Rでcsvファイルから特定の行を読み取る方法
次のメソッドを使用して、R の CSV ファイルから特定の行を読み取ることができます。
方法 1: 特定の行から CSV ファイルをインポートする
df <- read. csv (" my_data.csv ", skip= 2 )
この特定の例では、CSV ファイルの最初の 2 行をスキップし、3 行目以降のファイルの他のすべての行をインポートします。
方法 2: 条件を満たす行の CSV ファイルをインポートする
library (sqldf) df <- read. csv . sql (" my_data.csv ", sql = " select * from file where `points` > 90 ", eol = " \n ")
この特定の例では、「ポイント」列の値が 90 を超える行のみを CSV ファイルからインポートします。
次の例は、 my_data.csvという CSV ファイルを使用してこれらの各メソッドを実際に使用する方法を示しています。
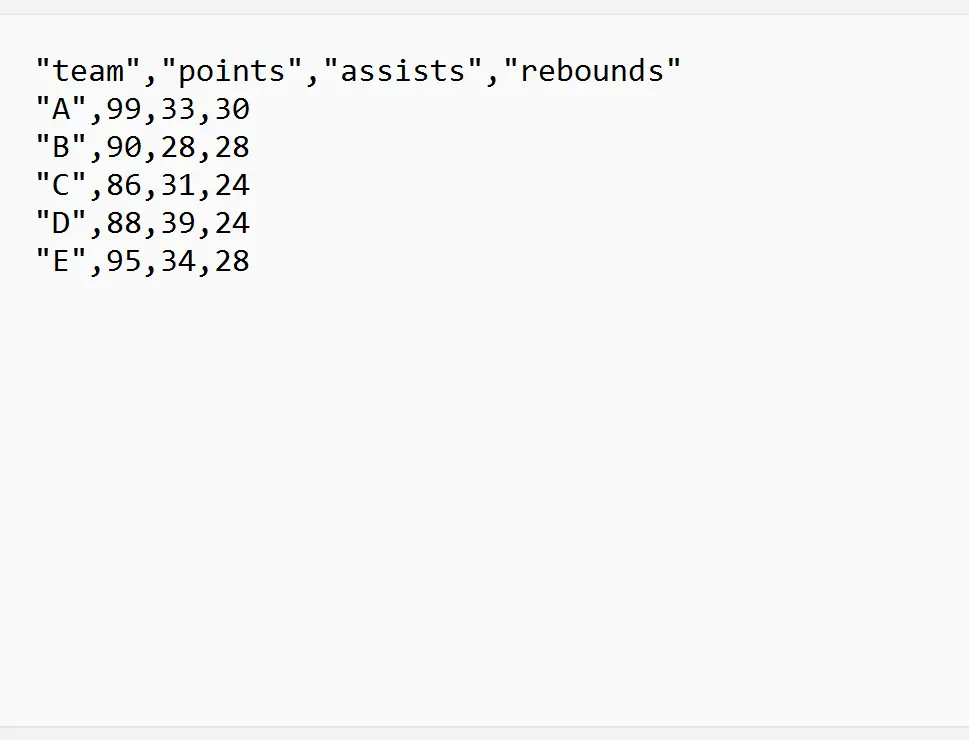
例 1: 特定の行から CSV ファイルをインポートする
次のコードは、CSV ファイルをインポートし、ファイルの最初の 2 行を無視する方法を示しています。
#import data frame and skip first two rows
df <- read. csv (' my_data.csv ', skip= 2 )
#view data frame
df
B X90 X28 X28.1
1 C 86 31 24
2 D 88 39 24
3 E 95 34 28
CSV ファイルをインポートするときに、最初の 2 行 (チーム A と B) が無視されることに注意してください。
デフォルトでは、R は次に利用可能な行の値を列名として使用しようとします。
列の名前を変更するには、次のようにnames()関数を使用します。
#rename columns
names(df) <- c(' team ', ' points ', ' assists ', ' rebounds ')
#view updated data frame
df
team points assists rebounds
1 C 86 31 24
2 D 88 39 24
3 E 95 34 28
例2: 条件を満たす行のCSVファイルをインポートする
CSV ファイルからポイント列の値が 90 を超える行のみをインポートするとします。
これを行うには、 sqldfパッケージのread.csv.sql関数を使用できます。
library (sqldf)
#only import rows where points > 90
df <- read. csv . sql (" my_data.csv ",
sql = " select * from file where `points` > 90 ", eol = " \n ")
#view data frame
df
team points assists rebounds
1 “A” 99 33 30
2 “E” 95 34 28
「ポイント」列の値が 90 を超える CSV ファイルの 2 行のみがインポートされていることに注意してください。
注 #1 : この例では、 eol引数を使用して、ファイル内の「行末」が改行を表す\nで示されることを指定しました。
注 #2:この例では、単純な SQL クエリを使用しましたが、より複雑なクエリを作成して、さらに多くの条件で行をフィルタリングすることもできます。
追加リソース
次のチュートリアルでは、R で他の一般的なタスクを実行する方法について説明します。
R で URL から CSV を読み取る方法
Rで複数のCSVファイルをマージする方法
R でデータ フレームを CSV ファイルにエクスポートする方法
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る