完全ガイド: excel で anova 結果を解釈する方法
一元配置分散分析は、 3 つ以上の独立したグループの平均間に統計的に有意な差があるかどうかを判断するために使用されます。
次の例は、Excel で一元配置分散分析の結果を解釈する方法に関する完全なガイドを提供します。
例: Excel で ANOVA 結果を解釈する方法
教師がクラスの 30 人の生徒に、試験の準備のために 3 つの勉強方法のうちの 1 つを使用するようにランダムに依頼したとします。
次のスクリーンショットは、生徒が使用した方法に基づく生徒のスコアを示しています。
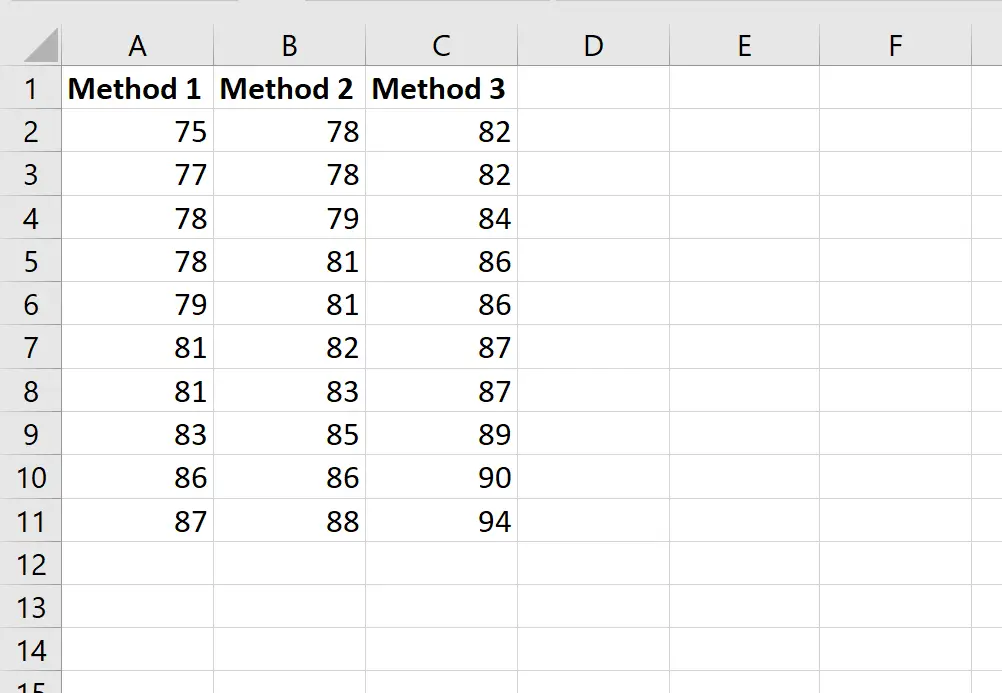
教師が一元配置分散分析を実行して、平均スコアが 3 つのグループ間で同じかどうかを判断したいとします。
Excel で一元配置分散分析を実行するには、上部のリボンに沿って[データ]タブをクリックし、 [分析]グループの[データ分析]をクリックします。
[データ分析]オプションが表示されない場合は、まず無料の分析ツールソフトウェアをロードする必要があります。
クリックすると、新しいウィンドウが表示されます。 [Anova: Single Factor]を選択し、 [OK]をクリックします。
表示される新しいウィンドウで、次の情報を入力します。
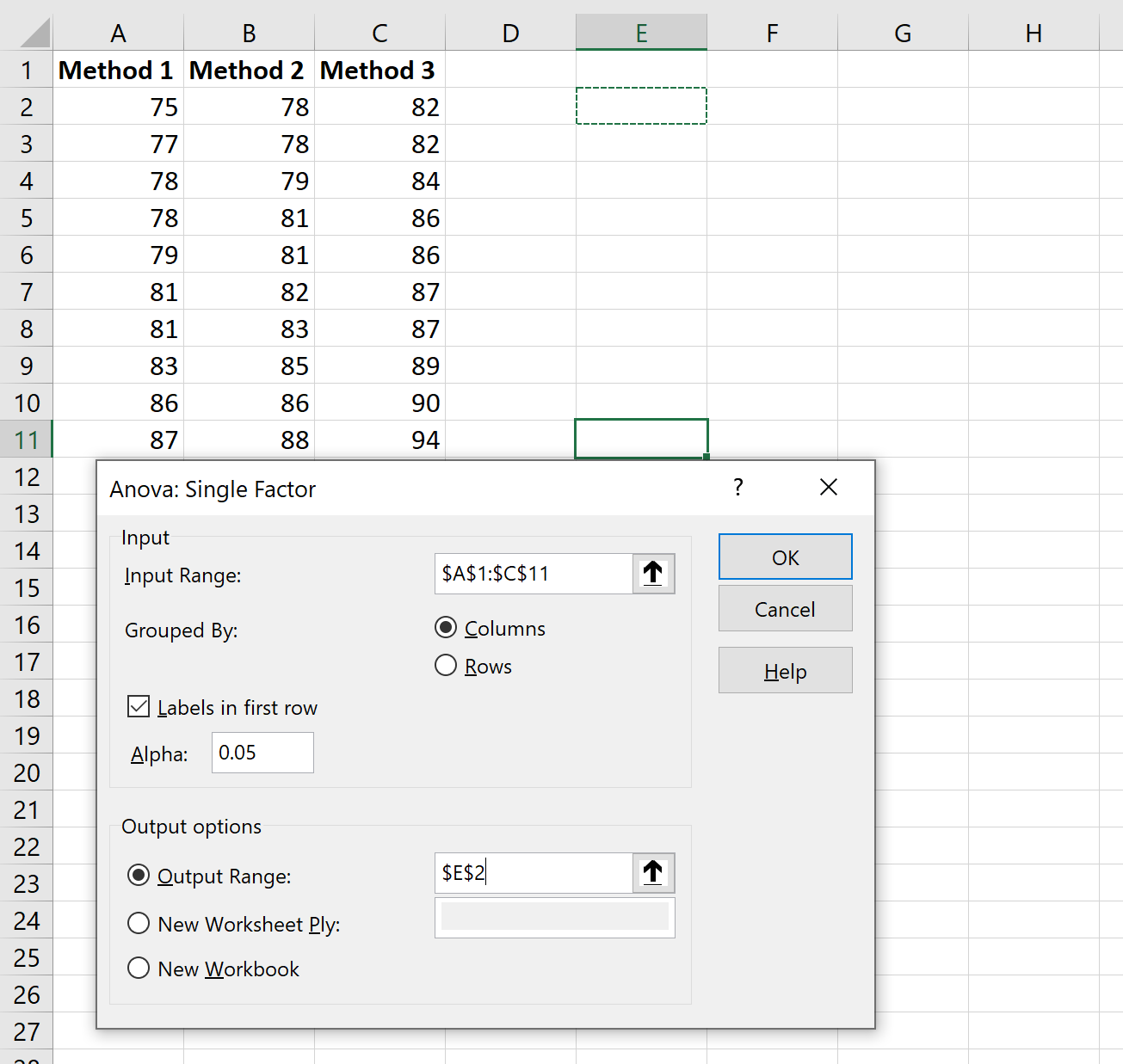
[OK]をクリックすると、一元配置分散分析の結果が表示されます。
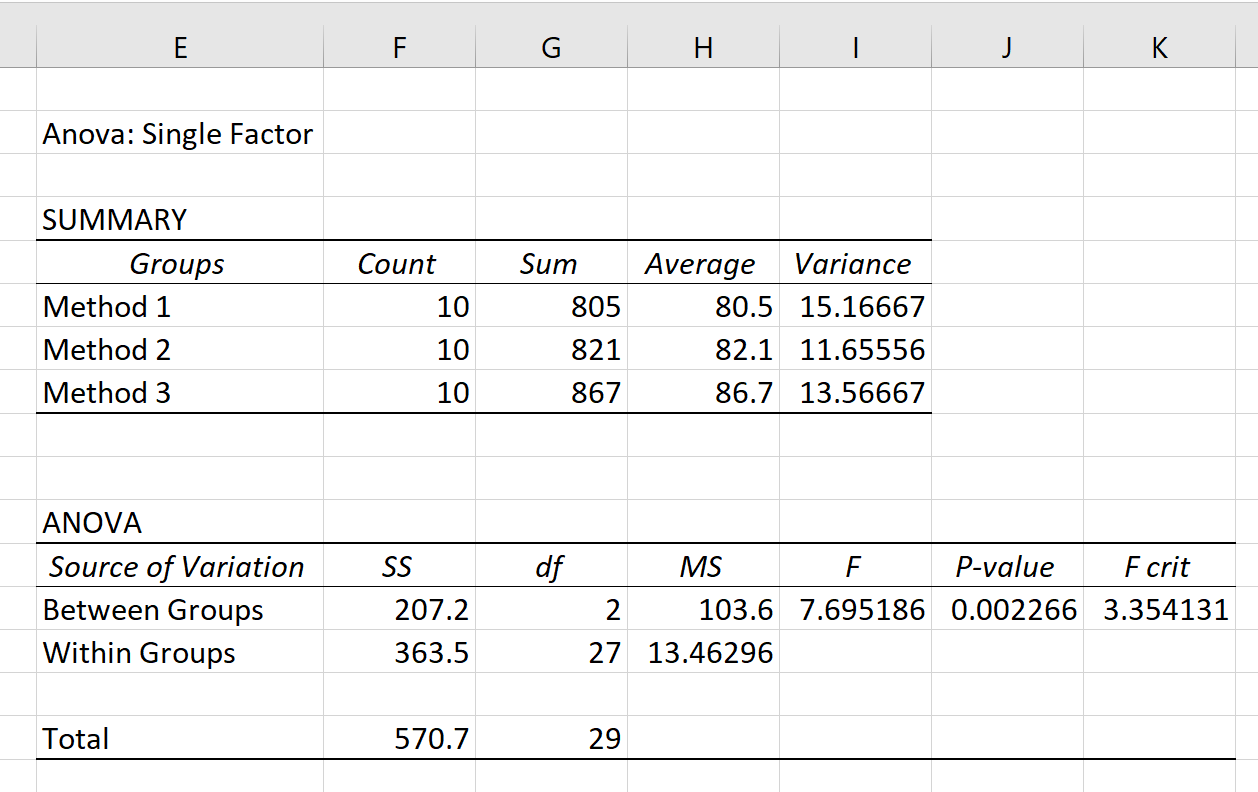
結果には、 SUMMARYとANOVA という2 つの表が表示されます。
各テーブルの値を解釈する方法は次のとおりです。
概要表:
- グループ: グループ名
- Count : 各グループの観測値の数
- Sum : 各グループの値の合計
- Average : 各グループの平均値
- 分散: 各グループ内の値の分散
この表は、ANOVA で使用される各グループのいくつかの有用な要約統計量を提供します。
この表から、方法 3 を使用した生徒は、試験の平均スコアが最も高く (86.7) ましたが、テストのスコアの分散も最も高かったことがわかります。レビュー (13.56667)。
グループ平均の差が統計的に有意かどうかを判断するには、ANOVA 表を参照する必要があります。
分散分析テーブル:
- 変動のソース: 測定された変動 (グループ間またはグループ内)
- SS : 各変動要因の二乗和
- df : 自由度。 df Between の場合は #groups-1 、および #observations – df Within の場合は #groups として計算されます。
- MS : SS/df で計算される平均二乗和
- F : 全体の F 値。MS Between / MS Within として計算されます。
- P値: 全体のF値に対応するp値
- F crit : α = 0.05に相当する臨界値F
この表で最も重要な値はp 値で、 0.002266であることがわかります。
一元配置分散分析では次の帰無仮説と対立仮説が使用されることを思い出してください。
- H 0 : すべてのグループ平均が等しい。
- H A : すべてのグループの平均が等しいわけではありません。
p 値は α = 0.05 より小さいため、一元配置分散分析の帰無仮説を棄却し、すべてのグループ平均が等しくないことを示す十分な証拠があると結論付けます。
これは、3 つの勉強方法すべてが同じ試験平均点につながるわけではないことを意味します。
注: 全体の F 値と臨界 F 値を比較して、帰無仮説を棄却すべきかどうかを判断することもできます。この場合、F の全体値が F の臨界値より大きいため、帰無仮説は棄却されます。 p 値アプローチと臨界 F 値アプローチは常に同じ結論に至ることに注意してください。
追加リソース
次のチュートリアルでは、Excel でさまざまな ANOVA を実行する方法を説明します。
Excel で一元配置分散分析を実行する方法
Excel で二元配置分散分析を実行する方法
Excel で反復測定 ANOVA を実行する方法
Excel でネストされた ANOVA を実行する方法
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る