Mse vs. rmse: どの指標を使用する必要がありますか?
回帰モデルは、1 つ以上の予測変数と応答変数の間の関係を定量化するために使用されます。
回帰モデルを当てはめるときは常に、モデルが予測変数の値をどの程度うまく使用して応答変数の値を予測できるかを理解したいと考えます。
モデルがデータセットにどの程度適合しているかを定量化するためによく使用される 2 つの指標は、平均二乗誤差 (MSE) と二乗平均平方根誤差 (RMSE) です。これらは次のように計算されます。
MSE : データセット内の予測値と実際の値の間の二乗平均平方根の差を示す指標。 MSE が低いほど、モデルはデータセットに適合します。
MSE = Σ(ŷ i – y i ) 2 / n
金:
- Σは「和」を意味する記号です
- ŷ iは i番目の観測値の予測値です
- y iはi 番目の観測値の観測値です
- n はサンプルサイズです
RMSE : データセット内の予測値と実際の値の間の二乗平均平方根の差の平方根を示す指標。 RMSE が低いほど、モデルはデータセットに適合します。
次のように計算されます。
RMSE = √ Σ(ŷ i – y i ) 2 / n
金:
- Σは「和」を意味する記号です
- ŷ iは i番目の観測値の予測値です
- y iはi 番目の観測値の観測値です
- n はサンプルサイズです
式はほぼ同じであることに注意してください。実際、平均二乗誤差は平均二乗誤差の平方根にすぎません。
RMSE 対MSE: どの指標を使用する必要がありますか?
モデルがデータセットにどの程度適合しているかを評価するには、 RMSE が応答変数と同じ単位で測定されるため、RMSE を使用することが多くなります。
逆に、MSE は応答変数の平方単位で測定されます。
これを説明するために、回帰モデルを使用して、バスケットボールの試合で 10 人の選手が何点を獲得するかを予測するとします。
次の表は、モデルによって予測されたポイントとプレーヤーが獲得した実際のポイントを比較したものです。
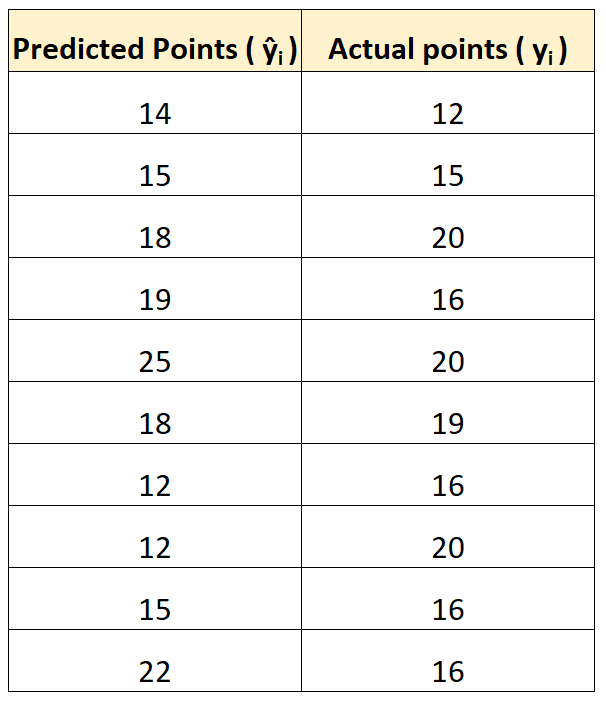
平均二乗誤差 (MSE) は次のように計算します。
- MSE = Σ(ŷ i – y i ) 2 / n
- MSE = ((14-12) 2 +(15-15) 2 +(18-20) 2 +(19-16) 2 +(25-20) 2 +(18-19) 2 +(12-16) 2 +(12-20) 2 +(15-16) 2 +(22-16) 2 ) / 10
- MSE = 16
二乗平均平方根誤差は16です。これは、モデルによって予測された値と実際の値の間の二乗平均平方根の差が 16 であることを示しています。
二乗平均平方根誤差 (RMSE) は、単純に MSE の平方根になります。
- ADE = √ EQM
- RMSE = √ 16
- RMSE = 4
平均二乗誤差は4です。これは、予測得点と実際の得点の間の平均偏差が 4 であることを示しています。
「得点の二乗」ではなく「得点」について話しているため、平均二乗誤差の解釈は平均二乗誤差よりもはるかに簡単であることに注意してください。
RMSEを実際に使用する方法
実際には、通常、重回帰モデルをデータセットに適合させ、各モデルの二乗平均平方根誤差 (RMSE) を計算します。
次に、RMSE 値が最も低いモデルを「最良の」モデルとして選択します。これは、データセット内の実際の値に最も近い予測を行うモデルだからです。
各モデルの MSE 値を比較することもできますが、RMSE の方が解釈しやすいため、より頻繁に使用されることに注意してください。
追加リソース
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る