Stata で対応のあるサンプルの t 検定を実行する方法
対のあるサンプルの t 検定は、一方のサンプルの各観測値がもう一方のサンプルの観測値と関連付けられる場合に、2 つのサンプルの平均を比較するために使用されます。
このチュートリアルでは、Stata で対応のあるサンプルの t 検定を実行する方法を説明します。
例: Stata での対応のあるサンプルの t 検定
研究者は、新しい燃料処理によって特定の車の平均 mpg が変化するかどうかを知りたいと考えています。これをテストするために、燃料処理を行った場合と行わない場合の 12 台の車の燃費を測定する実験を実施しました。
各車が処理を受けるため、各車をそれ自体とペアにするペア t 検定を実行して、燃料処理の有無で平均 mpg に違いがあるかどうかを判断できます。
Stata で対応のある t 検定を実行するには、次の手順を実行します。
ステップ 1: データをロードします。
まず、コマンド ボックスにuse https://www.stata-press.com/data/r13/fuelと入力し、Enter をクリックしてデータをロードします。
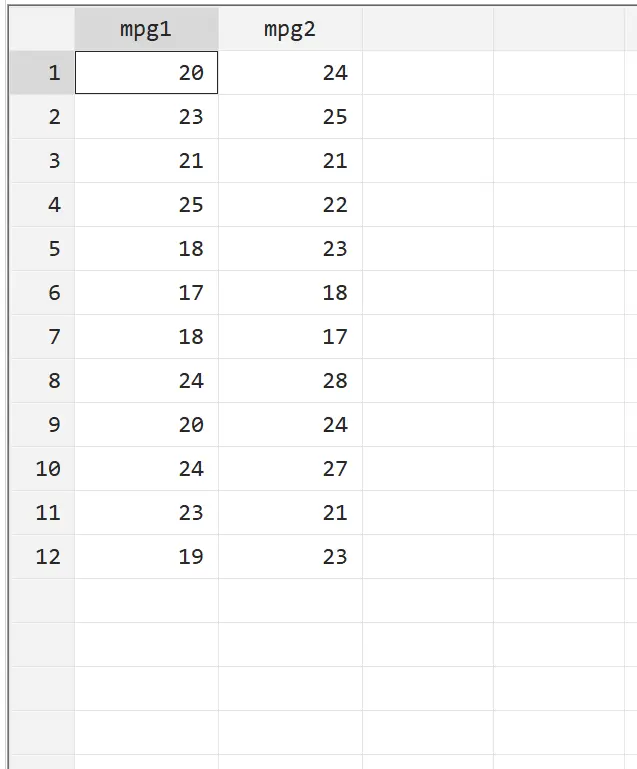
ステップ2: 生データを表示します。
対応のある t 検定を実行する前に、まず生データを見てみましょう。上部のメニュー バーから、 [データ] > [データ エディター] > [データ エディター (参照)]に移動します。最初の列mpg1には燃料処理なしの最初の車の mpg が表示され、2 番目の列mpg2には燃料処理された 1 台目の車の mpg が表示されます。
ステップ 3: 対応のある t 検定を実行します。
上部のメニュー バーから、 [統計] > [要約、表、検定] > [従来の仮説検定] > [t 検定 (平均値検定の比較)]に移動します。
ペアリングを選択します。 [最初の変数] には、 mpg1を選択します。 2 番目の変数として、 mpg2を選択します。 [信頼レベル] で、必要なレベルを選択します。値 95 は、有意水準 0.05 に対応します。これは 95 のままにしておきます。最後に、 [OK]をクリックします。
対応のある t 検定の結果が表示されます。
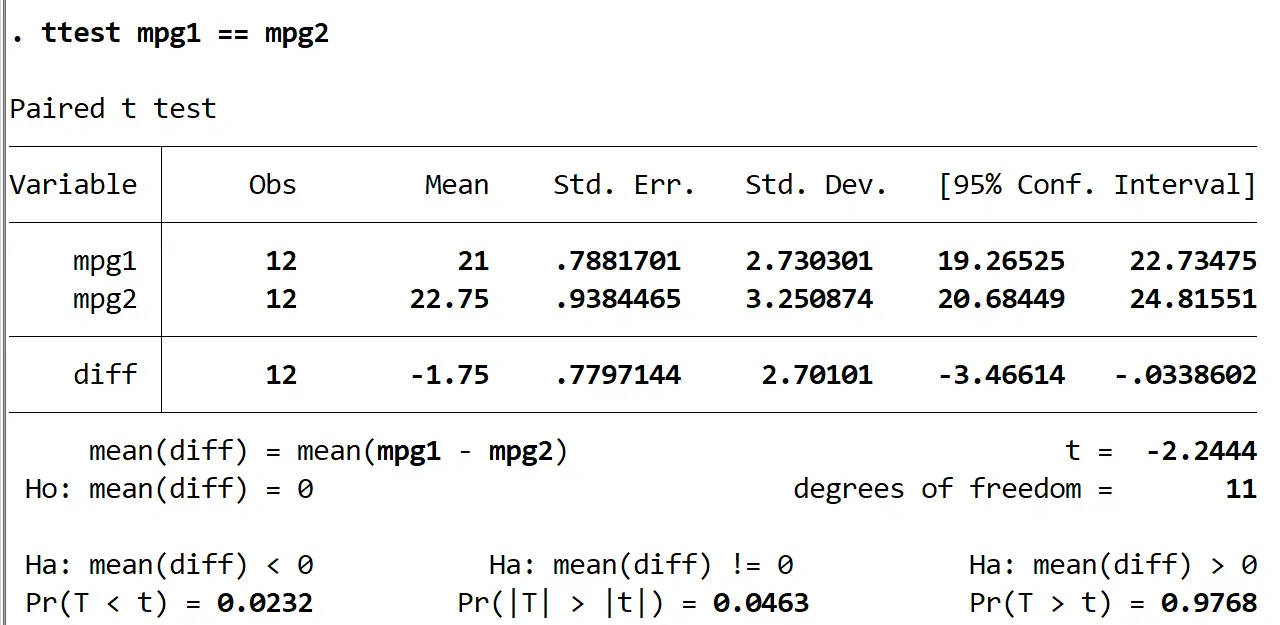
各グループについて次の情報を受け取ります。
Obs:観測値の数。各グループには 12 個の観測値があります。
平均:平均 mpg。グループ 0 の平均は 21 です。グループ 1 の平均は 22.75 です。
標準。 Err:標準誤差、σ / √ nとして計算されます。
標準。 Dev: mpg の標準偏差。
95%の確信範囲:真の母集団平均の 95% 信頼区間 (mpg)。
t:対応のある t 検定の検定統計量。
自由度:テストに使用する自由度。次のように計算されます: #pairs-1 = 12-1 = 11。
3 つの異なる 2 サンプル t 検定の p 値が結果の下部に表示されます。平均 mpg が 2 つのグループ間で単に異なるかどうかを理解したいため、p 値が0.0463 である中間検定 (対立仮説は Ha:diff !=0) の結果を調べます。 。
この値は有意水準 0.05 を下回っているため、帰無仮説を棄却します。真の平均mpgが2つのグループ間で異なると言える十分な証拠があります。
ステップ 5: 結果を報告します。
最後に、対応のある t 検定の結果を報告します。これを行う方法の例を次に示します。
新しい燃料処理によってガロンあたりの平均マイル数に違いが生じるかどうかを判断するために、12 台の車に対して対応のある t 検定が実行されました。
結果は、平均 mpg が統計的に有意であることを示しました。 有意水準 0.05 で 2 つのグループ間の差 (t = -2.2444、df=11、p = 0.0463)。
母平均間の真の差の 95% 信頼区間は、区間 (-3.466, -0.034) となりました。
これらの結果に基づくと、新しい燃料処理により、自動車の mpg が統計的に大幅に向上します。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る