Stata で単純な線形回帰を実行する方法
単純線形回帰は、説明変数 x と応答変数 y の関係を理解するために使用できる方法です。
このチュートリアルでは、Stata で単純な線形回帰を実行する方法を説明します。
例: Stata での単純線形回帰
車の重量とガロンあたりのマイル数の関係を理解したいとします。この関係を調べるために、重量を説明変数として、ガロンあたりのマイル数を応答変数として使用して、単純な線形回帰を実行できます。
Stata で次の手順を実行して、74 台の異なる車のデータが含まれるautoというデータセットを使用して単純な線形回帰を実行します。
ステップ 1: データをロードします。
コマンド ボックスに次のように入力してデータをロードします。
https://www.stata-press.com/data/r13/auto を使用してください
ステップ 2: データの概要を取得します。
コマンド ボックスに次のように入力すると、作業しているデータをすばやく理解できます。
要約する
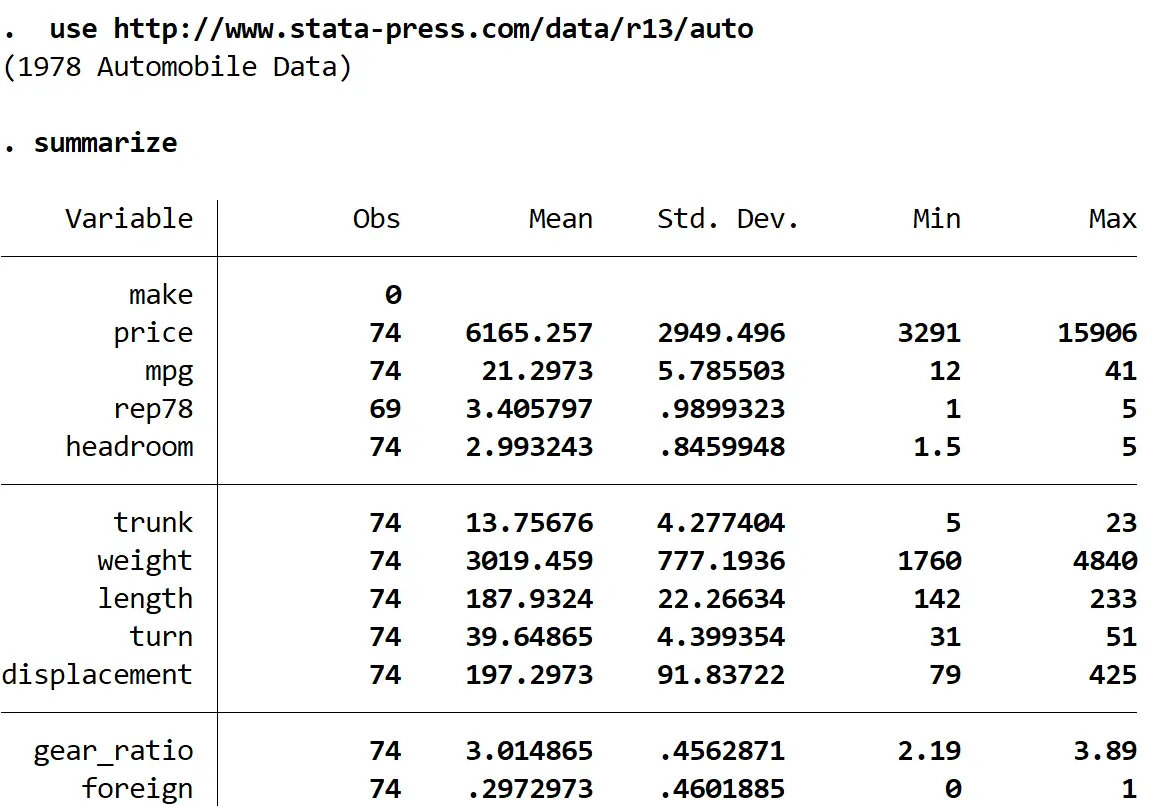
データセットには 12 の異なる変数があることがわかりますが、注目するのはmpgとweight の2 つだけです。
ステップ 3: データを視覚化します。
単純な線形回帰を実行する前に、まず重量と mpg の散布図を作成して、これら 2 つの変数間の関係を視覚化し、明らかな外れ値をチェックできるようにしましょう。コマンド ボックスに次のように入力して散布図を作成します。
mpg重量分散
これにより、次の散布図が生成されます。
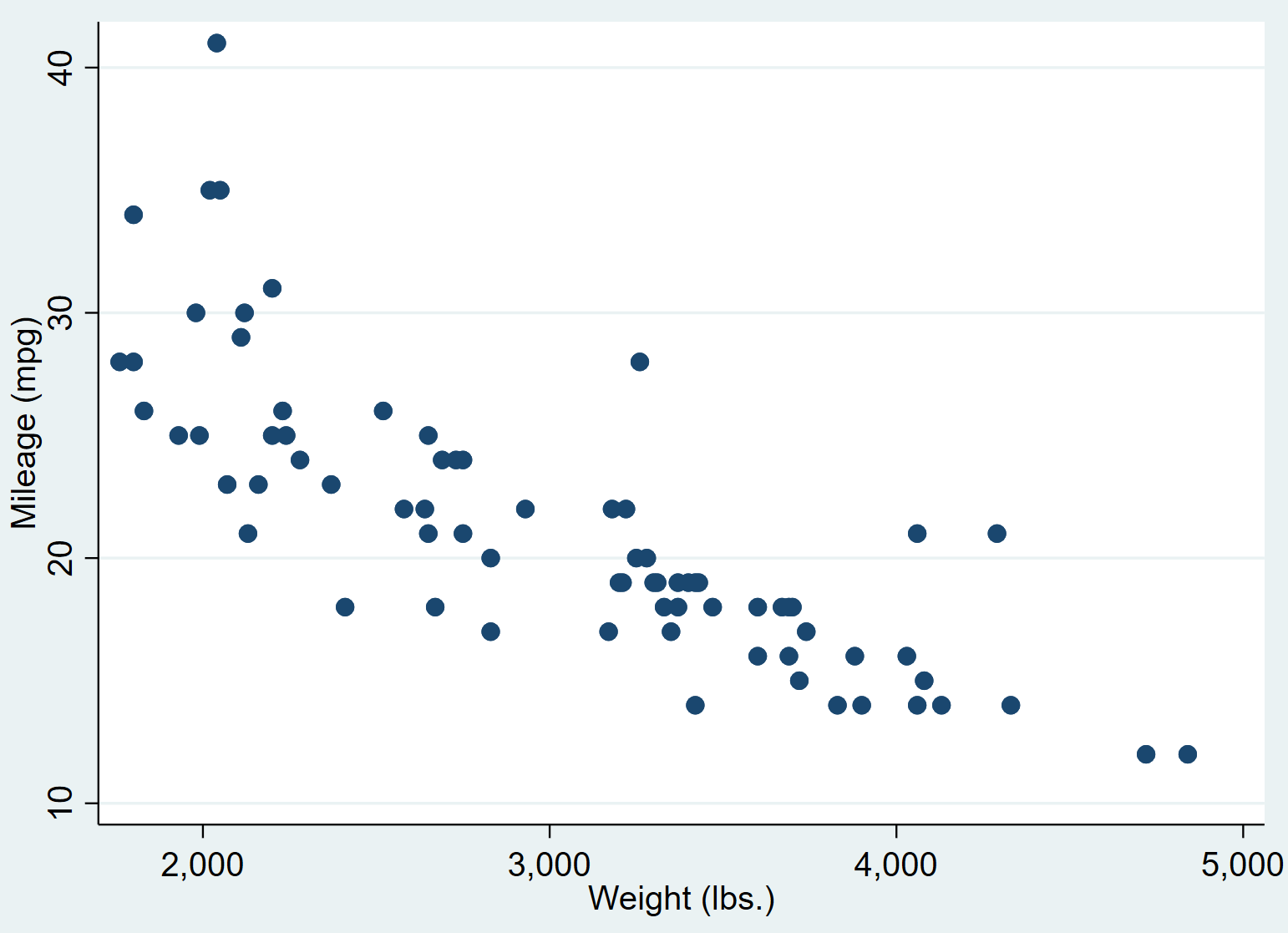
重量が重い車ほど、ガロンあたりの走行距離が少なくなる傾向があることがわかります。この関係を定量化するために、単純な線形回帰を実行します。
ステップ 4: 単純な線形回帰を実行します。
コマンド ボックスに次のように入力し、説明変数として重み、応答変数として mpg を使用して単純な線形回帰を実行します。
重量をmpgに回帰する
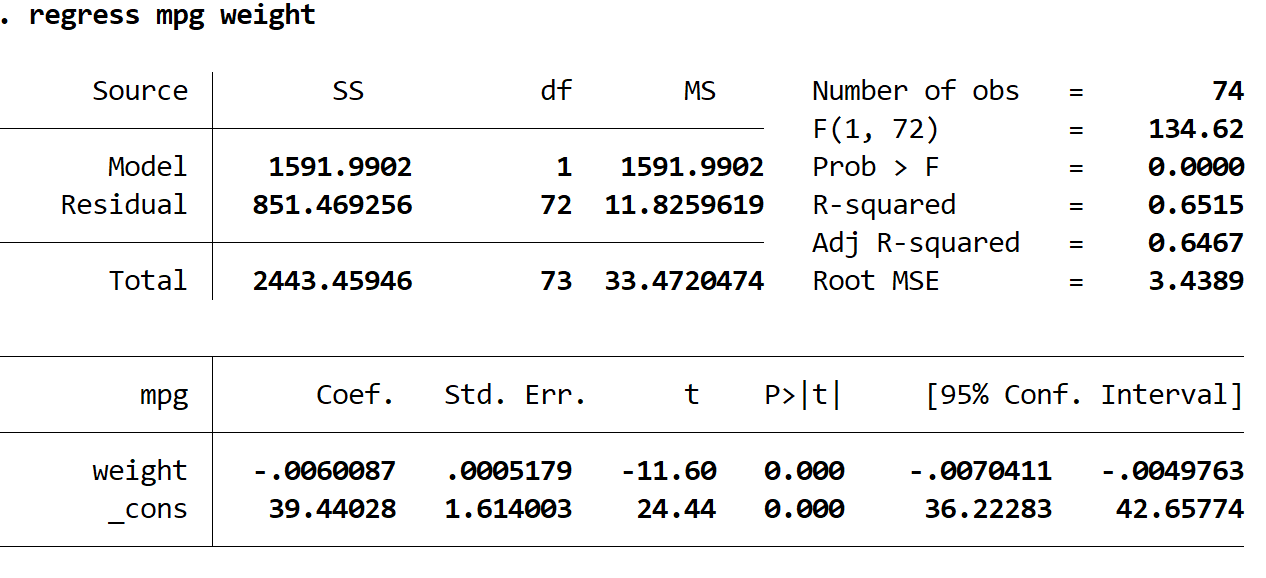
結果内の最も興味深い数値を解釈する方法は次のとおりです。
R二乗: 0.6515。これは、説明変数によって説明できる応答変数の分散の割合です。この例では、mpg の変動の 65.15% は重量で説明できます。
係数 (重み): -0.006。これにより、説明変数の 1 単位の増加に伴う応答変数の平均変化がわかります。この例では、体重が 1 ポンド増加するごとに、平均で 0.006 mpg の減少が伴います。
係数 (_cons): 39.44028。これにより、説明変数がゼロの場合の応答変数の平均値がわかります。この例では、車の重量がゼロの場合、平均 mpg は 39.44028 です。車の重量をゼロにすることはできないため、これを解釈するのはあまり意味がありませんが、回帰式を作成するには 39.44028 という数値が必要です。
P>|t| (重量): 0.000。これは、体重の検定統計量に関連付けられた p 値です。この場合、この値は 0.05 未満であるため、体重と mpg の間に統計的に有意な関係があると結論付けることができます。
回帰式:最後に、2 つの係数値を使用して回帰式を作成できます。この場合、方程式は次のようになります。
予測mpg = 39.44028 – 0.0060087*(重量)
この方程式を使用して、車の重量を考慮して予想される燃費を見つけることができます。たとえば、重量が 4,000 ポンドの車の mpg は 15,405 になります。
予測mpg = 39.44028 – 0.0060087*(4000) = 15.405
ステップ 5: 結果を報告します。
最後に、単純な線形回帰の結果を報告したいと思います。これを行う方法の例を次に示します。
線形回帰を実行して、車の重量とガロンあたりのマイル数の関係を定量化しました。分析には 74 台の車のサンプルが使用されました。
結果は、体重と mpg の間に統計的に有意な関係があり (t = -11.60、p < 0.0001)、体重が mpg で説明された変動の 65.15% を占めることを示しました。
回帰式は次のようになりました。
予測mpg = 39.44 – 0.006 (重量)
追加のポンドごとに、平均で 1 ガロンあたり -0.006 マイルの減少が伴いました。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る