線形回帰の 4 つの仮定
線形回帰は、 2 つの変数 x と y の間の関係を理解するために使用できる便利な統計手法です。ただし、線形回帰を実行する前に、まず次の 4 つの前提が満たされていることを確認する必要があります。
1. 線形関係:独立変数 x と従属変数 y の間には線形関係があります。
2. 独立性:残差は独立しています。特に、時系列データ内の連続する残差間に相関はありません。
3. 等分散性:残差は x の各レベルで一定の分散を持ちます。
4. 正規性:モデルの残差は正規分布します。
これらの仮定の 1 つ以上が満たされない場合、線形回帰の結果は信頼性が低いか、誤解を招く可能性があります。
この記事では、各前提の説明、前提が満たされているかどうかを判断する方法、前提が満たされていない場合の対処方法について説明します。
仮説 1: 線形関係
説明
線形回帰の最初の仮定は、独立変数 x と独立変数 y の間に線形関係があるということです。
この仮定が満たされているかどうかを判断する方法
この仮定が満たされているかどうかを検出する最も簡単な方法は、x と y の散布図を作成することです。これにより、2 つの変数間に線形関係があるかどうかを視覚的に確認できます。プロット上の点が直線上にあるように見える場合は、2 つの変数の間にある種の線形関係があり、この仮定が満たされています。
たとえば、以下のグラフ内の点は直線上にあるように見え、x と y の間に線形関係があることを示しています。
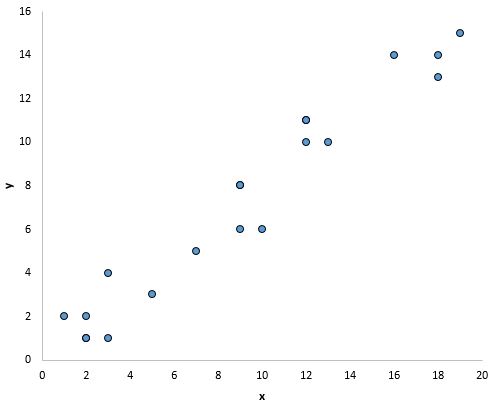
ただし、以下のグラフでは、x と y の間に線形関係があるようには見えません。
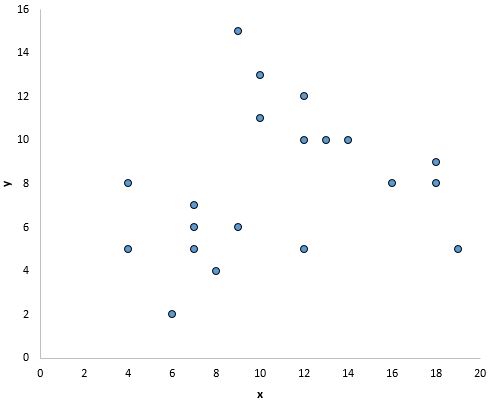
そして、このグラフでは、x と y の間に明確な関係があるように見えますが、線形関係はありません。
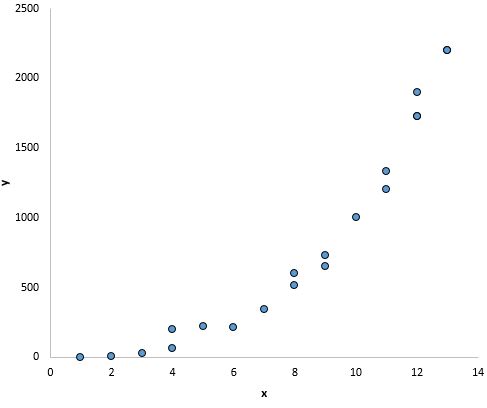
この前提が尊重されない場合はどうすればよいか
x と y の値の散布図を作成し、2 つの変数間に線形関係がないことが判明した場合、いくつかの選択肢があります。
1.非線形変換を独立変数および/または従属変数に適用します。一般的な例には、独立変数および/または従属変数の対数、平方根、または逆数を取得することが含まれます。
2.別の独立変数をモデルに追加します。たとえば、x と y のプロットが放物線状の場合、モデルに追加の独立変数として X 2を追加することが合理的である可能性があります。
仮説 2: 独立性
説明
線形回帰の次の仮定は、残差が独立しているということです。これは、時系列データを操作する場合に特に関係します。理想的には、連続する残差間に傾向が存在することは望ましくありません。たとえば、残留物が時間の経過とともに継続的に増加してはなりません。
この仮定が満たされているかどうかを判断する方法
この仮定が成り立つかどうかをテストする最も簡単な方法は、残差の時系列プロット、つまり残差対時間のプロットを見ることです。理想的には、ほとんどの残差自己相関は、ゼロ付近の 95% 信頼帯内に収まる必要があります。これは、 nの平方根で約 +/- 2 に位置します ( nはサンプル サイズ)。 ダービン-ワトソン テストを使用して、この仮定が満たされるかどうかを正式にテストすることもできます。
この前提が尊重されない場合はどうすればよいか
この前提にどのように違反するかに応じて、いくつかの選択肢があります。
- 正の系列相関を得るには、従属変数および/または独立変数のラグをモデルに追加することを検討してください。
- 負のシリアル相関の場合は、どの変数も遅延しすぎていないことを確認してください。
- 季節相関については、モデルに季節ダミーを追加することを検討してください。
仮説 3: 等分散性
説明
線形回帰の次の仮定は、x の各レベルで残差の分散が一定であるということです。これは等分散性と呼ばれます。そうでない場合、残差は不均一分散性の影響を受けます。
回帰分析に不均一分散性が存在する場合、分析結果は信じられなくなります。具体的には、不均一分散性により回帰係数推定値の分散が増加しますが、回帰モデルではそれが考慮されていません。これにより、実際にはそうではないにもかかわらず、回帰モデルがモデル内の項が統計的に有意であると主張する可能性が非常に高くなります。
この仮定が満たされているかどうかを判断する方法
不均一分散性を検出する最も簡単な方法は、近似値/残差プロットを作成することです。
回帰直線をデータセットに当てはめると、それらの当てはめ値の残差に対するモデルの当てはめ値を示す散布図を作成できます。以下の散布図は、不均一分散が存在する近似値と残差の典型的なプロットを示しています。
近似値が増加するにつれて残差がどのように広がるかに注目してください。この「円錐」の形状は、不均一分散性の典型的な兆候です。
この前提が尊重されない場合はどうすればよいか
不均一分散性を補正するには、次の 3 つの一般的な方法があります。
1. 従属変数を変換します。一般的な変換は、単純に従属変数のログを取得することです。たとえば、人口サイズ (独立変数) を使用して都市の花屋の数 (従属変数) を予測する場合、代わりに人口サイズを使用して町の花屋の数の対数を予測してみることができます。元の従属変数ではなく従属変数の対数を使用すると、不均一分散性が消えることがよくあります。
2. 従属変数を再定義します。従属変数を再定義する一般的な方法は、生の値ではなく率を使用することです。たとえば、人口規模を使用して都市の花屋の数を予測する代わりに、人口規模を使用して 1 人あたりの花屋の数を予測できます。ほとんどの場合、花屋の数自体ではなく、一人あたりの花屋の数を測定しているため、これにより、より大きな集団内で自然に発生する変動が軽減されます。
3. 重み付け回帰を使用します。不均一分散性を補正するもう 1 つの方法は、重み付き回帰を使用することです。このタイプの回帰では、近似値の分散に基づいて各データ ポイントに重みが割り当てられます。基本的に、これにより、分散が大きいデータ ポイントに低い重みが与えられ、残差二乗が減少します。適切な重みを使用すると、不均一分散性の問題を解決できます。
仮説 4: 正常性
説明
線形回帰の次の仮定は、残差が正規分布するということです。
この仮定が満たされているかどうかを判断する方法
この仮定が満たされているかどうかを確認するには、次の 2 つの一般的な方法があります。
1. QQ プロットを使用して仮説を視覚的に検証します。
QQ プロット (分位数-分位数プロットの略) は、モデルの残差が正規分布に従うかどうかを判断するために使用できるプロットの一種です。プロット上の点がほぼ直線の対角線を形成している場合は、正規性の仮定が満たされています。
次の QQ プロットは、正規分布にほぼ従う残差の例を示しています。
ただし、以下の QQ プロットは、残差が直線の対角線から明らかに逸脱しており、正規分布に従っていないことを示している場合の例を示しています。
2. Shapiro-Wilk、Kolmogorov-Smironov、Jarque-Barre、D’Agostino-Pearson などの正式な統計検定を使用して正規性の仮定を確認することもできます。ただし、これらの検定はサンプル サイズが大きい場合に敏感であることに注意してください。つまり、サンプル サイズが大きい場合、残差は正規ではないと結論付けることがよくあります。この仮説を検証するには、QQ プロットなどのグラフィカルな手法を単純に使用する方が簡単な場合が多いのはこのためです。
この前提が尊重されない場合はどうすればよいか
正規性の仮定が満たされない場合、いくつかの選択肢があります。
- まず、外れ値が分布に大きな影響を与えていないことを確認します。外れ値がある場合は、それらが実際の値であり、データ入力エラーではないことを確認してください。
- 次に、独立変数および/または従属変数に非線形変換を適用できます。一般的な例には、独立変数および/または従属変数の対数、平方根、または逆数を取得することが含まれます。
参考文献:
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る