Python でスチューデント化残差を計算する方法
スチューデント残差は、単に残差をその推定標準偏差で割ったものです。
実際には、一般に、データセット内のスチューデント残差が絶対値 3 より大きい観測値は外れ値であると言われます。
Python では、次の構文を使用する statsmodels のOLSResults.outlier_test()関数を使用して、回帰モデルのスチューデント化残差をすばやく取得できます。
OLSResults.outlier_test()
ここで、OLSResults は、 statsmodels ols()関数を使用して近似した線形モデルの名前です。
例: Python でのスチューデント化残差の計算
次の単純な線形回帰モデルを Python で構築するとします。
#import necessary packages and functions import numpy as np import pandas as pd import statsmodels. api as sm from statsmodels. formula . api import ols #create dataset df = pd. DataFrame ({'rating': [90, 85, 82, 88, 94, 90, 76, 75, 87, 86], 'points': [25, 20, 14, 16, 27, 20, 12, 15, 14, 19]}) #fit simple linear regression model model = ols('rating ~ points', data=df). fit ()
outlier_test()関数を使用して、データセット内の各観測値のスチューデント化された残差を含む DataFrame を生成できます。
#calculate studentized residuals stud_res = model. outlier_test () #display studentized residuals print(stud_res) student_resid unadj_p bonf(p) 0 -0.486471 0.641494 1.000000 1 -0.491937 0.637814 1.000000 2 0.172006 0.868300 1.000000 3 1.287711 0.238781 1.000000 4 0.106923 0.917850 1.000000 5 0.748842 0.478355 1.000000 6 -0.968124 0.365234 1.000000 7 -2.409911 0.046780 0.467801 8 1.688046 0.135258 1.000000 9 -0.014163 0.989095 1.000000
この DataFrame には、データセット内の各観測値の次の値が表示されます。
- 学生化された残留物
- スチューデント化残差の未調整の p 値
- ボンフェローニ補正されたスチューデント残差の p 値
データセット内の最初の観測値のスチューデント化残差は-0.486471 、2 番目の観測値のスチューデント化残差は-0.491937であることがわかります。
対応するスチューデント化残差に対する予測子変数の値の簡単なプロットを作成することもできます。
import matplotlib. pyplot as plt #define predictor variable values and studentized residuals x = df[' points '] y = stud_res[' student_resid '] #create scatterplot of predictor variable vs. studentized residuals plt. scatter (x,y) plt. axhline (y=0, color=' black ', linestyle=' -- ') plt. xlabel (' Points ') plt. ylabel (' Studentized Residuals ')
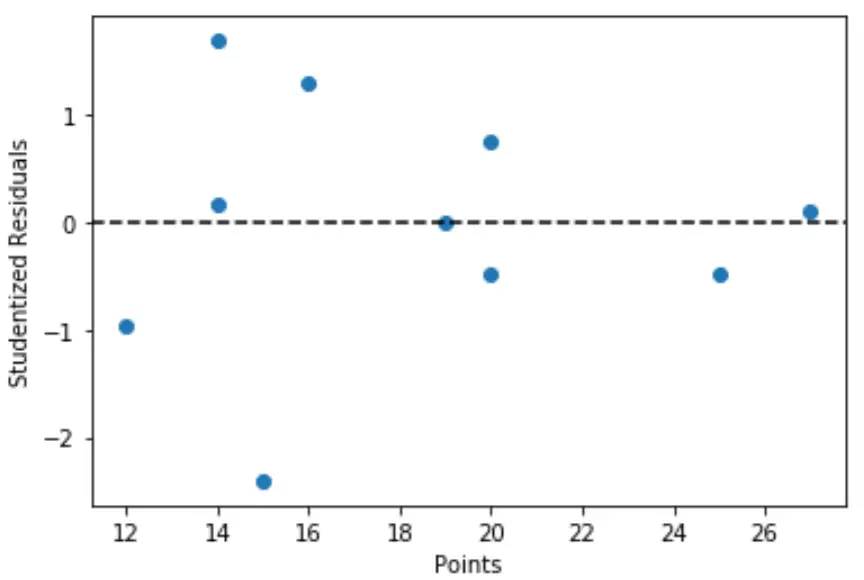
グラフから、絶対値が 3 を超えるスチューデント残差を持つ観測値は存在しないため、データセットには明確な外れ値が存在しないことがわかります。
追加リソース
Python で単純な線形回帰を実行する方法
Python で重回帰を実行する方法
Python で残差プロットを作成する方法
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る