推論と予測: 違いは何ですか?
統計では、次の 2 つの理由のいずれかでデータを使用することがよくあります。
(1) 推論:既存のデータセットにおける予測変数と応答変数の間の関係の性質を理解したいと考えています。
(2) 予測:既存のデータセットを使用して、新しい観測の応答変数の値を予測するモデルを構築したいと考えています。
たとえば、住宅に関する情報を含む次のデータセットがあるとします。
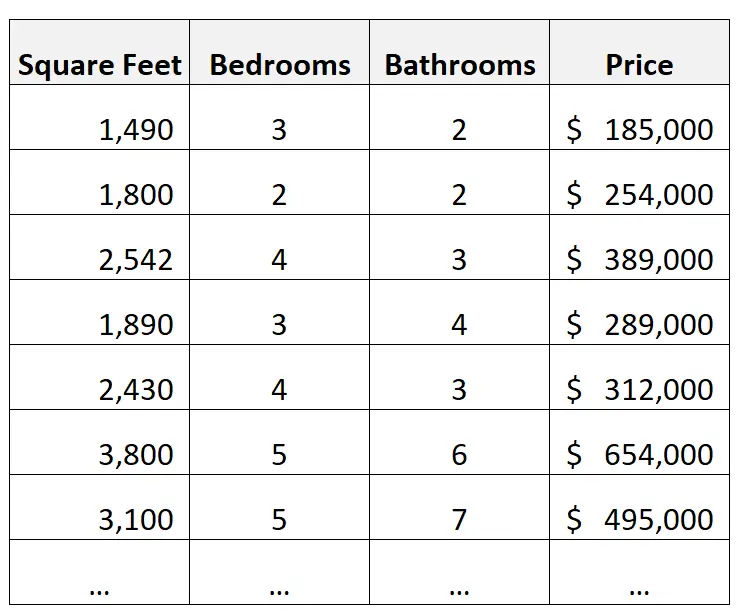
推論の例:
予測変数として平方フィート、寝室数、バスルームの数を、応答変数として価格を使用して重線形回帰モデルを構築するとします。
次に、回帰係数を使用して、各予測変数の 1 単位の変化に関連する価格の平均変化を理解できます。
たとえば、寝室が追加されるたび、バスルームが追加されるたび、平方フィートが追加されるたびに、価格が (平均して) どれだけ変化するかを理解できます。
予測の例:
同じ重線形回帰モデルを構築し、それを使用して、面積、寝室の数、バスルームの数に基づいて新しい家の価値を予測することができます。
たとえば、このモデルを使用して、ベッドルーム 3 つ、バスルーム 3 つ、面積 2,000 平方フィートの新しい家の価格を予測できます。
その後、予測を実際の掲載価格と比較して、住宅が過小評価されているか過大評価されているかを評価できます。
次の例は、さまざまなシナリオにおける推論と予測の違いを示しています。
例 1: スポーツにおける推論と予測
プロ バスケットボール チームに関する情報を含む次のデータセットがあるとします。
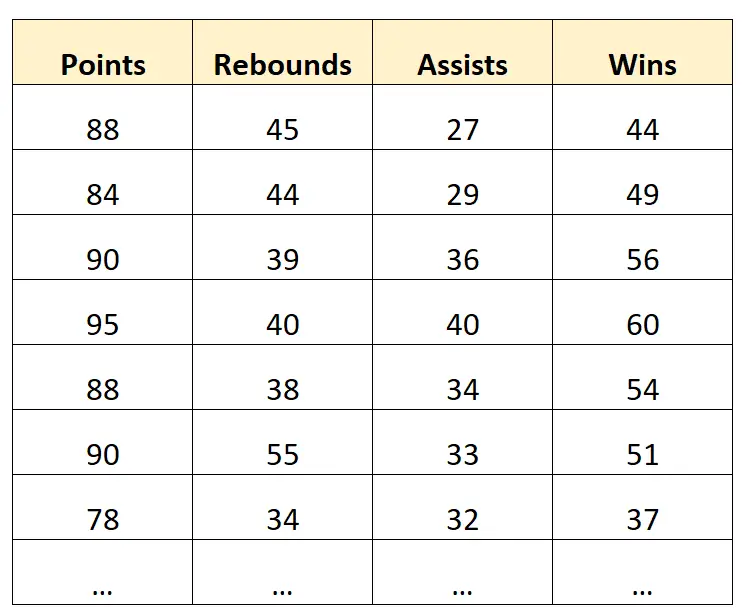
推論の例:
ポイント、リバウンド、アシストを予測変数として使用し、勝利を応答変数として使用して重線形回帰モデルを構築するとします。
その後、モデルを使用して、追加のポイント、リバウンド、アシストごとに勝利数が (平均して) どれだけ変化するかを理解できます。
予測の例:
同じ重線形回帰モデルを構築し、それを使用して、ポイント、リバウンド、アシストの数に基づいてチームが何回勝利するかを予測することができます。
たとえば、このモデルを使用して、90 得点、40 リバウンド、30 アシストのチームが何勝するかを予測できます。
例 2: ビジネスにおける推論と予測
さまざまな企業の年間収益 (百万単位) に関する情報を含む次のデータセットがあるとします。
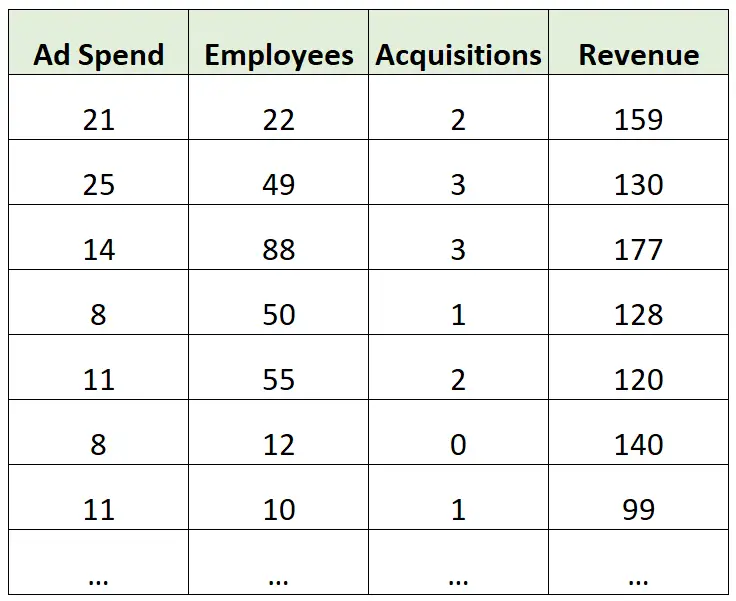
推論の例:
広告支出、従業員数、総買収数を予測変数として、年間収益を応答変数として使用して、重線形回帰モデルを構築するとします。
その後、このモデルを使用して、広告費、従業員の追加、買収のそれぞれに追加のドルが費やされるたびに、年間総収益が (平均して) どれだけ変化するかを理解できます。
予測の例:
同じ重線形回帰モデルを構築し、それを使用して、マーケティング費用の総額、従業員数、買収総額に基づいて企業の年間収益を予測することができます。
たとえば、このモデルを使用して、広告に 2,500 万ドルを費やし、従業員数が 40 人で、2 件の買収を行った企業の年間収益を予測できます。
追加リソース
次のチュートリアルでは、統計で理解する必要がある重要な用語に関する追加情報を提供します。
記述統計と推論統計: 違いは何ですか?
測定レベル: 名目、順序、間隔、比率
質的変数と量的変数: 違いは何ですか?
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る