Pandasで列値の分布をプロットする方法
次のメソッドを使用して、pandas DataFrame の列値の分布をプロットできます。
方法 1: 列内の値の分布をプロットする
df[' my_column ']. plot (kind=' kde ')
方法 2: 1 つの列の値の分布を別の列でグループ化してプロットする
df. groupby (' group_column ')[' values_column ']. plot (kind=' kde ')
次の例は、次の pandas DataFrame で各メソッドを実際に使用する方法を示しています。
import pandas as pd #createDataFrame df = pd. DataFrame ({' team ': ['A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B'], ' points ': [3, 3, 4, 5, 4, 7, 7, 7, 10, 11, 8, 7, 8, 9, 12, 12, 12, 14, 15, 17]}) #view DataFrame print (df) team points 0 to 3 1 to 3 2 to 4 3 to 5 4 to 4 5 TO 7 6 to 7 7 to 7 8 to 10 9 to 11 10 B 8 11 B 7 12 B 8 13 B 9 14 B 12 15 B 12 16 B 12 17 B 14 18 B 15 19 B 17
例 1: 列内の値の分布をプロットする
次のコードは、ポイント列の値の分布をプロットする方法を示しています。
#plot distribution of values in points column df[' points ']. plot (kind=' kde ')
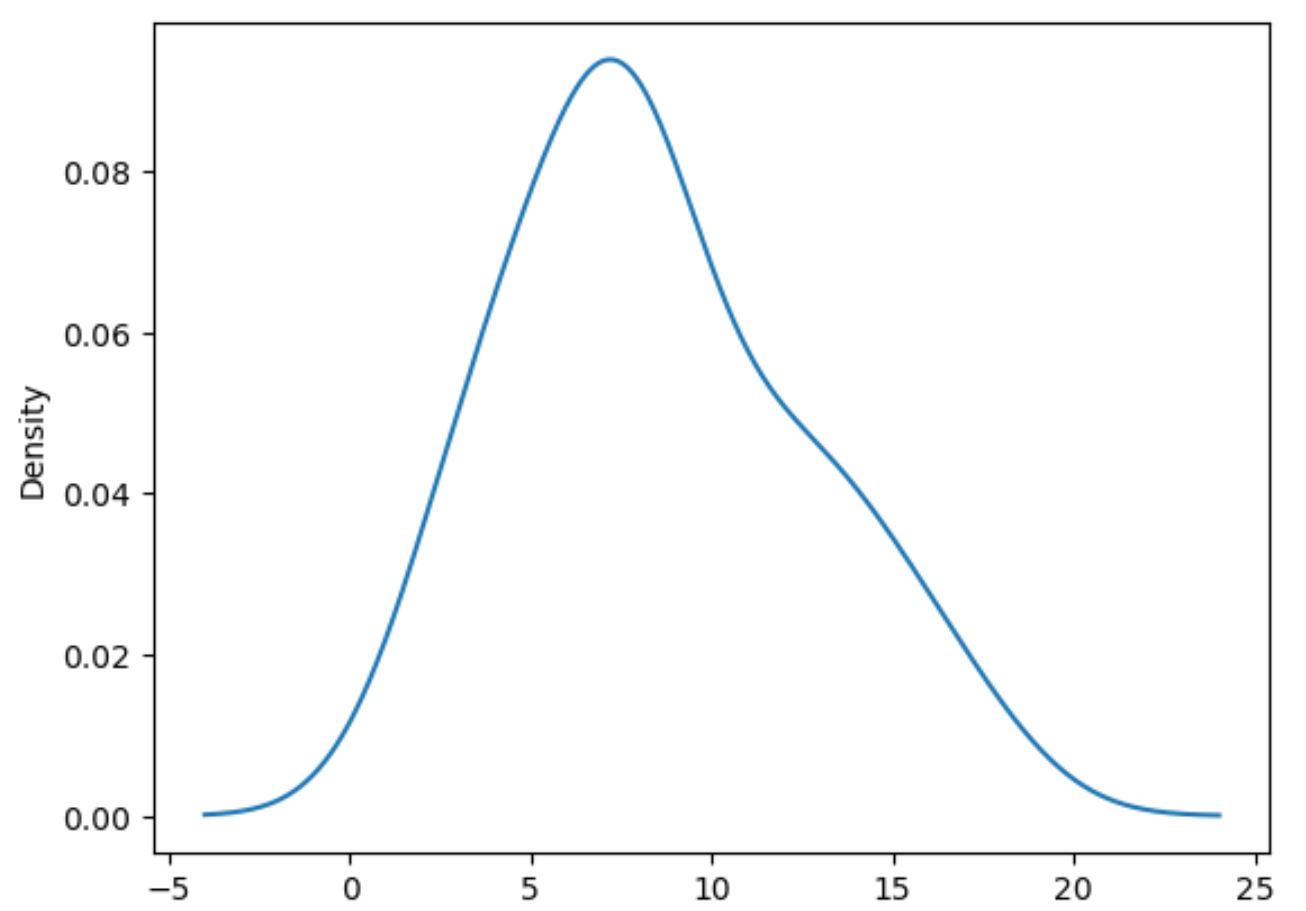
kind=’kde’ は、変数の値の分布を要約する滑らかな曲線を生成するカーネル密度推定を使用するように pandas に指示することに注意してください。
代わりにヒストグラムを作成したい場合は、次のようにkind=’hist’を指定できます。
#plot distribution of values in points column using histogram df[' points ']. plot (kind=' hist ', edgecolor=' black ')
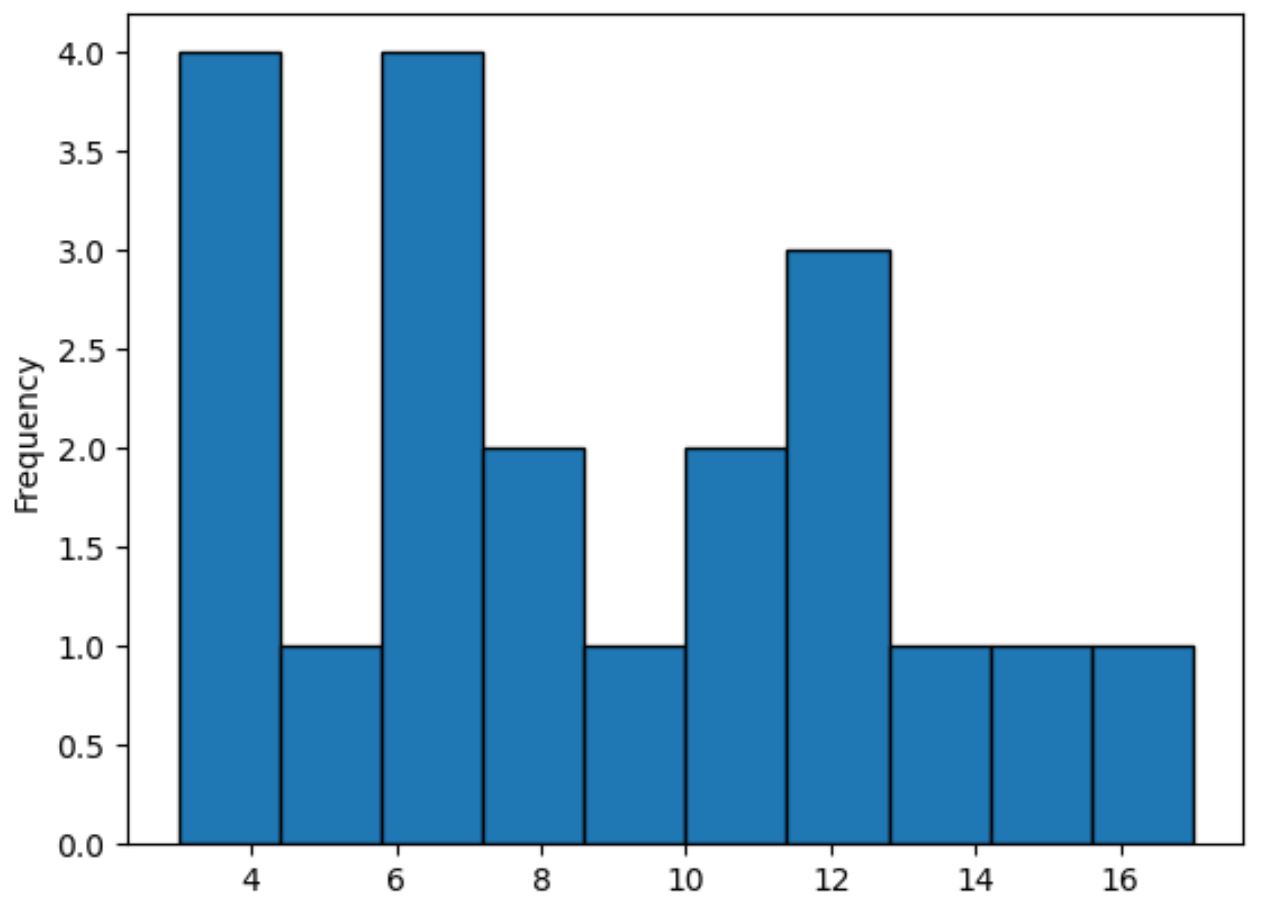
この方法では、分布の形状を要約する滑らかな線ではなく、棒を使用して点の列内の値の頻度を表します。
例 2: 1 つの列の値の分布を別の列でグループ化してプロットする
次のコードは、チーム列ごとにグループ化されたポイント列の値の分布をプロットする方法を示しています。
import matplotlib.pyplot as plt #plot distribution of points by team df. groupby (' team ')[' points ']. plot (kind=' kde ') #add legend plt. legend ([' A ',' B '], title=' Team ') #add x-axis label plt. xlabel (' Points ')
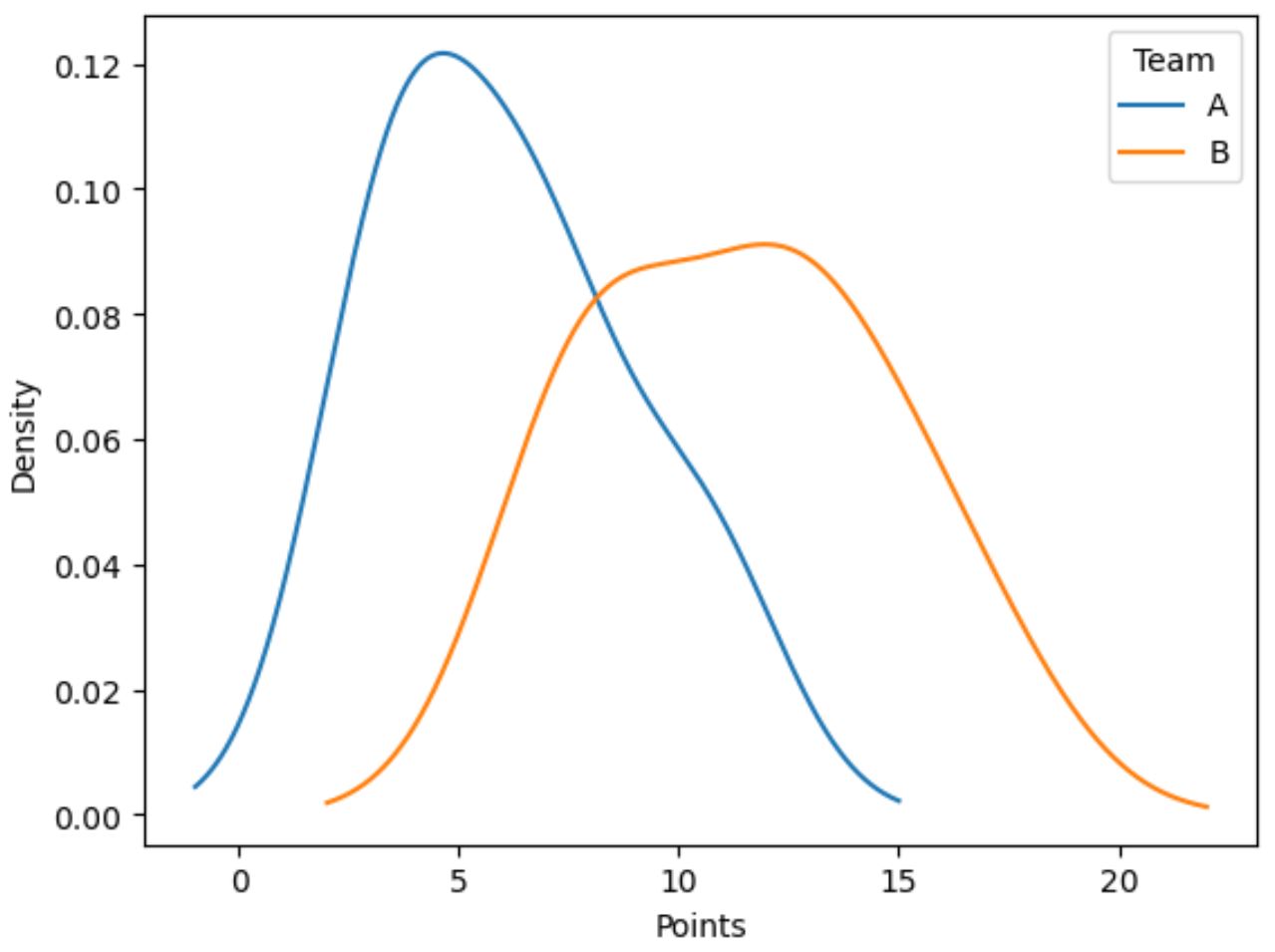
青い線はチーム A の選手のポイント分布を示し、オレンジ色の線はチーム B の選手のポイント分布を示します。
追加リソース
次のチュートリアルでは、パンダで他の一般的なタスクを実行する方法を説明します。
Pandas でプロットにタイトルを追加する方法
パンダプロットの図のサイズを調整する方法
複数の Pandas DataFrame をサブプロットにプロットする方法
Pandas でプロット凡例を作成およびカスタマイズする方法
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る