R でデータを中央に配置する方法 (例付き)
データセットを中央に配置するということは、データセット内の個々の観測値の平均値を減算することを意味します。
たとえば、次のデータセットがあるとします。
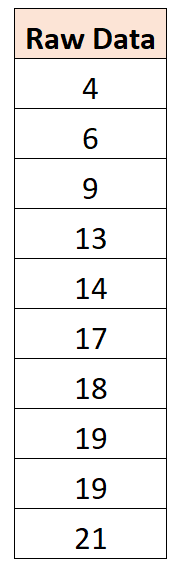
平均値は 14 であることがわかります。したがって、このデータセットを中心にするには、個々の観測値から 14 を減算します。
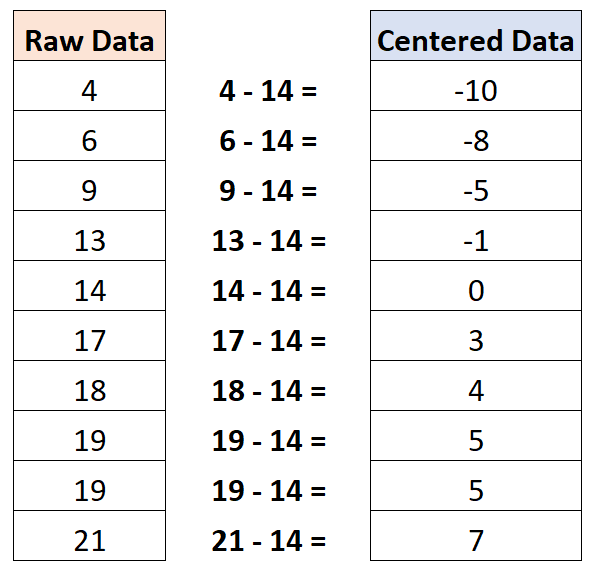
中心にあるデータセットの平均値はゼロであることに注意してください。
このチュートリアルでは、R でデータを中央に配置する方法の例をいくつか示します。
例 1: ベクトルの値を中央に配置する
次のコードは、基本Rscale()関数を使用してベクトル内の値を中央に配置する方法を示しています。
#createvector data <- c(4, 6, 9, 13, 14, 17, 18, 19, 19, 21) #subtract the mean value from each observation in the vector scale(data, scale= FALSE ) [,1] [1,] -10 [2,] -8 [3,] -5 [4,] -1 [5,] 0 [6,] 3 [7,] 4 [8,] 5 [9,] 5 [10,] 7 attr(,"scaled:center") [1] 14
結果の値は、データセットの中心の値です。また、scale() 関数は、データセットの平均値が 14 であることを示します。
デフォルトでは、 scale()関数は個々の観測値から平均値を減算し、それを標準偏差で割ることに注意してください。
scale=FALSEを指定することで、R に標準偏差で除算しないように指示します。
例 2: データ フレーム内の列を中央に配置する
次のコードは、R データベースのsapply()関数とscale()関数を使用して、データ フレームの各列の値を中央に配置する方法を示しています。
#create data frame df <- data.frame(x = c(1, 4, 5, 6, 6, 8, 9), y = c(7, 7, 8, 8, 8, 9, 12), z = c(3, 3, 4, 4, 6, 7, 7)) #center each column in the data frame df_new <- sapply(df, function (x) scale(x, scale= FALSE )) #display data frame df_new X Y Z [1,] -4.5714286 -1.4285714 -1.8571429 [2,] -1.5714286 -1.4285714 -1.8571429 [3,] -0.5714286 -0.4285714 -0.8571429 [4,] 0.4285714 -0.4285714 -0.8571429 [5,] 0.4285714 -0.4285714 1.1428571 [6,] 2.4285714 0.5714286 2.1428571 [7,] 3.4285714 3.5714286 2.1428571
ColMeans()関数を使用して、新しいデータ フレームの各列の平均がゼロであることを確認できます。
colMeans(df_new)
xyz 2.537653e-16 -2.537653e-16 3.806479e-16
値は科学的表記法で表示されますが、それぞれの値は基本的にゼロです。
追加リソース
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る