Python で共分散行列を作成する方法
共分散は、 1 つの変数の変化が 2 番目の変数の変化とどのように関連しているかを示す尺度です。より具体的には、これは 2 つの変数が線形に関連している程度の尺度です。
共分散行列は、多くの異なる変数間の共分散を示す正方行列です。これは、データ セット内でさまざまな変数がどのように関連しているかを理解するのに役立ちます。
次の例は、Python で共分散行列を作成する方法を示しています。
Python で共分散行列を作成する方法
Python で共分散行列を作成するには、次の手順を使用します。
ステップ 1: データセットを作成します。
まず、数学、科学、歴史の 3 つの科目における 10 人の異なる生徒のテストのスコアを含むデータセットを作成します。
import numpy as np math = [84, 82, 81, 89, 73, 94, 92, 70, 88, 95] science = [85, 82, 72, 77, 75, 89, 95, 84, 77, 94] history = [97, 94, 93, 95, 88, 82, 78, 84, 69, 78] data = np.array([math, science, history])
ステップ 2: 共分散行列を作成します。
次に、母集団の共分散行列を計算できるように、 bias = Trueを指定して numpy cov()関数を使用してこのデータセットの共分散行列を作成します。
np.cov(data, bias= True )
array([[ 64.96, 33.2, -24.44],
[33.2, 56.4, -24.1],
[-24.44, -24.1, 75.56]])
ステップ 3: 共分散行列を解釈します。
マトリックスの対角に沿った値は、単に各被験者の分散です。例えば:
- 数学の得点の分散は 64.96 です
- 科学の得点の分散は 56.4 です
- 過去のスコア分散は 75.56 です
行列の他の値は、異なる被験者間の共分散を表します。例えば:
- 数学と科学のスコア間の共分散は 33.2 です。
- 数学と歴史のスコア間の共分散は -24.44 です。
- 科学スコアと歴史スコアの間の共分散は -24.1 です。
共分散の正の数は、 2 つの変数が並行して増加または減少する傾向があることを示します。たとえば、数学と科学には正の共分散 (33.2) があり、数学の得点が高い生徒は科学の得点も高い傾向があることを示しています。逆に、数学の成績が悪い生徒は、科学の成績も悪い傾向があります。
共分散の負の値は、 1 つの変数が増加すると、2 番目の変数が減少する傾向があることを示します。たとえば、数学と歴史には負の共分散 (-24.44) があり、数学の得点が高い生徒は歴史の得点が低い傾向があることを示しています。逆に、数学の得点が低い生徒は歴史の得点が高くなる傾向があります。
ステップ 4: 共分散行列を視覚化します (オプション)。
seaborn パッケージのheatmap()関数を使用して共分散行列を視覚化できます。
import seaborn as sns import matplotlib.pyplot as plt cov = np.cov(data, bias=True) labs = ['math', 'science', 'history'] sns.heatmap(cov, annot=True, fmt='g', xticklabels=labs, yticklabels=labs) plt.show()
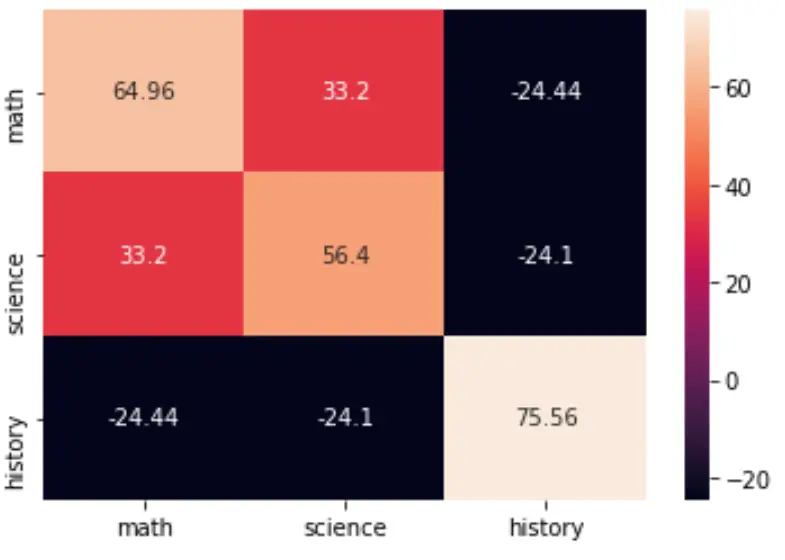
cmap引数を指定してカラー パレットを変更することもできます。
sns.heatmap(cov, annot=True, fmt='g', xticklabels=labs, yticklabels=labs, cmap=' YlGnBu ')
plt.show()
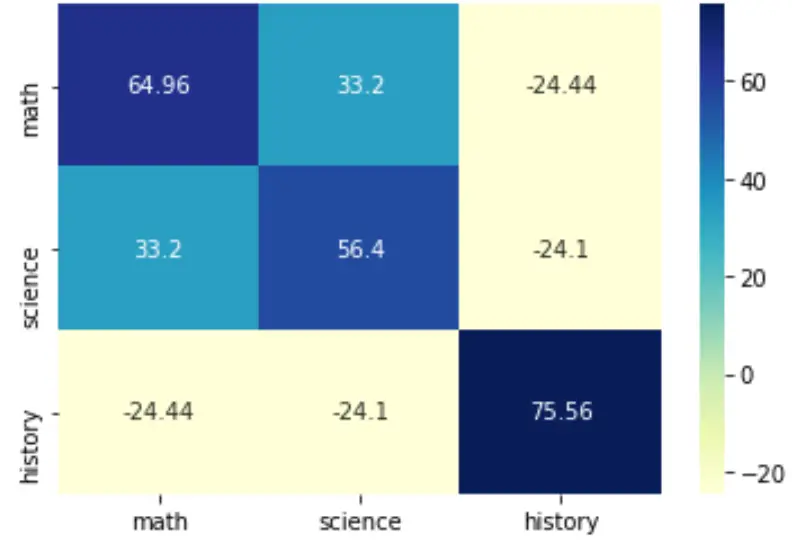
このヒートマップのスタイル設定方法の詳細については、 seaborn のドキュメントを参照してください。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る