不均一分散性
この記事では、統計における不均一分散性とは何かについて説明します。さらに、不均一分散の原因、その結果、およびその修正方法もわかります。
不均一分散性とは何ですか?
統計学における不均一分散性は、誤差の分散が一定ではないことを意味する回帰パターンを示す特性です。言い換えれば、不均一分散モデルとは、その誤差が不規則な分散を持つことを意味し、その場合、そのモデルは不均一分散モデルと呼ばれます。
誤差 (または残差) は、実際の値と回帰モデルによって推定された値の差として定義されることに注意してください。

回帰モデルを構築するとき、各観測値によって生じる誤差は、前の式を使用して計算されます。したがって、計算された誤差の分散が観測全体を通じて一定ではなく、むしろ変化する場合、統計モデルは不均一分散になります。
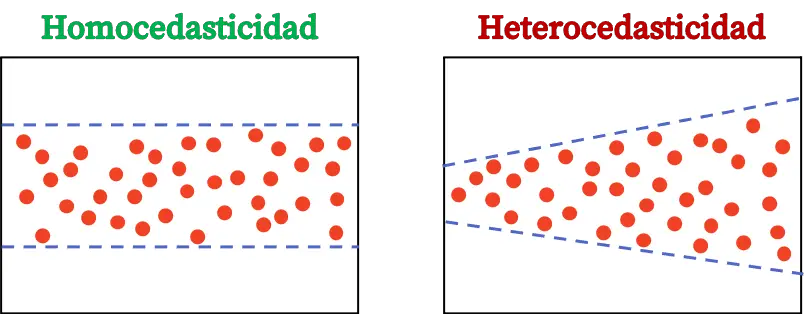
非常に単純に見えるかもしれませんが、回帰モデルが不均一分散性を示さないことが重要です。これは、モデルの計算は残差の分散が一定であるという事実に基づいており、実際、それは以前の仮定の 1 つであるためです。回帰モデル。
White 検定や Goldfeld-Quandt 検定など、不均一分散性を検出できる特定の統計検定があります。ただし、通常は残差をグラフ化することで、その不均一分散性を特定できます。
不均一分散の原因
モデルの不均一分散性の最も一般的な原因は次のとおりです。
- データ範囲が平均と比較して非常に広い場合。同じ統計サンプルに非常に大きな値と非常に小さな値がある場合、得られた回帰モデルは不均一分散である可能性があります。
- 回帰モデルで変数を省略すると、不均一分散が生じます。論理的には、関連する変数がモデルに含まれていない場合、その変動は残差に含まれることになり、これは必ずしも固定されるわけではありません。
- 同様に、構造が変化するとモデルのデータセットへの適合が不十分になる可能性があり、そのため残差の分散が一定にならない可能性があります。
- 一部の変数の値が他の説明変数よりもはるかに大きい場合、モデルには不均一分散性がある可能性があります。この場合、変数を相対化して問題を解決できます。
ただし、一部のケースでは、本質的に不均一分散性を示す可能性があります。たとえば、人の収入を食費でモデル化すると、裕福な人は貧しい人よりも食費の変動がはるかに大きくなります。なぜなら、常に安いレストランで食事をする貧しい人とは異なり、金持ちは高いレストランで食事をすることもあれば、安いレストランで食事をすることもあります。したがって、回帰モデルは不均一分散性を持ちやすいです。
不均一分散性の結果
主に、回帰モデルにおける不均一分散性の結果は次のとおりです。
- 誤差の二乗の平均として定義される最小二乗推定量では効率が失われます。
- 最小二乗推定器の共分散行列の計算でエラーが発生します。
不均一分散性を修正する
結果の回帰モデルが不均一分散である場合、不均一分散を得るために次の修正を試みることができます。
- 独立変数の自然対数を計算します。これは一般に、グラフ内で残差の分散が増加する場合に役立ちます。
- 残差プロットによっては、独立変数の別のタイプの変換の方がより現実的である場合があります。たとえば、グラフが放物線の形状である場合、独立変数の二乗を計算し、その変数をモデルに追加できます。
- 他の変数もモデルに使用できます。変数を削除または追加することにより、残差の分散を変更できます。
- 最小二乗基準を使用する代わりに、加重最小二乗基準を使用できます。
不均一分散性と等分散性
最後に、統計における不均一分散性と均一分散性の違いについて説明します。これらは回帰モデルの 2 つの概念であることを明確にしておく必要があるためです。
回帰モデルの等分散性は、誤差の分散が一定であることを示す統計的特性です。したがって、等分散モデルは、その誤差の分散が一定であることを意味します。
不均一分散性と等分散性の違いは、残差の分散の一定性に見られます。モデルの残差の分散が一定でない場合、それはモデルが不均一分散であることを意味します。一方、残差の分散が一定である場合、これは等分散性であることを意味します。
したがって、構築する回帰モデルが等分散であることを確認する必要があります。こうすることで、残差の分散が一定であるという仮定が満たされます。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る