確率サンプリング
この記事では、確率サンプリングとは何か、存在するさまざまな種類の確率サンプリングとその実行方法について説明します。さらに、確率サンプリングの例がいくつかあります。最後に、確率サンプリングと非確率サンプリングの違いは何か、確率サンプリングの長所と短所は何かを示します。
確率サンプリングとは何ですか?
確率サンプリングは、統計研究のサンプルに含まれる個人を選択するために使用される方法です。確率サンプリングの主な特徴は、個人がランダムに選択されること、つまり、誰もが同じ確率で選択されることです。
これは、サンプリングが確率的であるとみなされるための必須の条件です。つまり、統計母集団のすべての要素が選択可能でなければならず、さらに、それらが選択される可能性が同じでなければなりません。
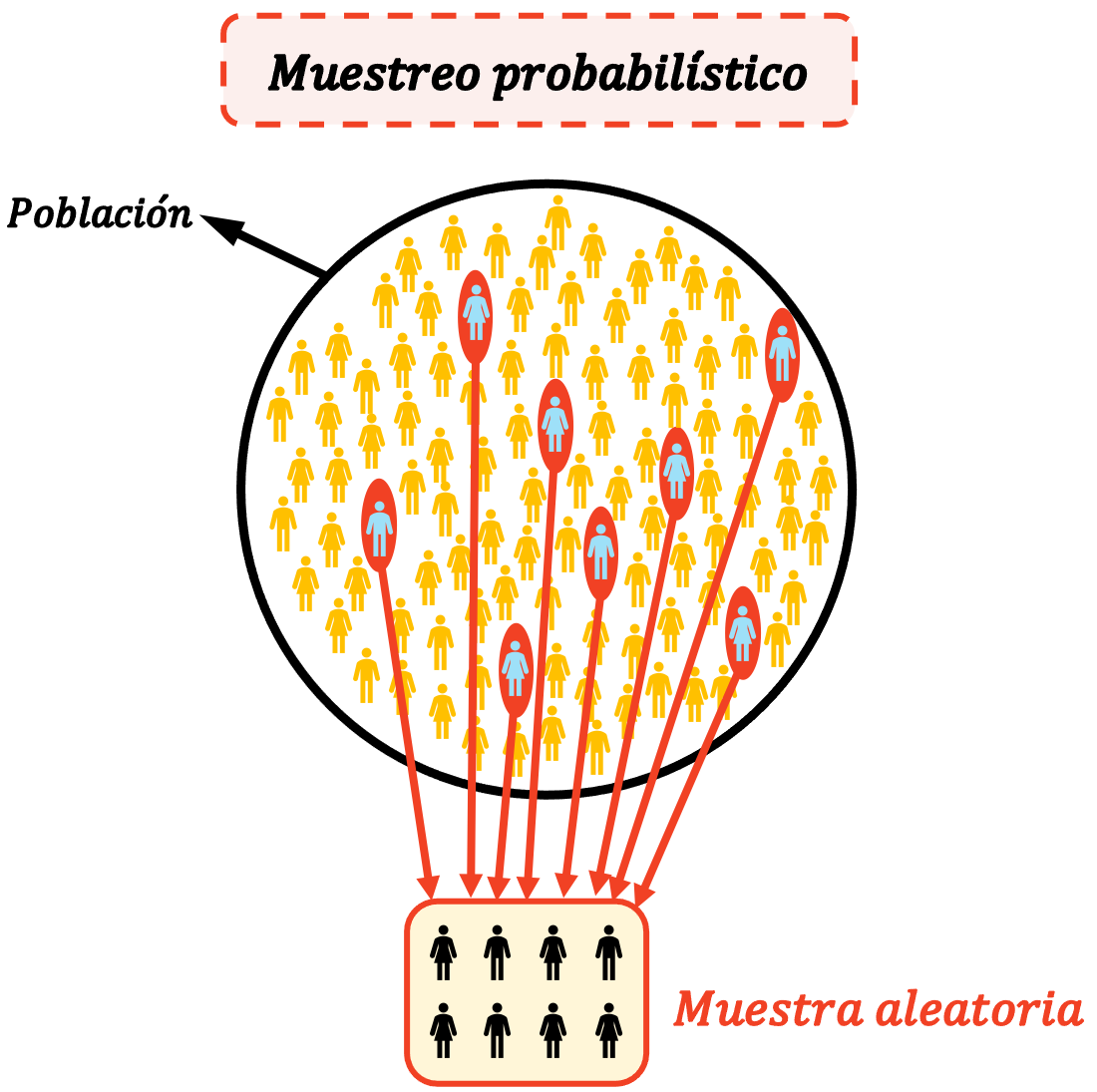
確率サンプリングは、統計研究に参加する人の数を減らすために使用されます。通常、母集団を統計的に分析したい場合、その母集団は非常に大きいため、すべての人にインタビューすることは不可能です。確率サンプリングを使用すると、サンプルのみに質問し、得られた結果を母集団全体に推定できるのはこのためです。
確率サンプリングのすべての特性については後で詳しく説明しますが、プロセス全体を通じてランダム性が存在するため、このタイプのサンプリングは一般に母集団の代表的なサンプルを取得するのに最適です。
確率サンプルの種類
確率サンプリングの種類は次のとおりです。
- 単純なランダム サンプリング– サンプルは単純にランダムに選択されます。
- 系統的サンプリング: 最初の個人がランダムに選択され、サンプルの残りの要素が一定の間隔に従って選択されます。
- 層別サンプリング: 対象母集団をいくつかの層 (グループ) に分割し、各層から個人をランダムに選択します。
- クラスター サンプリング: このサンプリング方法は、母集団がクラスター (グループ) に分割されるという事実を利用し、サンプルがランダムに選択されたクラスターで構成されます。
次に、それぞれの種類の確率サンプリングについて詳しく説明しました。
単純なランダムサンプリング
単純なランダムサンプリングでは、統計母集団の各要素が調査対象のサンプルに含まれる同じ確率が与えられます。したがって、サンプル内の個人は、他の基準を使用せずに単純にランダムに選択されます。
ランダムにシミュレーションするにはいくつかの方法がありますが、現在では時間を大幅に節約できる Excel などのコンピューター プログラムを使用して実行するのが一般的です。
体系的なサンプリング
系統的サンプリングでは、まず母集団の 1 つの要素がランダムに選択され、次にサンプル内の残りの要素が一定の間隔を使用して選択されます。
したがって、体系的なサンプリングでは、サンプルから最初の個人をランダムに選択したら、サンプルから次の個人を抽出するために、必要な間隔と同じだけ数を数えなければなりません。そして、取得したいサンプルサイズと同じ数の個体がサンプル内に含まれるまで、同じ手順を繰り返します。
層化抽出法
層化サンプリング手法では、まず母集団をいくつかの層 (グループ) に分割し、次に各層から何人かの個人をランダムに選択して研究サンプル全体を形成します。したがって、サンプルには各層から少なくとも 1 人のメンバーが存在することになります。
階層は均質なグループである必要があります。つまり、階層内の個人は、他の階層とは異なる独自の特性を持っています。したがって、個人は 1 つの階層にのみ属することができます。
集落抽出
クラスター サンプリングと層化サンプリングは非常に似ているため混同される可能性がありますが、よく見ると、これらは 2 つの異なる確率サンプリング方法です。
クラスター サンプリングでは、母集団内に自然クラスター (グループ) がすでに存在しているという事実を利用して、母集団内のすべての個人ではなく、少数のクラスターのみを研究します。
層化サンプリングとは異なり、この方法ではクラスターから特定の個人を選択する必要はありませんが、研究対象のグループを選択したら、そのメンバー全員を分析する必要があります。
クラスター サンプリングは、クラスター サンプリング、クラスター サンプリング、エリア サンプリングとも呼ばれます。
確率サンプリングを行う方法
確率サンプリングを実行する手順は次のとおりです。
- 対象集団を定義します。
- サンプルの特性と必要なサンプルサイズを定義します。
- 適切なタイプの確率サンプリングを選択します。
- 前のステップで選択したサンプリング方法に従って、サンプル内の個人を選択します。
- 得られたサンプルの元素を分析します。
確率サンプリングを実行する際の最も重要なステップは、適切な確率手法を選択することです。これは、対象母集団に適応するのに役立ち、使用される時間とリソースを節約できます。
論理的に、各ケースにどの方法が適しているかを特定するには、その長所と短所を知る必要があるため、各タイプの確率サンプリングの説明にある上記のリンク先の記事を読むことをお勧めします。
確率サンプルの例
確率サンプリングの定義と各タイプの説明を考慮して、さまざまな確率サンプリング手法を使用して研究のサンプルを選択する方法の例を見ていきます。
- たとえば、多国籍企業の従業員の統計分析を行いたい場合、明らかにその従業員全員を対象に調査を行うことはできませんが、サンプルを選択し、得られた結果を企業全体に推定する必要があります。人口。これを行うには、単純なランダム サンプリングを使用して、完全にランダムに参加者を選択できます。
- 研究参加者をランダムに選択するもう 1 つの方法は、体系的なサンプリングを適用することです。このためには、すべての従業員を含むリストが必要なので、ランダムに 1 人を選択し、リスト内の一定の間隔を数えて、面接を受ける残りの従業員を選択します。
- 層化サンプリングによってサンプルを選択することもできます。これを行うには、人口をグループに分割する必要があります。たとえば、従業員を年齢に従って階層に分類できます。分類後、各グループから個人をランダムに選択します。
- 最後に、クラスター サンプリング方法でサンプルを選択するには、企業がさまざまな国に従業員を抱えてクラスター (グループ) を形成しているという事実を利用して、各従業員が勤務する国のグループに属するようにすることができます。あとは、研究に参加するクラスターをランダムに選択するだけです。
確率サンプリングと非確率サンプリングの違い
確率サンプリングと非確率サンプリングの主な違いは、サンプルの選択方法です。確率抽出では、すべての個人が選択される確率は同じですが、非確率抽出では、個人が選択される可能性は同じではありません。
非確率サンプリングでは、個人がランダムに選択される確率サンプリングとは異なり、サンプル要素の選択は一般に研究者によって行われるため、同じ確率ではありません。
これら 2 つのタイプのサンプリングのもう 1 つの異なる特徴は、得られた結論の一般化にあります。確率サンプリングでは、通常、サンプルは代表的なものであるため、得られた結果は母集団全体に一般化できます。それどころか、非確率サンプリングのサンプルは通常、十分な代表性を持たないため、導かれた結論は調査対象の個人にのみ適用できます。
確率サンプリングの長所と短所
確率サンプリングの長所と短所は次のとおりです。
| アドバンテージ | 短所 |
|---|---|
| 確率サンプリングは一般に経済的に利益が得られます。 | 得られた結果は解釈が難しい場合があります。 |
| これは、迅速かつ簡単に実行できるサンプリング方法です。 | 場合によっては、サンプリング誤差が非常に大きくなることがあります。 |
| 一般に、サンプリングの責任者は母集団についての知識をあまり必要としません。 | 人口全体のリストが必要です。 |
| 得られたサンプルは代表的なものです。 | 小さなサンプルは代表的なものではない可能性があります。 |
確率サンプリングの主な利点は、費用対効果が非常に高いことです。つまり、このサンプリング手法を適用すると、通常は費用対効果が高くなります。
さらに、確率サンプリング法では、サンプル要素の選択がランダムに行われるため、研究者がその分野の知識や経験を持っている必要はありません。この機能により、確率サンプリングが非確率サンプリングよりもはるかに簡単になります。
ただし、特にサンプルが小さい場合、得られる結果が不正確になることがあります。このため、適切なサンプル サイズを選択することが重要です。
確率サンプリング手法のもう 1 つの欠点は、確率をシミュレートするために母集団内のすべての個人のリストが必要になることです。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る