オープンディストリビューションとは何ですか?
統計において、開分布は、1 つ以上のクラス (または「ビン」) が開いている度数分布です。
たとえば、次の度数分布は、最小クラスが開いた開いた分布を表します。
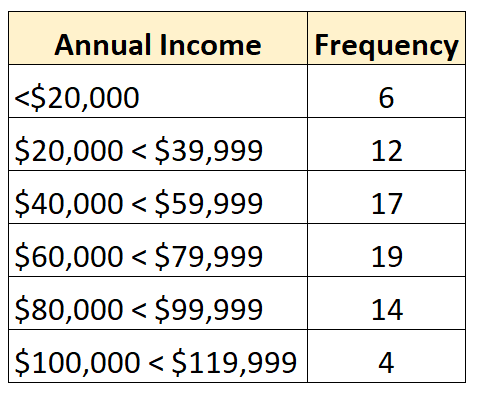
また、次の度数分布は、最大のクラスが開いた開いた分布を示しています。
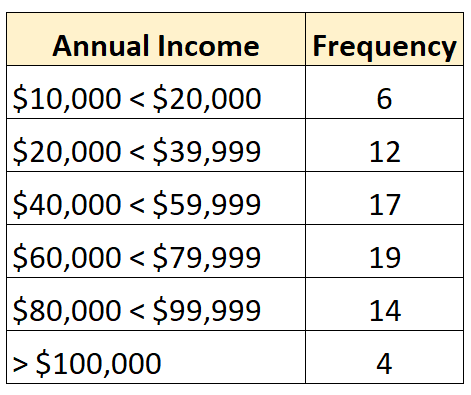
逆に、閉じた分布とは、次のような頻度分布の各クラスに上限と下限がある分布です。
オープンディストリビューションの原因は何ですか?
オープンな分布は、多くの場合、研究者がクラスの 1 つがオープンになるような方法でデータを収集することを選択した結果です。
たとえば、研究者が特定の都市の住民を調査し、世帯年収について尋ねたとします。
研究者は、高所得の居住者は、収入が 100,000 ドルを大幅に超える場合、自分の収入を共有することに抵抗がある可能性があることを知っているため、「>100,000 ドル」という可能な限り幅広い回答を与えることを選択する場合があります。
逆に、研究者は、収入が非常に少ない住民も、自分のわずかな収入を共有することに抵抗があることを知っているため、可能な限り短い答えを与えることを選択する可能性があります。
一言で言えば、研究者はアンケートの質問に安心して答えられる人の数を最大化したいため、アンケートにオープン コースを含めることがよくあります。
オープンディストリビューションの問題
オープン配布の問題は、実際のデータが検閲されていることです。言い換えれば、特定の都市で 10 万ドル以上稼いでいる人の数はわかりますが、実際には彼らの正確な年収はわかりません。
150,000ドル、250,000ドル、500,000ドル、あるいはそれ以上の収入を得ている人もいる可能性がありますが、「調査」では各人が「100,000ドル以上」稼いでいると示すことができないため、わかりません。
公開分布ではデータが打ち切られているため、生データのすべての値にアクセスできないため、データセット内の値の正確な平均と標準偏差を計算することもできません。
オープンディストリビューションを分析する方法
開いた分布の正確な平均を計算することはできないため、データセットの「中心」の尺度として中央値を使用することがよくあります。
中央値はデータセットの中央値を表すことを思い出してください。
開いた分布を扱う場合、次の式を使用して中央値の最適な推定値を見つけることができます。
中央値の最良推定値: L + ((n/2 – F) / f) * w
金:
- L:中群の下限値
- n:観測値の総数
- F:中間グループまでの累積度数
- f:中間グループの周波数
- w:中間グループの幅
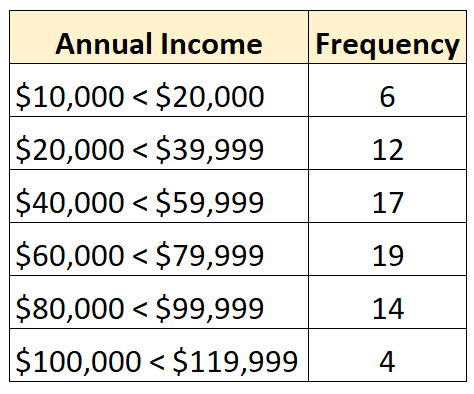
たとえば、次のオープン ディストリビューションがあるとします。
データセットには合計 72 の値があります。したがって、中央値はデータセット内の 36 番目と 37 番目に大きい値の間にあることがわかります。これらの値はそれぞれ「60,000 ドルから 79,999 ドル」クラスに分類されるため、収入の中央値がその範囲内にあることがわかります。
中央値の最良の推定値は次のようになります。
中央値: 60,000 + ((72/2 – 25) / 19) * 19,999 = 71,578 ドル
この値は、このデータセット内の個人の年収中央値の最良の推定値を表しています。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る