Stata で階層型回帰を実行する方法
階層回帰は、いくつかの異なる線形モデルを比較するために使用できる手法です。
基本的な考え方は、最初に単一の説明変数を使用して線形回帰モデルを当てはめるということです。次に、追加の説明変数を使用して別の回帰モデルを当てはめます。 2 番目のモデルの R 二乗 (説明変数によって説明できる応答変数の分散の割合) が前のモデルの R 二乗よりも大幅に高い場合、これは 2 番目のモデルの方が優れていることを意味します。
次に、追加の回帰モデルをより多くの説明変数でフィッティングするプロセスを繰り返し、新しいモデルが以前のモデルに比べて改善をもたらすかどうかを確認します。
このチュートリアルでは、Stata で階層型回帰を実行する方法の例を示します。
例: Stata の階層型回帰
autoという組み込みデータセットを使用して、Stata で階層回帰を実行する方法を説明します。まず、コマンド ボックスに次のように入力してデータセットを読み込みます。
システムの自動使用
次のコマンドを使用して、データの簡単な概要を取得できます。
要約する
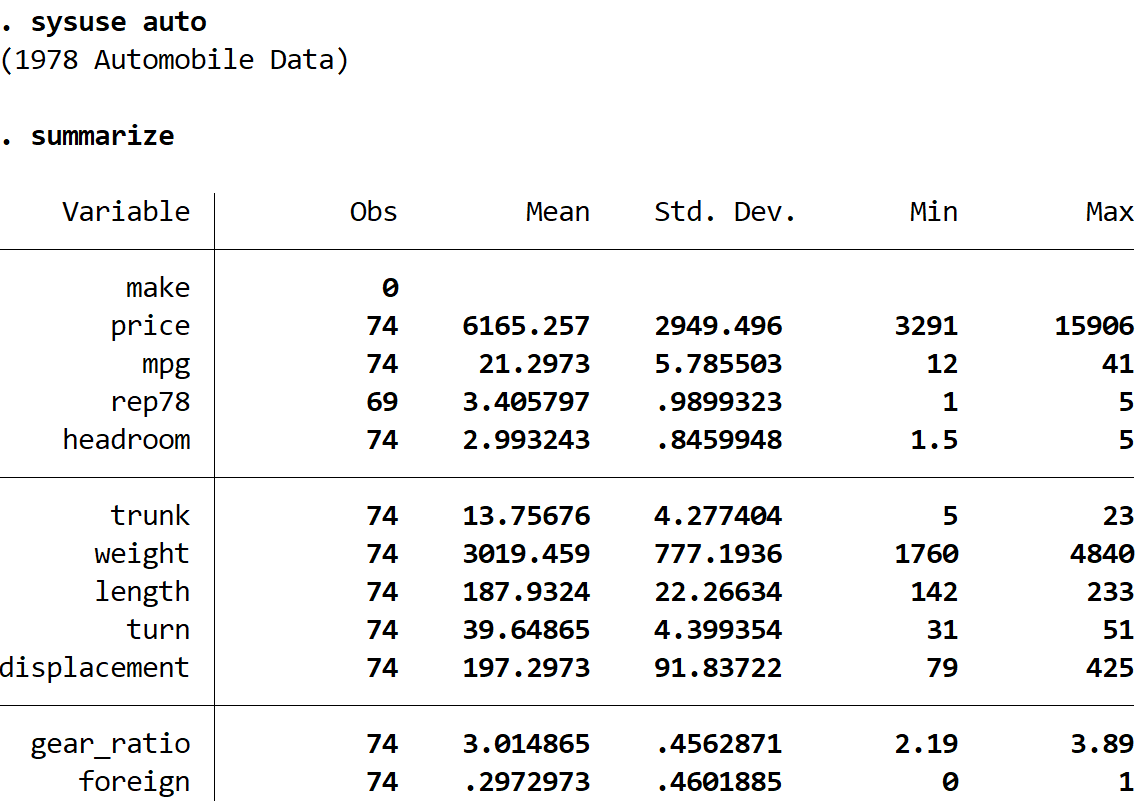
データセットには、合計 74 台の車に関する 12 の異なる変数に関する情報が含まれていることがわかります。
次の 3 つの線形回帰モデルを当てはめ、階層回帰を使用して、後続の各モデルが前のモデルに比べて大幅な改善をもたらすかどうかを確認します。
モデル 1:価格 = 切片 + mpg
モデル 2:価格 = 切片 + mpg + 重量
モデル 3:価格 = 切片 + mpg + 重量 + ギア比
Stata で階層回帰を実行するには、まずHiregパッケージをインストールする必要があります。これを行うには、コマンド ボックスに次のように入力します。
ヒレグを見つける
表示されるウィンドウで、 https://fmwww.bc.edu/RePEc/bocode/h から Hiregをクリックします。
次のウィンドウで、 「ここをクリックしてインストールしてください」というリンクをクリックします。
パッケージは数秒でインストールされます。次に、階層回帰を実行するために、次のコマンドを使用します。
レンタル価格 (mpg) (重量) (ギア比)
これが Stata に要求することは次のとおりです。
- 各モデルの応答変数として価格を使用して階層回帰を実行します。
- 最初のモデルでは、説明変数としてmpgを使用します。
- 2 番目のモデルでは、追加の説明変数として重みを追加します。
- 3 番目のモデルでは、別の説明変数としてgear_ratioを追加します。
最初のモデルの結果は次のとおりです。
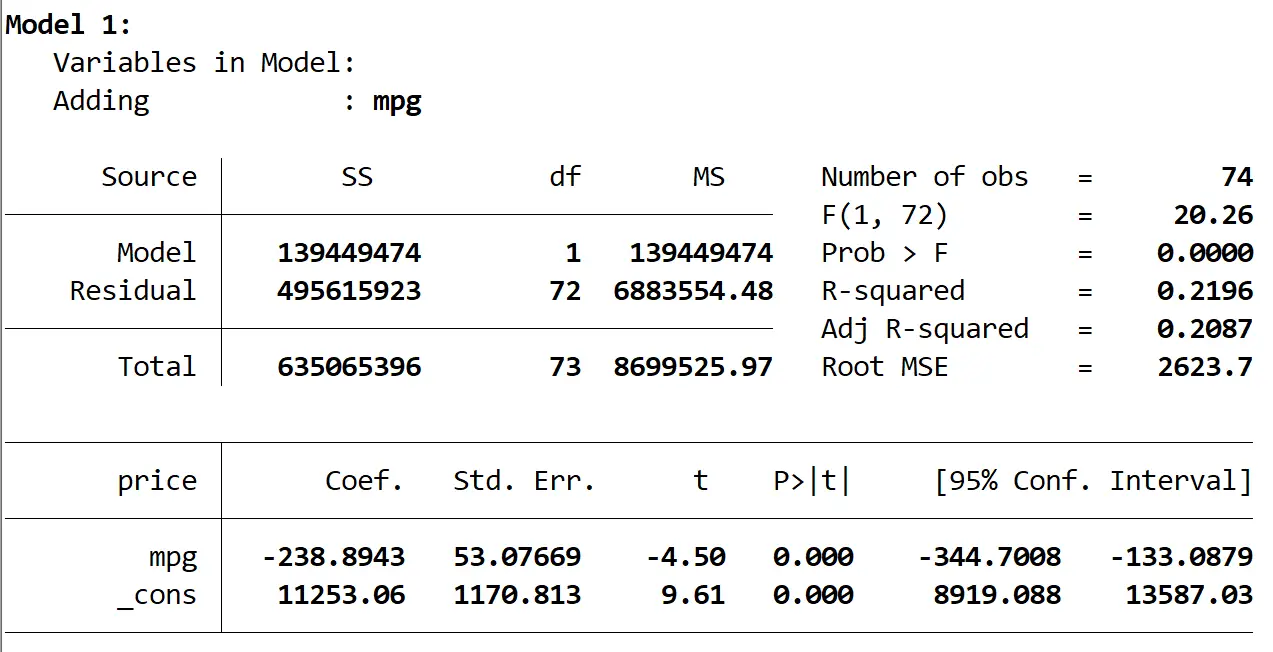
モデルの R 二乗は0.2196で、モデルの全体的な p 値 (Prob > F) は0.0000であり、α = 0.05 で統計的に有意であることがわかります。
次に、2 番目のモデルの結果を確認します。
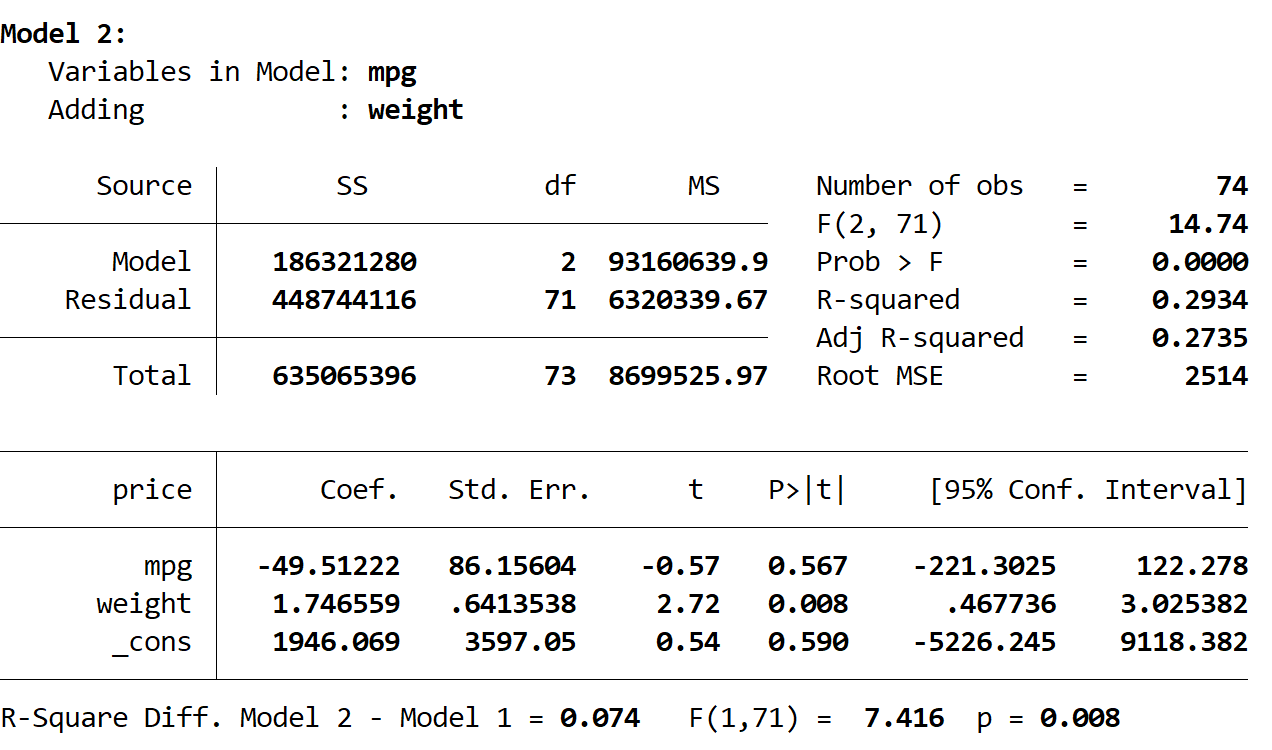
このモデルの R 二乗は0.2934で、最初のモデルよりも大きくなります。この差が統計的に有意であるかどうかを判断するために、Stata は F 検定を実行し、結果の下部に次の数値を示しました。
- 2 つのモデル間の R 二乗差 = 0.074
- 差の F 統計量 = 7.416
- F 統計量の対応する p 値 = 0.008
p 値が 0.05 未満であるため、最初のモデルと比較して 2 番目のモデルには統計的に有意な改善があると結論付けられます。
最後に、3 番目のモデルの結果を確認します。
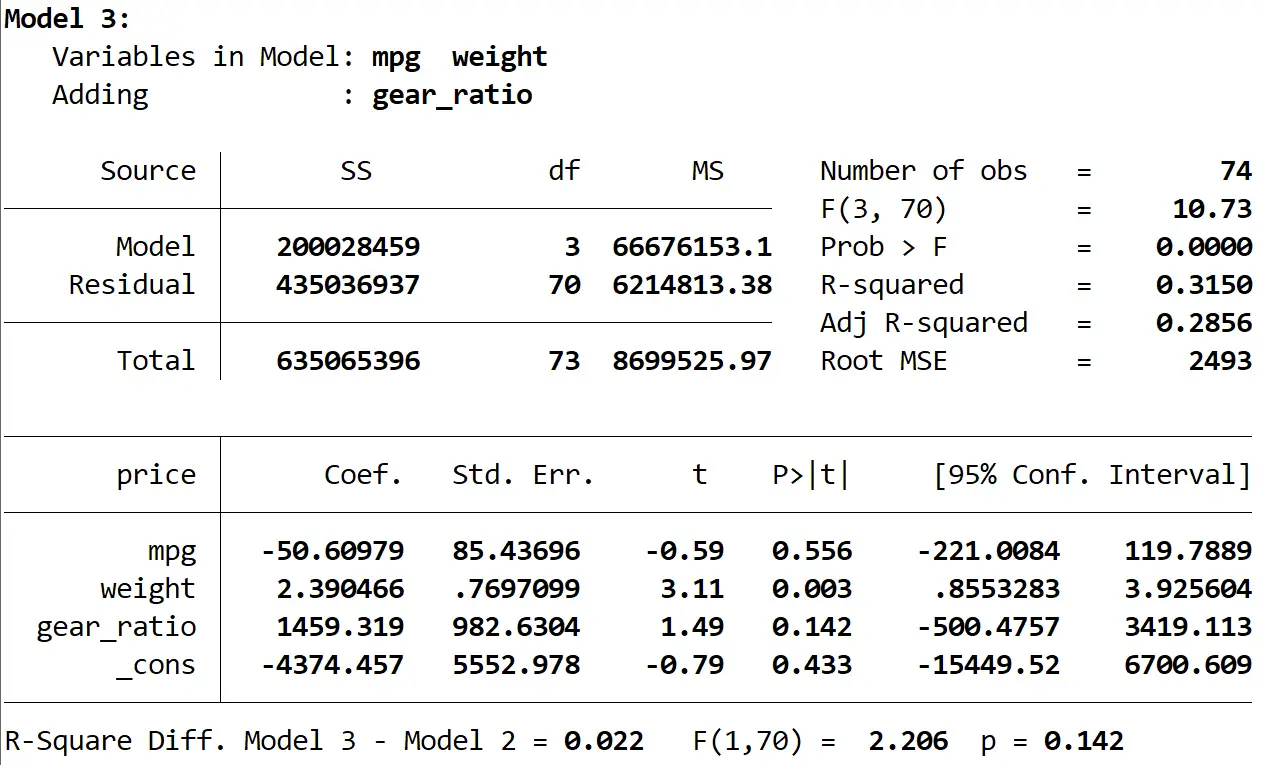
このモデルの R 二乗は0.3150で、2 番目のモデルよりも大きくなります。この差が統計的に有意であるかどうかを判断するために、Stata は F 検定を実行し、結果の下部に次の数値を示しました。
- 2 つのモデル間の R 二乗差 = 0.022
- 差の F 統計量 = 2.206
- F 統計量の対応する p 値 = 0.142
p 値は 0.05 未満ではないため、3 番目のモデルが 2 番目のモデルよりも改善されていると言える十分な証拠はありません。
結果の最後に、Stata が結果の概要を提供していることがわかります。

この特定の例では、モデル 2 はモデル 1 に比べて大幅な改善が見られましたが、モデル 3 はモデル 2 に比べて大幅な改善はなかったと結論付けられます。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る