R でのリッジ回帰 (ステップバイステップ)
リッジ回帰は、データに多重共線性が存在する場合に回帰モデルを近似するために使用できる方法です。
簡単に言うと、最小二乗回帰は、残差二乗和 (RSS) を最小化する係数推定値を見つけようとします。
RSS = Σ(y i – ŷ i )2
金:
- Σ : 和を意味するギリシャ語の記号
- y i : i 番目の観測値の実際の応答値
- ŷ i : 重回帰モデルに基づく予測応答値
逆に、リッジ回帰は以下を最小限に抑えようとします。
RSS + λΣβ j 2
ここで、 jは 1 からp 個の予測子変数であり、λ ≥ 0 です。
方程式のこの 2 番目の項は、撤退ペナルティとして知られています。リッジ回帰では、可能な限り最小の MSE テスト (平均二乗誤差) を生成する λ の値を選択します。
このチュートリアルでは、R でリッジ回帰を実行する方法の段階的な例を示します。
ステップ 1: データをロードする
この例では、 mtcarsという R の組み込みデータセットを使用します。応答変数としてhp を使用し、予測変数として次の変数を使用します。
- mpg
- 重さ
- たわごと
- qsec
リッジ回帰を実行するには、 glmnetパッケージの関数を使用します。このパッケージでは、 応答変数がベクトルであること、および予測子変数のセットがdata.matrixクラスのものであることが必要です。
次のコードは、データを定義する方法を示しています。
#define response variable
y <- mtcars$hp
#define matrix of predictor variables
x <- data.matrix(mtcars[, c('mpg', 'wt', 'drat', 'qsec')])
ステップ 2: リッジ回帰モデルを当てはめる
次に、 glmnet()関数を使用して Ridge 回帰モデルを近似し、 alpha=0を指定します。
アルファを 1 に設定することは Lasso 回帰を使用することと同等であり、アルファを 0 から 1 までの値に設定することはエラスティック ネットを使用することと同等であることに注意してください。
また、リッジ回帰では、各予測変数の平均が 0、標準偏差が 1 になるようにデータを標準化する必要があることにも注意してください。
幸いなことに、 glmnet() はこの標準化を自動的に実行します。すでに変数を標準化している場合は、 standardize=Falseを指定できます。
library (glmnet)
#fit ridge regression model
model <- glmnet(x, y, alpha = 0 )
#view summary of model
summary(model)
Length Class Mode
a0 100 -none- numeric
beta 400 dgCMatrix S4
df 100 -none- numeric
dim 2 -none- numeric
lambda 100 -none- numeric
dev.ratio 100 -none- numeric
nulldev 1 -none- numeric
npasses 1 -none- numeric
jerr 1 -none- numeric
offset 1 -none- logical
call 4 -none- call
nobs 1 -none- numeric
ステップ 3: Lambda の最適な値を選択する
次に、k 分割相互検証を使用して、最小の検定平均二乗誤差 (MSE) を生成するラムダ値を特定します。
幸いなことに、 glmnet には、k = 10 回を使用して k 分割相互検証を自動的に実行するcv.glmnet()関数があります。
#perform k-fold cross-validation to find optimal lambda value
cv_model <- cv. glmnet (x, y, alpha = 0 )
#find optimal lambda value that minimizes test MSE
best_lambda <- cv_model$ lambda . min
best_lambda
[1] 10.04567
#produce plot of test MSE by lambda value
plot(cv_model)
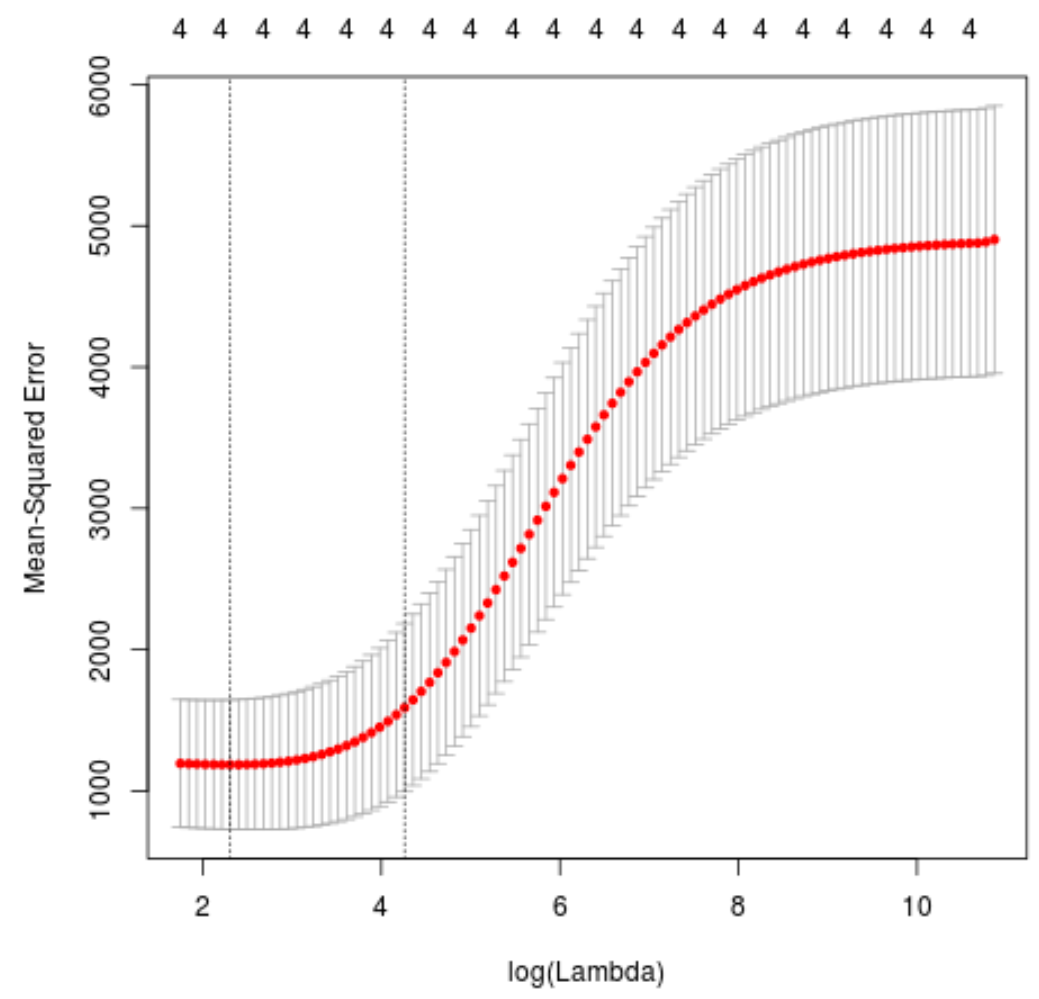
MSE テストを最小化するラムダ値は10.04567であることがわかります。
ステップ 4: 最終モデルを分析する
最後に、最適なラムダ値によって生成された最終モデルを分析できます。
次のコードを使用して、このモデルの係数推定値を取得できます。
#find coefficients of best model
best_model <- glmnet(x, y, alpha = 0 , lambda = best_lambda)
coef(best_model)
5 x 1 sparse Matrix of class "dgCMatrix"
s0
(Intercept) 475.242646
mpg -3.299732
wt 19.431238
drat -1.222429
qsec -17.949721
トレース プロットを作成して、ラムダの増加により係数推定値がどのように変化したかを視覚化することもできます。
#produce Ridge trace plot
plot(model, xvar = " lambda ")
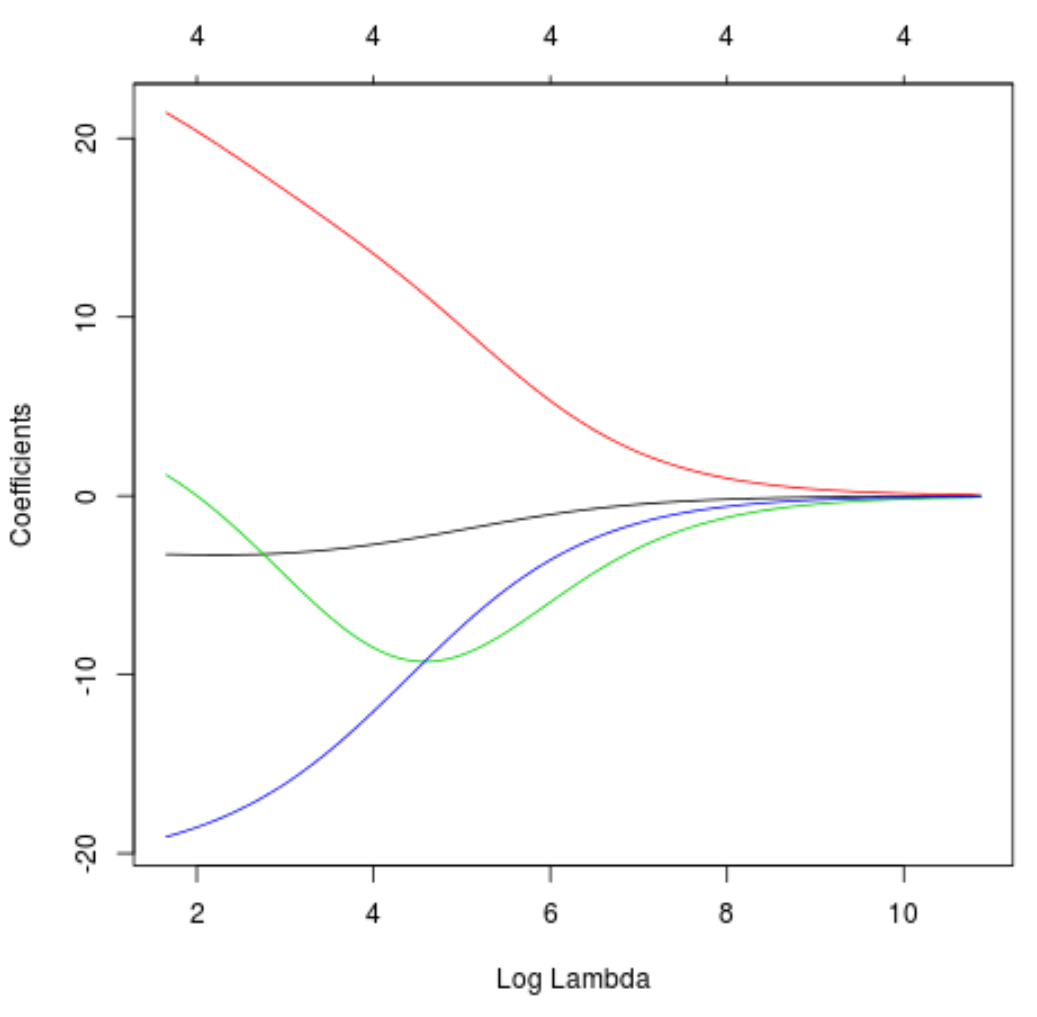
最後に、トレーニング データに対する モデルの R 二乗を計算できます。
#use fitted best model to make predictions
y_predicted <- predict (model, s = best_lambda, newx = x)
#find OHS and SSE
sst <- sum ((y - mean (y))^2)
sse <- sum ((y_predicted - y)^2)
#find R-Squared
rsq <- 1 - sse/sst
rsq
[1] 0.7999513
R の 2 乗は0.7999513であることがわかります。つまり、最良のモデルはトレーニング データの応答値の変動の79.99%を説明できました。
この例で使用されている完全な R コードは、 ここで見つけることができます。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る