適合性試験
この記事では、適合度検定とは何なのか、また統計で何に使用されるのかについて説明します。また、フィット テストの実行方法も示し、さらに、演習を段階的に解決することもできます。
フィットテストとは何ですか?
適合度検定は、データのサンプルが特定の確率分布に適合するかどうかを判断できる統計検定です。言い換えれば、適切性テストは、観測されたデータが期待されるデータと一致するかどうかを確認するために使用されます。
多くの場合、私たちは現象について予測を立てようとしますが、その結果、その現象について、起こると思われる期待値が得られます。ただし、その後データを収集し、収集されたデータが期待に一致するかどうかを確認する必要があります。したがって、適切性テストを使用すると、統計的基準を使用して、期待されるデータと観察されたデータが類似しているかどうかを判断できます。
したがって、適合度検定は、観測値が期待値と等しいという帰無仮説をもつ仮説検定ですが、一方で検定の対立仮説は、観測値が統計的に異なることを示します。期待値から。
![\begin{cases}H_0: f(x)=f_o(x)\\[2ex]H_1: f(x)\neq f_o(x)\end{cases}](https://statorials.org/wp-content/ql-cache/quicklatex.com-db79847cd8097a2baca298bf82594f4f_l3.png "Rendered by QuickLaTeX.com")
統計学では、検定の参照分布がカイ二乗分布であるため、適合度検定はカイ二乗検定とも呼ばれます。
フィットテストの公式
適合度検定統計量は、観測値と期待値の差の二乗和を期待値で割ったものに等しくなります。
したがって、十分性テストの式は次のようになります。

金:
-

は適合度検定統計量であり、次のカイ二乗分布に従います。

自由度。
-

データのサンプルサイズです。
-

はデータ i の観測値です。
-

はデータ i の期待値です。
したがって、重要度レベルを考慮すると、

、計算された検定統計量を臨界検定値と比較して、仮説検定の帰無仮説または対立仮説を棄却するかどうかを決定する必要があります。
- テスト統計量が臨界値未満の場合

、対立仮説は棄却されます (帰無仮説は受け入れられます)。
- テスト統計量が臨界値より大きい場合
、帰無仮説は棄却されます (対立仮説は受け入れられます)。
![\begin{array}{l}\text{Si } \chi^2<\chi^2_{1-\alpha|k-1}\text{ se rechaza } H_1\\[3ex]\text{Si } \chi^2>\chi^2_{1-\alpha|k-1}\text{ se rechaza } H_0\end{array}” title=”Rendered by QuickLaTeX.com” height=”70″ width=”243″ style=”vertical-align: 0px;”></p>
</p>
<h2 class=](https://statorials.org/wp-content/ql-cache/quicklatex.com-6b48f7bb620dca865b7e652e81cc247a_l3.png) フィットテストのやり方
フィットテストのやり方
適合性テストを実行するには、次の手順に従う必要があります。
- まず、適合度検定の帰無仮説と対立仮説を確立します。
- 次に、適合度検定の信頼水準、したがって有意水準を選択します。
- 次に、適合度検定統計量を計算します。その式は上のセクションに記載されています。
- カイ二乗分布表を使用して適合度検定の臨界値を求めます。
- テスト統計量を臨界値と比較します。
- 検定統計量が臨界値より小さい場合、対立仮説は棄却されます (帰無仮説は受け入れられます)。
- 検定統計量が臨界値より大きい場合、帰無仮説は棄却されます (対立仮説は受け入れられます)。
十分性テストの例
- 店主は、売上の 50% が製品 A、売上の 35% が製品 B、そして 15% が製品 C であると言います。ただし、各製品の販売単位は次のとおりです。次の表。所有者の理論上のデータが、収集された実際のデータと統計的に異なるかどうかを分析します。
| 製品 | 観察された売上 (O i ) |
|---|---|
| 製品A | 453 |
| 製品B | 268 |
| 製品C | 79 |
| 合計 | 800 |
観測値が期待値と等しいかどうかを判断するために、適合度検定を実行します。検定の帰無仮説と対立仮説は次のとおりです。
この場合、検定には 95% の信頼水準を使用するため、有意水準は 5% になります。

予想売上高を求めるには、各製品の予想売上のパーセンテージと総売上数を掛ける必要があります。
![\begin{array}{c}E_A=800\cdot 0,50=400\\[2ex]E_B=800\cdot 0,35=280\\[2ex]E_A=800\cdot 0,15=120\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-9daef735efca126bba60ccde38423d7b_l3.png "Rendered by QuickLaTeX.com")
したがって、問題の頻度テーブルは次のようになります。
| 製品 | 観察された売上 (O i ) | 予想売上高 (E i ) |
|---|---|---|
| 製品A | 453 | 400 |
| 製品B | 268 | 280 |
| 製品C | 79 | 120 |
| 合計 | 800 | 800 |
すべての値を計算したので、カイ二乗検定公式を適用して検定統計量を計算します。
![\begin{array}{c}\displaystyle\chi^2=\sum_{i=1}^k\frac{(O_i-E_i)^2}{E_i}\\[6ex]\chi^2=\cfrac{(453-400)^2}{400}+\cfrac{(268-280)^2}{280}+\cfrac{(79-120)^2}{120}\\[6ex]\chi^2=7,02+0,51+14,00\\[6ex]\chi^2=21,53\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-8c76621fbe8504217dfe8ac55b2d6e67_l3.png "Rendered by QuickLaTeX.com")
検定統計量の値が計算されたら、カイ二乗分布表を使用して検定の臨界値を見つけます。カイ二乗分布は次のようになります。

自由度と重要度は
、まだ:
![\begin{array}{c}\chi^2_{1-\alpha|k-1}=\ \color{orange}\bm{?}\color{black}\\[4ex]\chi^2_{0,95|2}=5,991\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-1850e764fc71b1e7b49b0c4d8133ab89_l3.png "Rendered by QuickLaTeX.com")
したがって、検定統計量 (21.53) は臨界検定値 (5.991) より大きいため、帰無仮説は棄却され、対立仮説が受け入れられます。これは、データが大きく異なるため、店主は実際とは異なる売上を期待していたことを意味します。
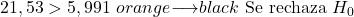
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る