるかに低くなります。
5. 計算
デシジョン ツリーはデータセットに迅速に適応できます。
逆に、ランダム フォレストは計算量がはるかに多く、データセットのサイズによっては作成に時間がかかることがあります。
デシジョン ツリーまたはランダム フォレストをいつ使用するか
一般的に:
非線形モデルを迅速に作成し、モデルがどのように意思決定を行うかを簡単に解釈できるようにしたい場合は、デシジョン ツリーを使用する必要があります。
ただし、大量の計算能力があり、モデルの解釈方法を気にせずに非常に正確である可能性が高いモデルを作成したい場合は、ランダム フォレストを使用する必要があります。
現実の世界では、機械学習エンジニアやデータ サイエンティストは、ランダム フォレストをよく使用します。これは、ランダム フォレストが非常に正確であり、最新のコンピューターやシステムが以前は処理できなかった大規模なデータ セットを処理できることが多いためです。
追加リソース
次のチュートリアルでは、デシジョン ツリーとランダム フォレスト モデルの概要を説明します。
次のチュートリアルでは、R でデシジョン ツリーとランダム フォレストを適合させる方法について説明します。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る