帰無仮説を棄却するのはどのような場合ですか? (3例)
仮説検定は、統計的仮説を棄却または棄却できなかったために使用する正式な統計検定です。
仮説テストを実行するには、常に次の手順を使用します。
ステップ 1: 帰無仮説と対立仮説を述べます。
H0で示される帰無仮説は、サンプル データが偶然のみから得られるという仮説です。
HAで示される対立仮説は、サンプル データが非ランダムな原因によって影響されているという仮説です。
2. 使用する有意水準を決定します。
重要度のレベルを決定します。一般的な選択肢は .01、.05、および .1 です。
3. 検定統計量と p 値を計算します。
サンプル データを使用して、検定統計量と対応するp 値を計算します。
4. 帰無仮説を棄却するか、棄却しません。
p 値が有意水準を下回る場合は、帰無仮説を棄却します。
p 値が有意水準を下回っていない場合は、帰無仮説を棄却できません。
このルールを覚えておくために、次の気の利いた行を使用できます。
「p が弱ければヌルは消えるはずです。」
言い換えれば、p 値が十分に低い場合は、帰無仮説を棄却する必要があります。
次の例は、最も一般的なタイプの仮説検定で帰無仮説をいつ棄却するか (または棄却しないか) を示しています。
例 1: 1 サンプルの t 検定
1 サンプル t 検定は、母集団の平均が特定の値に等しいかどうかを検定するために使用されます。
たとえば、特定の種のカメの平均体重が 310 ポンドであるかどうかを知りたいとします。
私たちは外に出て、次の情報を含む 40 匹のカメの単純な無作為サンプルを収集します。
- サンプルサイズ n = 40
- 平均サンプル重量x = 300
- サンプル標準偏差 s = 18.5
次の手順を使用して、1 サンプルの t 検定を実行できます。
ステップ 1: 帰無仮説と対立仮説を述べる
次の仮説を使用して 1 サンプルの t 検定を実行します。
- H 0 : μ = 310 (母集団の平均は 310 冊に等しい)
- H A : μ ≠ 310 (母集団平均は 310 ポンドに等しくありません)
2. 使用する有意水準を決定します。
有意水準0.05を使用することを選択します。
3. 検定統計量と p 値を計算します。
サンプル サイズ、サンプル平均、サンプル標準偏差の数値をこの1 サンプル t 検定計算ツールに代入して、検定統計量と p 値を計算できます。
- t 検定統計量: -3.4187
- 両側 p 値: 0.0015
4. 帰無仮説を棄却するか、棄却しません。
p 値 (0.0015) は有意水準 (0.05) より小さいため、帰無仮説を棄却します。
私たちは、この個体群のカメの平均体重が 310 ポンドに等しくないことを示す十分な証拠があると結論付けています。
例 2: 2 サンプルの t 検定
2 標本 t 検定は、 2 つの母集団の平均が等しいかどうかを検定するために使用されます。
たとえば、2 つの異なる種のカメの平均体重が等しいかどうかを知りたいとします。
次の情報を使用して、各母集団から単純な無作為サンプルを収集します。
サンプル 1:
- サンプルサイズ n 1 = 40
- 平均サンプル重量x 1 = 300
- サンプル標準偏差 s 1 = 18.5
サンプル 2:
- サンプルサイズ n 2 = 38
- 平均サンプル重量x 2 = 305
- サンプル標準偏差 s 2 = 16.7
次の手順を使用して、2 標本の t 検定を実行できます。
ステップ 1: 帰無仮説と対立仮説を述べる
次の仮定を使用して 2 サンプルの t 検定を実行します。
- H 0 : μ 1 = μ 2 (2 つの母集団平均は等しい)
- H 1 : μ 1 ≠ μ 2 (2 つの母集団平均は等しくない)
2. 使用する有意水準を決定します。
有意水準0.10を使用することを選択します。
3. 検定統計量と p 値を計算します。
サンプル サイズ、サンプル平均、サンプル標準偏差の数値をこの2 サンプル t 検定計算ツールに代入して、検定統計量と p 値を計算できます。
- t 検定統計量: -1.2508
- 両側 p 値: 0.2149
4. 帰無仮説を棄却するか、棄却しません。
p 値 (0.2149) は有意水準 (0.10) より小さくないため、帰無仮説を棄却できません。
これら 2 つの個体群のカメの平均体重が異なると言える十分な証拠はありません。
例 3: 対応のあるサンプルの t 検定
対のあるサンプルの t 検定は、一方のサンプルの各観測値がもう一方のサンプルの観測値と関連付けられる場合に、2 つのサンプルの平均を比較するために使用されます。
たとえば、特定のトレーニング プログラムが大学バスケットボール選手の最大垂直ジャンプを向上させることができるかどうかを知りたいとします。
これをテストするために、20 人の大学バスケットボール選手の 単純なランダム サンプルを採用し、それぞれの最大垂直ジャンプを測定できます。次に、各プレーヤーにトレーニング プログラムを 1 か月間使用してもらい、月末に最大垂直ジャンプを再度測定します。
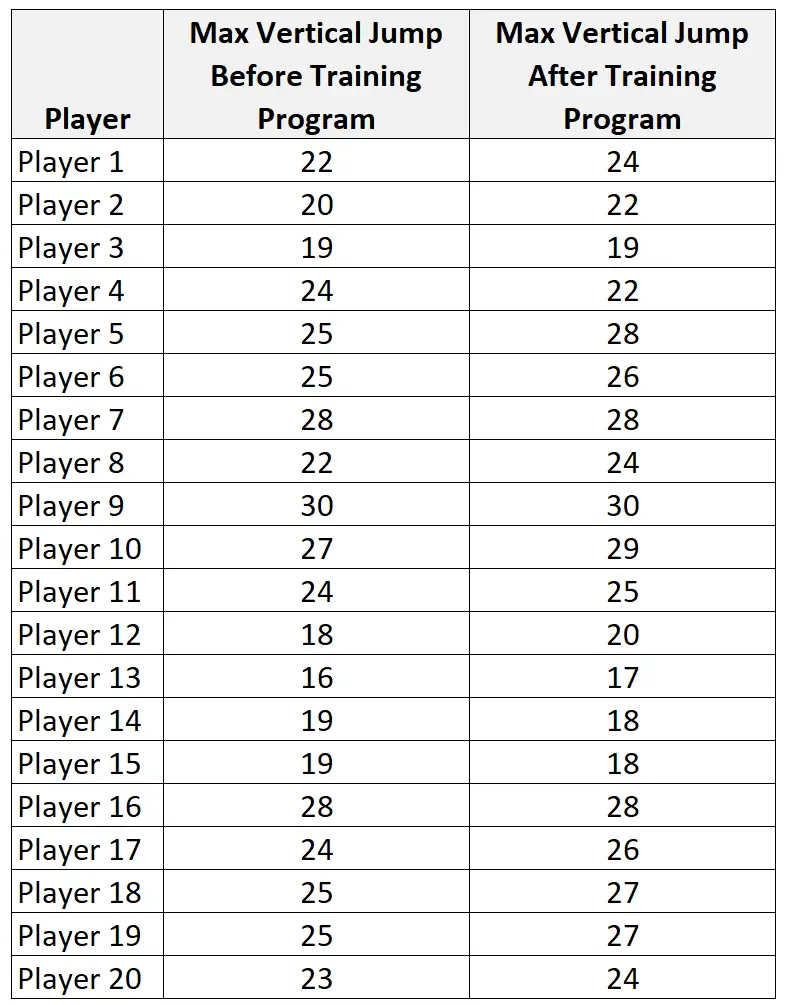
次の手順を使用して、対応のあるサンプルの t 検定を実行できます。
ステップ 1: 帰無仮説と対立仮説を述べる
次の仮説を使用して、対応のあるサンプルの t 検定を実行します。
- H 0 :前のμ =後のμ (2 つの母集団平均は等しい)
- H 1 :前μ ≠後μ (2 つの母集団平均は等しくない)
2. 使用する有意水準を決定します。
有意水準0.01を使用することを選択します。
3. 検定統計量と p 値を計算します。
各サンプルの生データをこのペア サンプル t 検定計算機に接続して、検定統計量と p 値を計算できます。
- t 検定統計量: -3.226
- 両側 p 値: 0.0045
4. 帰無仮説を棄却するか、棄却しません。
p 値 (0.0045) は有意水準 (0.01) より小さいため、帰無仮説を棄却します。
トレーニングプログラムに参加する前と参加後の平均垂直跳びが同等ではないと言える十分な証拠があります。
ボーナス: 意思決定ルール計算ツール
この決定ルール計算ツールを使用すると、検定統計量の値に基づいて、仮説検定の帰無仮説を棄却するかどうかを自動的に決定できます。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る