Google スプレッドシート: 2 つの文字の間のテキストを抽出する方法
Google スプレッドシートのREGEXTRACT関数を使用すると、セル内の 2 つの特定の文字の間にあるすべてのテキストを抽出できます。
これを行うには、次の構文を使用できます。
= REGEXEXTRACT ( A2 , " this(.*)that " )
この特定の数式は、セルA2内の文字 “this” と “that” の間のすべてのテキストを抽出します。
次の例は、実際に 2 つの文字の間のテキストを抽出する一般的な方法をいくつか示しています。
例 1: 文字列間のテキストを抽出する
セルB2に次の数式を入力すると、セルA2の文字列「ran」と「miles」の間のテキストを抽出できます。
= REGEXEXTRACT ( A2 , " ran(.*)miles " )
次に、この数式をクリックして、列 B の残りの各セルにドラッグします。
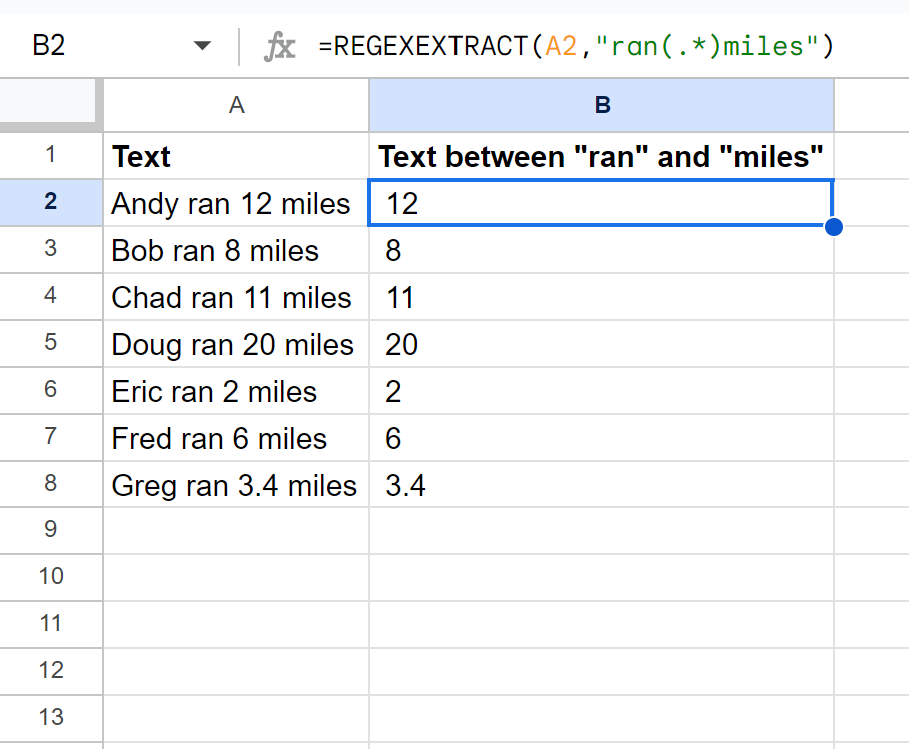
列 B には、列 A の一致する各セルの文字列「ran」と「miles」の間のテキストが含まれます。
例 2:括弧内のテキストを抽出する
セルB2に次の数式を入力すると、セルA2から括弧内のテキストを抽出できます。
= REGEXEXTRACT ( A2 , "" )

次に、この数式をクリックして、列 B の残りの各セルにドラッグします。
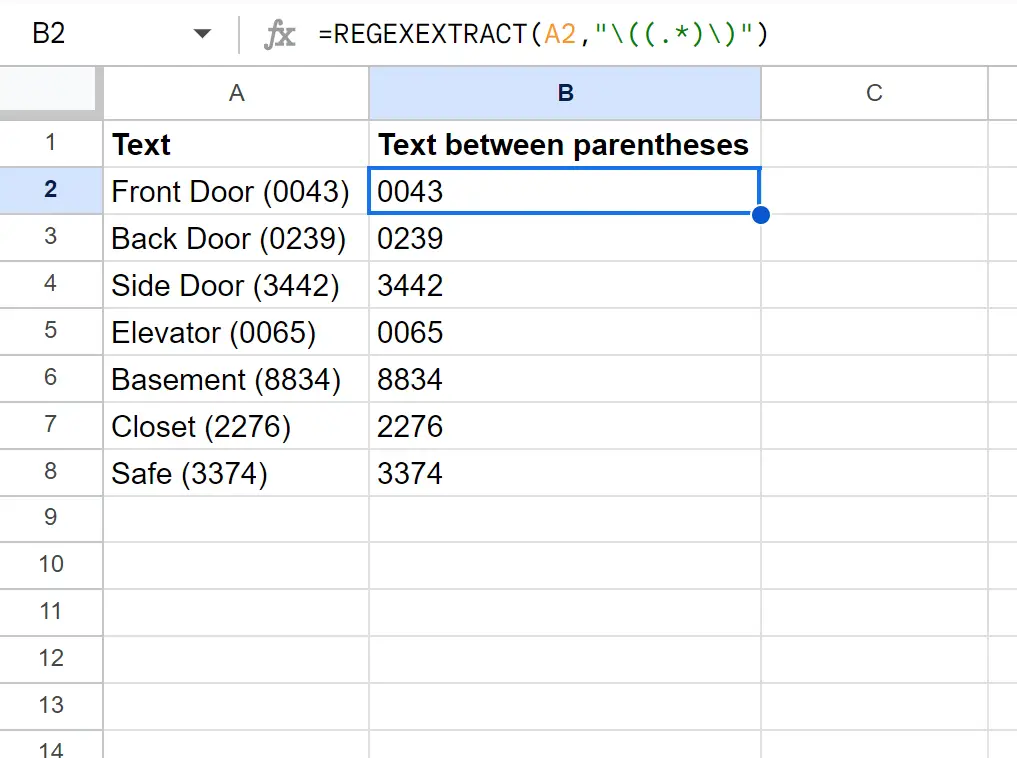
列 B には、列 A の一致する各セルの括弧内のテキストが含まれます。
注: REGEXTRACT関数がこれらの文字を括弧として認識するには、括弧の前にスラッシュをエスケープ文字として使用する必要がありました。
例 3:アスタリスク間のテキストを抽出する
セルB2に次の数式を入力すると、セルA2のアスタリスク間のテキストを抽出できます。
= REGEXEXTRACT ( A2 , " \*(.*)\* " )
次に、この数式をクリックして、列 B の残りの各セルにドラッグします。
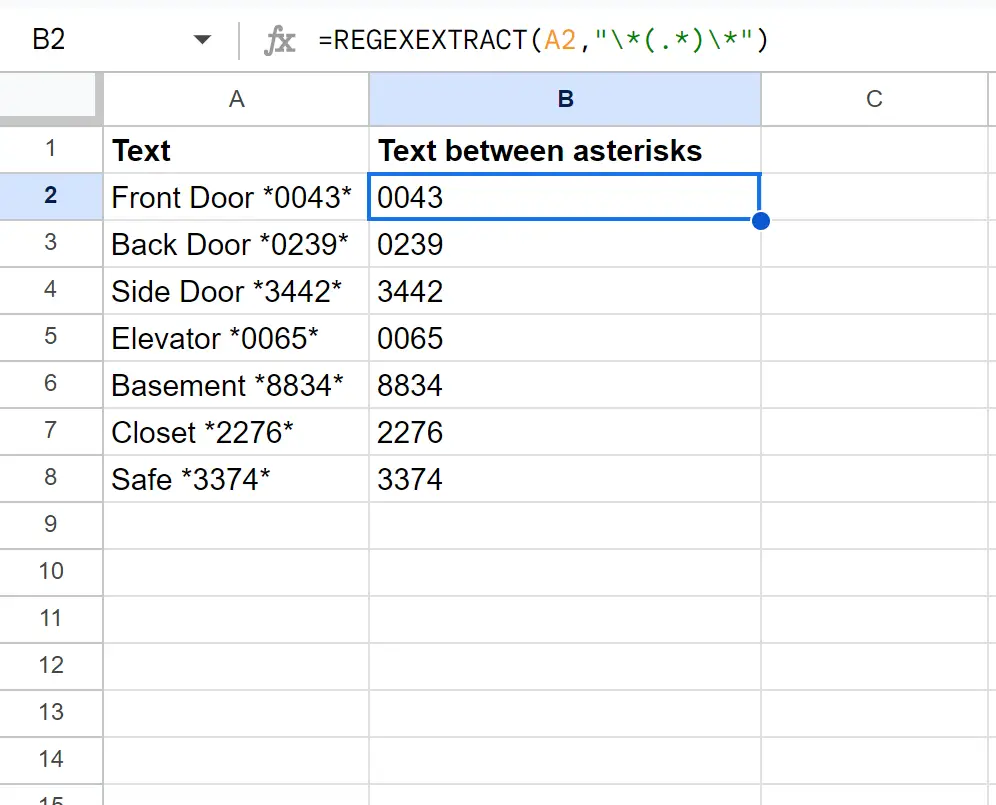
列 B には、列 A 内の一致する各セルのアスタリスク間のテキストが含まれます。
注: REGEXTRACT関数でアスタリスクをアスタリスクとして認識するには、アスタリスクの前にスラッシュをエスケープ文字として使用する必要がありました。
追加リソース
次のチュートリアルでは、Google スプレッドシートで他の一般的なタスクを実行する方法を説明します。
Google スプレッドシート: 文字の後のテキストを抽出する方法
Google スプレッドシート: 文字の前のテキストを抽出する方法
Google スプレッドシート: セルにリスト テキストが含まれているかどうかを確認する
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る