回帰または分類: 違いは何ですか?
機械学習アルゴリズムは、教師あり学習アルゴリズムと教師なし学習アルゴリズムという2 つの異なるタイプに分類できます。

教師あり学習アルゴリズムは、次の 2 つのタイプに分類できます。
1. 回帰:応答変数は連続です。
たとえば、 応答変数は次のようになります。
- 重さ
- 身長
- 価格
- 時間
- 総ユニット数
いずれの場合も、回帰モデルは連続量を予測しようとします。
回帰の例:
100 軒の異なる住宅について、平方フィート、バスルームの数、販売価格という 3 つの変数を含むデータ セットがあるとします。
平方フィートとバスルームの数を説明変数として、販売価格を応答変数として使用する回帰モデルを当てはめることができます。
次に、このモデルを使用して、面積とバスルームの数に基づいて住宅の販売価格を予測できます。
応答変数 (販売価格) が連続であるため、これは回帰モデルの例です。
回帰モデルの精度を測定する最も一般的な方法は、二乗平均平方根誤差 (RMSE) を計算することです。これは、予測値がモデルの観測値から平均してどの程度離れているかを示す指標です。次のように計算されます。
RMSE = √ Σ(P i – O i ) 2 / n
金:
- Σは「和」を意味する派手な記号です
- Piはi 番目の観測値の予測値です
- O iはi 番目の観測値の観測値です
- n はサンプルサイズです
RMSE が小さいほど、回帰モデルはデータに適合しやすくなります。
2. 分類:応答変数はカテゴリカルです。
たとえば、応答変数は次の値を取ることができます。
- 男性か女性
- 成功するか失敗するか
- 低、中、または高
いずれの場合も、分類モデルはクラス ラベルを予測しようとします。
分類例:
100 人の異なる大学バスケットボール選手に関する 3 つの変数 (1 試合あたりの平均得点、部門レベル、NBA にドラフトされたかどうか) を含むデータセットがあるとします。
ゲームごとおよび部門レベルごとの平均ポイントを説明変数として使用し、応答変数として「ドラフト」を使用する分類モデルを適応させることができます。
次に、このモデルを使用して、ゲームごとの平均ポイントとディビジョン レベルに基づいて、特定のプレーヤーが NBA にドラフトされるかどうかを予測できます。
応答変数 (「書き込み」) がカテゴリカルであるため、これは分類モデルの例です。言い換えれば、「作成済み」または「未ドラフト」の 2 つの異なるカテゴリの値のみを取ることができます。
分類モデルの精度を測定する最も一般的な方法は、モデルによって行われた正しい分類の割合を単純に計算することです。
精度 = 修正分類 / 分類試行の合計数 * 100%
たとえば、モデルがプレーヤーが NBA にドラフトされるかどうかを 100 回中 88 回正しく特定した場合、モデルの精度は次のようになります。
精度 = (88/100) * 100% = 88%
精度が高いほど、分類モデルは結果をより正確に予測できます。
回帰と分類の類似点
回帰アルゴリズムと分類アルゴリズムは、次の点で似ています。
- どちらも教師あり学習アルゴリズムです。つまり、どちらも応答変数を必要とします。
- どちらも 1 つ以上の説明変数を使用して、応答を予測するモデルを作成します。
- どちらも、説明変数の値の変化が応答変数の値にどのような影響を与えるかを理解するために使用できます。
回帰と分類の違い
回帰アルゴリズムと分類アルゴリズムは次の点で異なります。
- 回帰アルゴリズムは連続量を予測しようとし、分類アルゴリズムはクラス ラベルを予測しようとします。
- 回帰モデルと分類モデルの精度を測定する方法は異なります。
回帰を分類に変換する
回帰問題は、応答変数をコンパートメントに離散化するだけで分類問題に変換できることに注意してください。
たとえば、平方フィート、バスルームの数、販売価格の 3 つの変数を含むデータ セットがあるとします。
販売価格を予測するために、面積とバスルームの数を使用して回帰モデルを構築できます。
ただし、販売価格を 3 つの異なるクラスに離散化できます。
- $80,000 – $160,000: 「低セール価格」
- $161,000 – $240,000: 「平均販売価格」
- $241,000 – $320,000: 「販売価格が高い」
次に、平方フィートとバスルームの数を説明変数として使用して、特定の住宅の販売価格がどのクラス (低、中、または高) に分類されるかを予測できます。
これは、各家をクラスに配置しようとしているため、分類モデルの例になります。
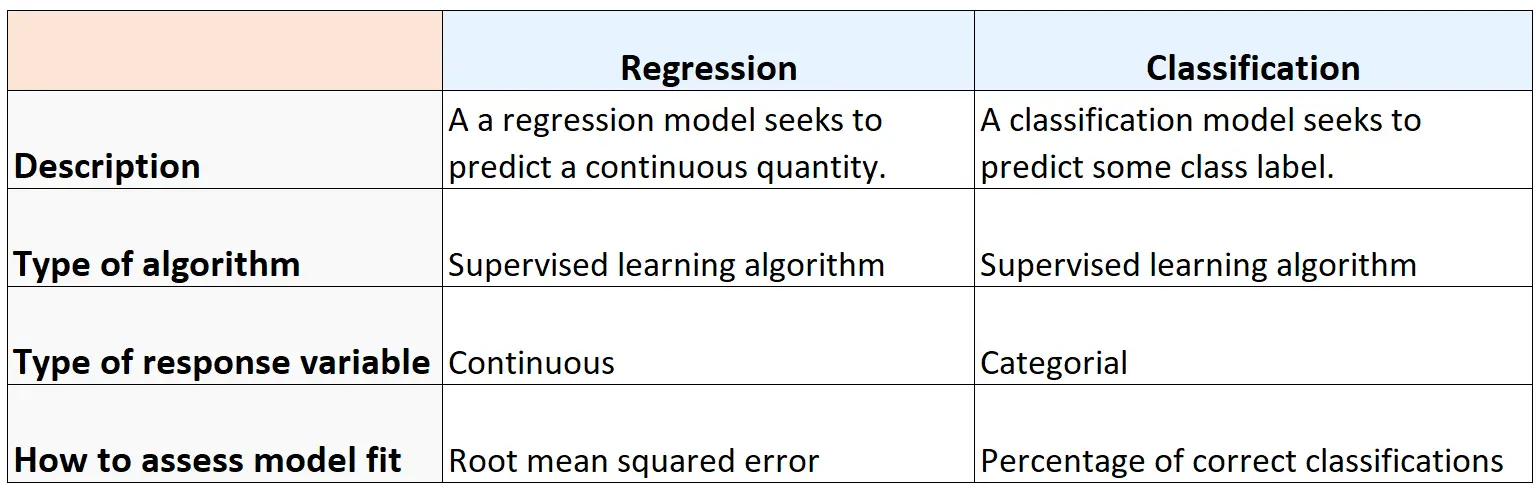
まとめ
次の表は、回帰アルゴリズムと分類アルゴリズムの類似点と相違点をまとめたものです。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る