多項式回帰の概要
予測変数と応答変数を含むデータセットがある場合、多くの場合、単純な線形回帰を使用して 2 つの変数間の関係を定量化します。
ただし、単純線形回帰 (SLR) は、予測変数と応答変数の間の関係が線形であることを前提としています。数学的表記法で記述された SLR は、関係が次の形式を取ることを前提としています。
Y = β 0 + β 1 X + ε
しかし実際には、2 つの変数間の関係は実際には非線形である可能性があり、線形回帰を使用しようとするとモデルの適合性が不十分になる可能性があります。
予測変数と応答変数の間の非線形関係を考慮する 1 つの方法は、次の形式をとる多項式回帰を使用することです。
Y = β 0 + β 1 X + β 2 X 2 + … + β h
この式において、 hは多項式の次数と呼ばれます。
hの値を増やすと、モデルは非線形関係にうまく対応できるようになりますが、実際にはh に3 または 4 より大きい値を選択することはほとんどありません。この点を超えると、モデルは柔軟性が高くなりすぎてデータを過学習します。
技術的なメモ
- 多項式回帰は非線形データに適合できますが、係数β1 、 β2 、…、 βhが線形であるため、線形回帰の一種とみなされます。
- 多項式回帰は複数の予測子変数に使用することもできますが、これによりモデル内に交互作用項が作成され、複数の予測子変数が使用される場合にモデルが非常に複雑になる可能性があります。
多項式回帰を使用する場合
予測変数と応答変数の間の関係が非線形である場合、多項式回帰を使用します。
非線形関係を検出するには、次の 3 つの一般的な方法があります。
1. 散布図を作成します。
非線形関係を検出する最も簡単な方法は、応答変数と予測変数の散布図を作成することです。
たとえば、次の散布図を作成すると、2 つの変数間の関係がほぼ線形であることがわかり、このデータでは単純な線形回帰がおそらくうまく機能するでしょう。
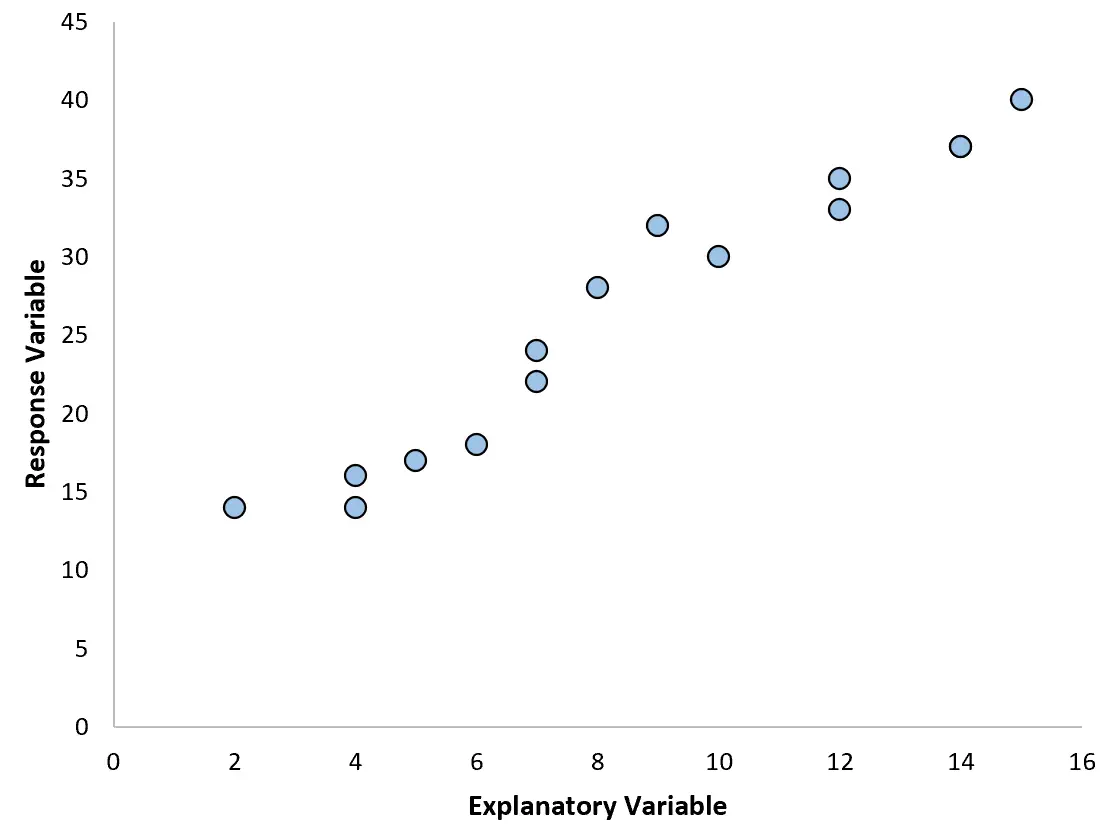
ただし、散布図が次のいずれかのグラフのようであれば、関係が非線形であることがわかり、多項式回帰が適切であることがわかります。
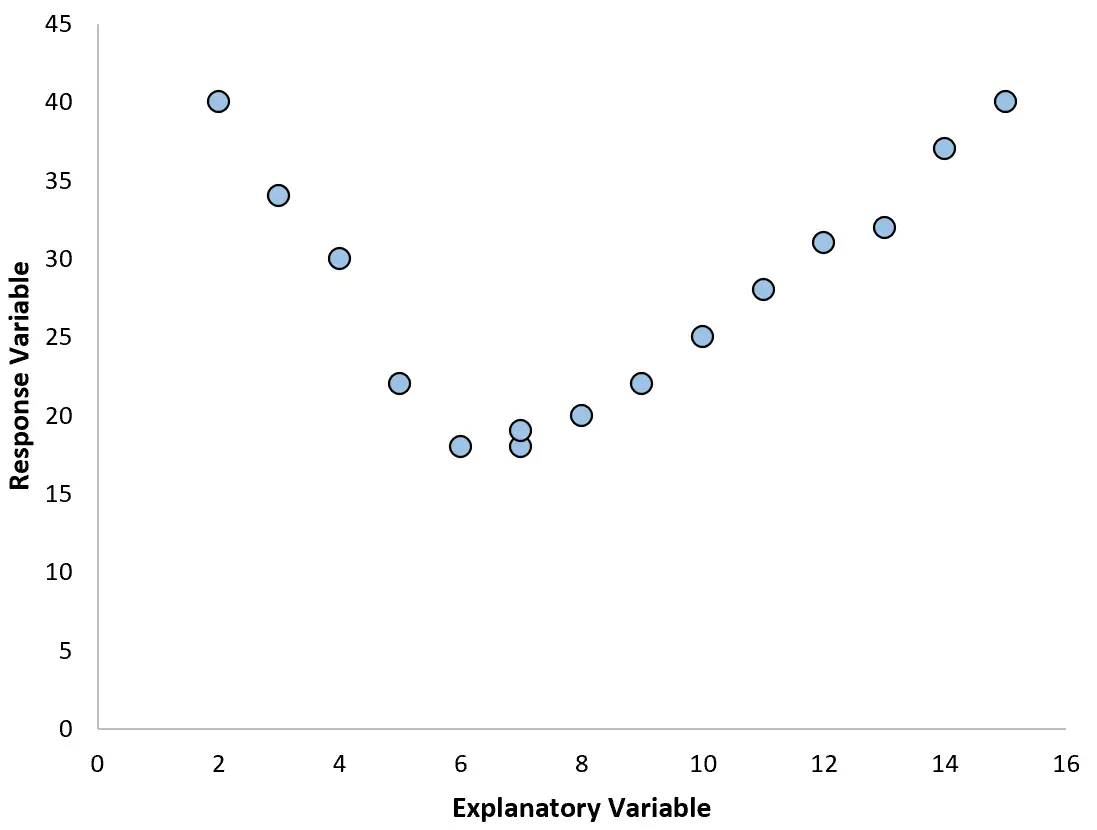
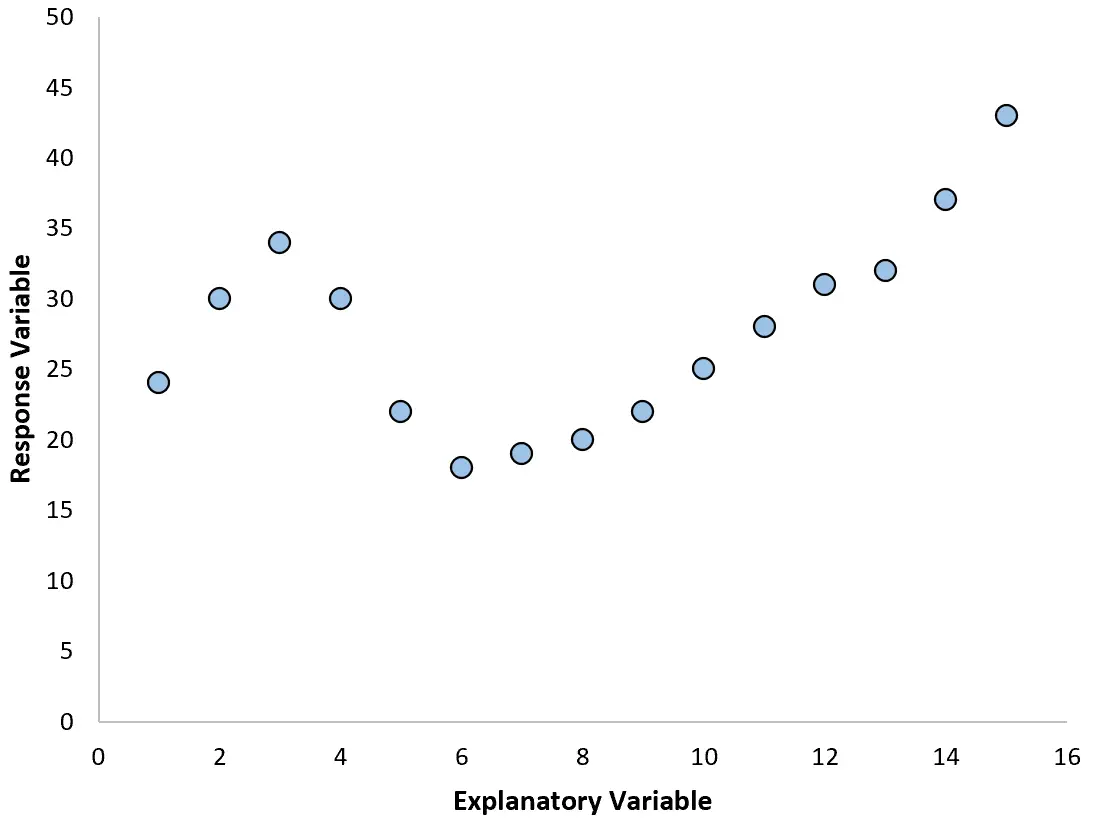
2. 近似プロットに対する残差のプロットを作成します。
非線形性を検出するもう 1 つの方法は、単純な線形回帰モデルをデータに当てはめて、 当てはめた値に対する残差のプロットを作成することです。
プロットの残差がゼロ付近にほぼ均等に分布しており、明確な傾向がない場合は、おそらく単純な線形回帰で十分です。
ただし、グラフ内で残差が非線形傾向を示している場合は、予測変数と応答の間の関係が非線形である可能性が高いことを示しています。
3. モデルの R 2を計算します。
回帰モデルの R 2値は、予測変数によって説明できる応答変数の変動のパーセンテージを示します。
単純な線形回帰モデルをデータセットに当てはめ、モデルの R 2値が非常に低い場合、これは、予測変数と応答変数の間の関係が単純な線形関係よりも複雑であることを示している可能性があります。
これは、代わりに多項式回帰を試行する必要がある可能性があることを示している可能性があります。
関連: 適切な R 二乗値とは何ですか?
多項式の次数を選択する方法
多項式回帰モデルは次の形式になります。
Y = β 0 + β 1 X + β 2 X 2 + … + β h
この式では、 hは多項式の次数です。
しかし、 hの値をどのように選択すればよいでしょうか?
実際には、異なるh値でいくつかの異なるモデルを適合させ、k 分割交差検証を実行して、どのモデルが最も低い検定平均二乗誤差 (MSE) を生成するかを決定します。
たとえば、次のモデルを特定のデータセットに適合させることができます。
- Y = β 0 + β 1
- Y = β 0 + β 1 X + β 2 X 2
- Y = β0 + β1X + β2X2 + β3X3
- Y = β 0 + β 1 X + β 2 X 2 + β 3 X 3 + β 4 X 4
次に、k 分割交差検証を使用して各モデルの MSE テストを計算できます。これにより、各モデルがこれまでに見たことのないデータに対してどの程度うまく機能するかがわかります。
多項式回帰のバイアスと分散のトレードオフ
多項式回帰を使用する場合、 バイアスと分散のトレードオフが存在します。多項式の次数が増加すると、バイアスは減少しますが (モデルがより柔軟になるため)、分散は増加します。
すべての機械学習モデルと同様に、バイアスと分散の間の最適なトレードオフを見つける必要があります。
ほとんどの場合、これにより多項式の次数をある程度増加させることができますが、特定の値を超えると、モデルがデータ内のノイズに適応し始め、テストの MSE が減少し始めます。
柔軟性がありながら柔軟性が高すぎないモデルを確実に適合させるために、k 分割相互検証を使用して、最も低い MSE テストを生成するモデルを見つけます。
多項式回帰を実行する方法
次のチュートリアルでは、さまざまなソフトウェアで多項式回帰を実行する方法の例を示します。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る