Googleスプレッドシートでlogest関数を使用する方法(例付き)
Google スプレッドシートでLOGEST関数を使用すると、データに適合する指数曲線の式を計算できます。
曲線の方程式は次の形式になります。
y = b* mx
この関数は次の基本構文を使用します。
= LOGEST ( known_data_y, [known_data_x], [b], [verbose] )
金:
- known_data_y : 既知の y 値の配列
- known_data_x : 既知の x 値の配列
- b : オプションの引数。 TRUE の場合、定数 b は通常どおり処理されます。 FALSE の場合、定数 b は 1 に設定されます。
- verbose : オプションの引数。 TRUE の場合、追加の回帰統計が返されます。 FALSE の場合、追加の回帰統計は返されません。
次のステップバイステップの例は、この関数を実際に使用する方法を示しています。
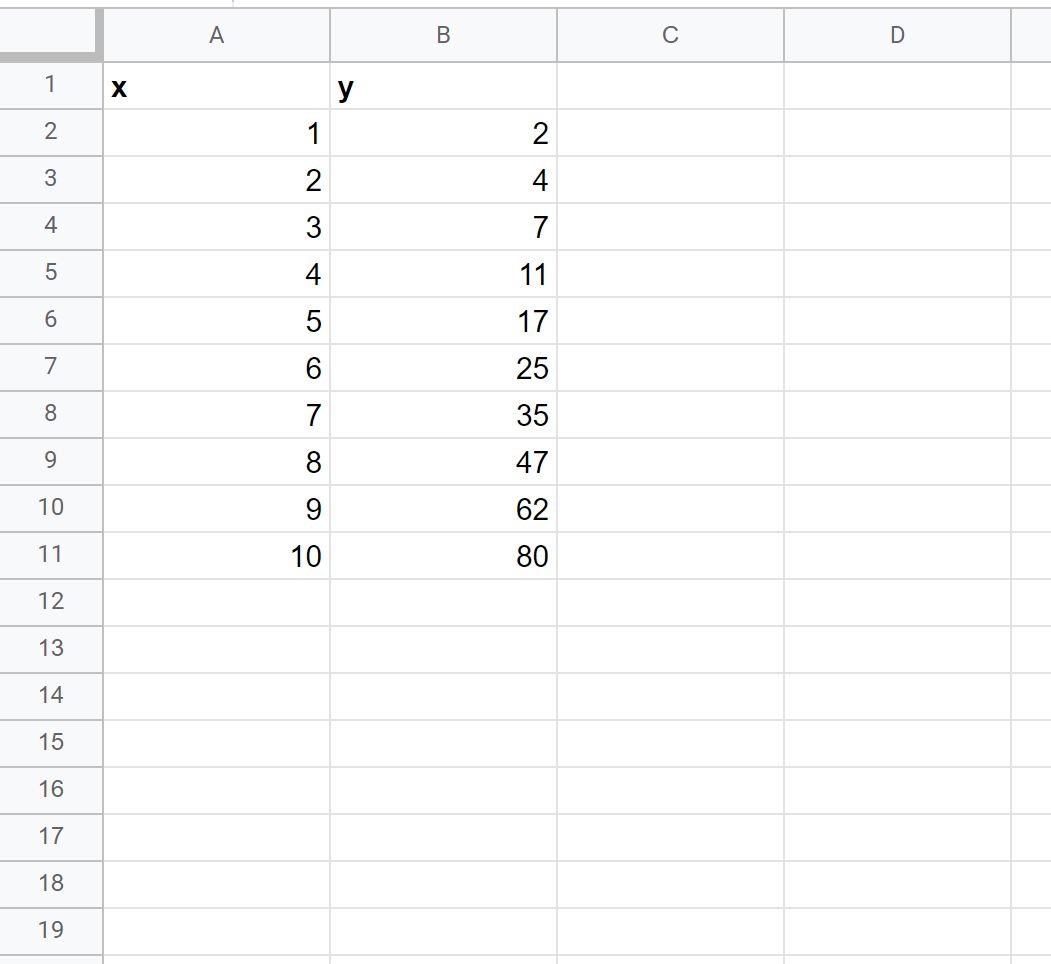
ステップ 1: データを入力する
まず、次のデータセットを Google スプレッドシートに入力してみましょう。
ステップ 2: データを視覚化する
次に、x と y の簡単な散布図を作成して、データが実際に指数曲線に従っていることを確認しましょう。
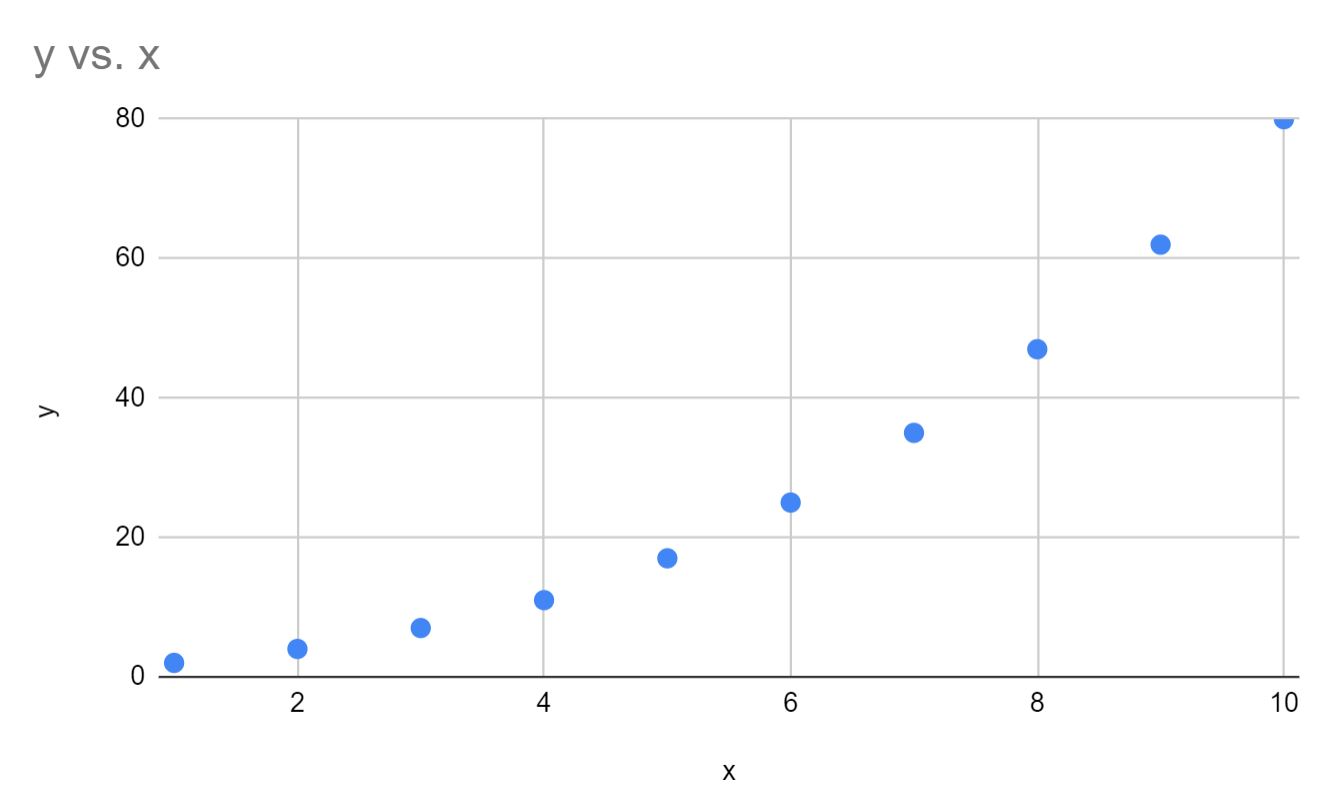
データが実際に指数曲線に従っていることがわかります。
ステップ 3: LOGEST を使用して指数曲線の式を見つける
次に、任意のセルに次の式を入力して、指数曲線の式を計算します。
=LOGEST( B2:B11 , A2:A11 )
次のスクリーンショットは、この式を実際に使用する方法を示しています。
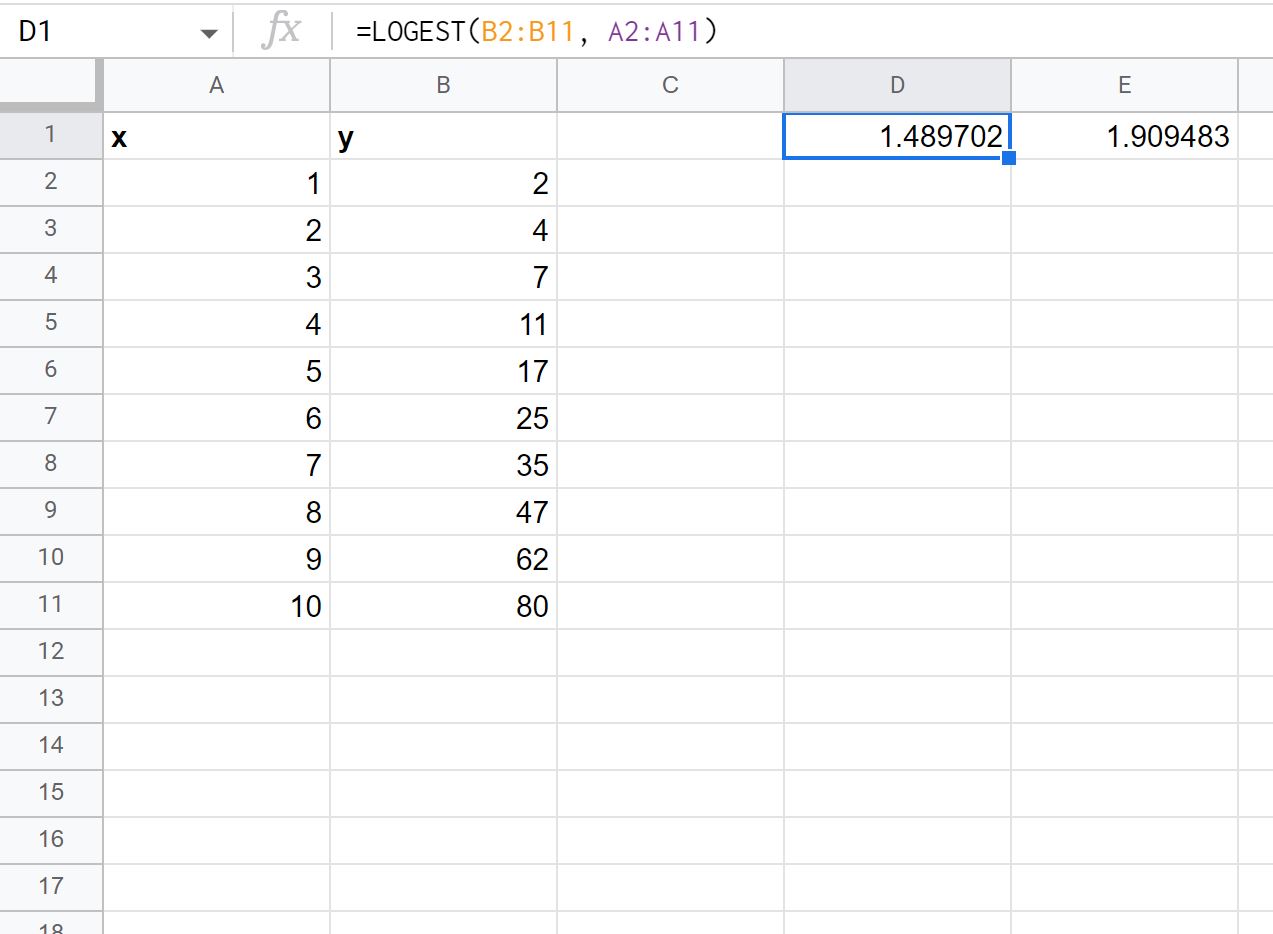
出力の最初の値は次の式のmの値を表し、出力の 2 番目の値はbの値を表します。
y = b* mx
したがって、この指数曲線の式は次のように書きます。
y = 1.909483 * 1.489702x
この式を使用して、x の値に基づいて y の値を予測できます。
たとえば、 xa の値が 8 の場合、 y の値は46.31であると予測します。
y = 1.909483 * 1.489702 8 = 46.31
ステップ 4 (オプション): 追加の回帰統計を表示する
LOGEST関数の詳細な引数値をTRUEに設定すると、近似された回帰式の追加の回帰統計が表示されます。
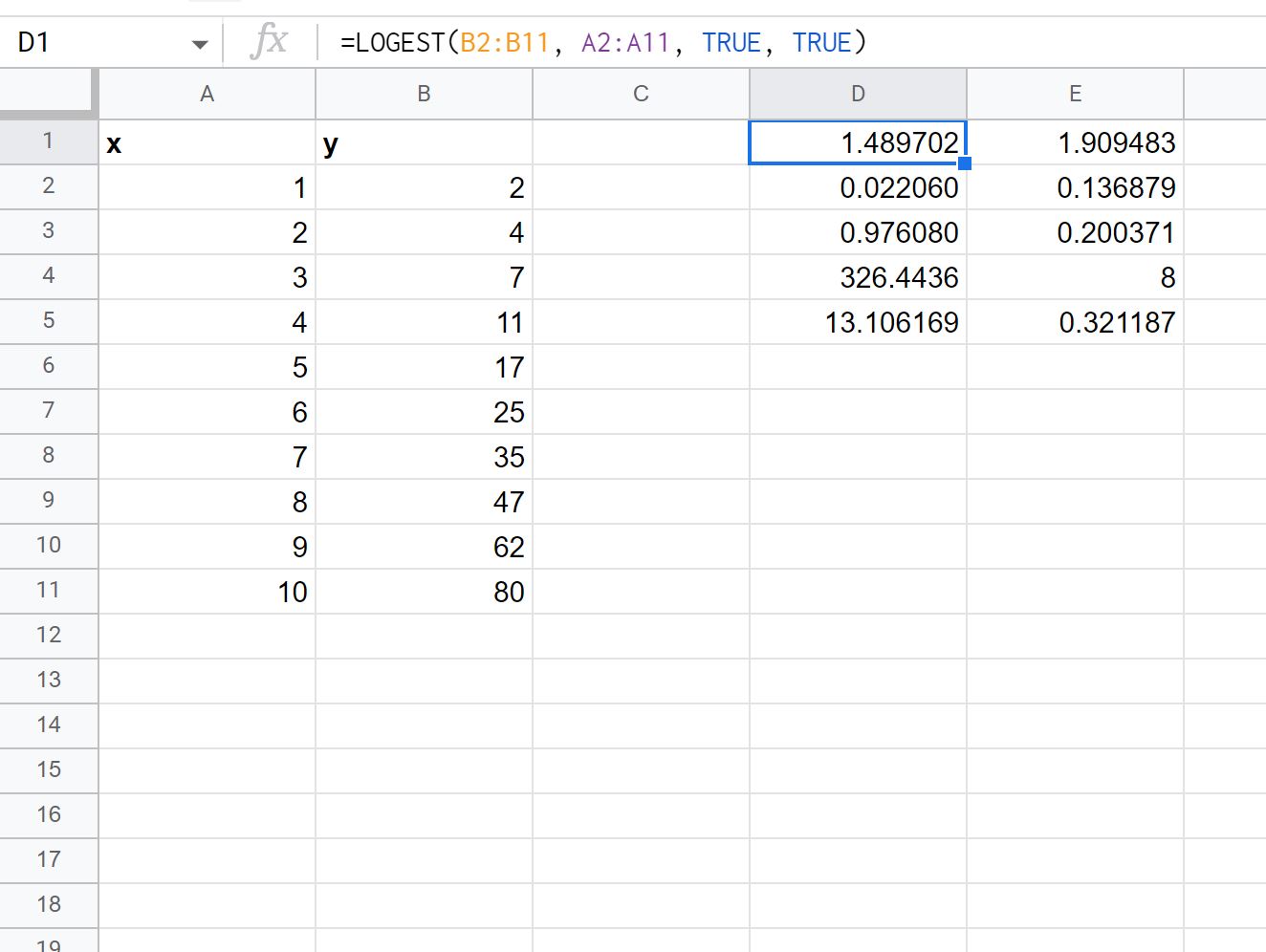
結果の各値を解釈する方法は次のとおりです。
- m の標準誤差は0.02206です。
- b の標準誤差は0.136879です。
- モデルの R 2は.97608です。
- y の標準誤差は.200371です。
- F 統計は326.4436です。
- 自由度は8です。
- 回帰平方和は13.106169です。
- 残りの二乗和は.321187です。
一般に、これらの追加統計で最も重要な尺度は R 2値です。これは、予測変数によって説明できる応答変数の分散の割合を表します。
R 2の値は 0 から 1 まで変化します。
この特定のモデルの R 2 は1 に近いため、予測子変数 x が応答変数 y の値を適切に予測することがわかります。
追加リソース
次のチュートリアルでは、Google スプレッドシートでその他の一般的な操作を行う方法について説明します。
Google スプレッドシートで線形回帰を実行する方法
Googleスプレッドシートで多項式回帰を実行する方法
GoogleスプレッドシートでR二乗を計算する方法
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る