R のダイヤモンド データセットの完全ガイド
ダイヤモンドデータセットは、R のggplot2パッケージに組み込まれたデータセットです。
これには、53,940 個の異なるダイヤモンドに関する 10 の異なる変数 (価格、色、透明度など) の測定結果が含まれています。
このチュートリアルでは、R でダイヤモンドデータセットを調査、要約、視覚化する方法について説明します。
ダイヤモンド データセットの読み込み
ダイヤモンドデータセットは ggplot2 の組み込みデータセットであるため、最初に ggplot2 パッケージを (まだインストールしていない場合) インストールして読み込む必要があります。
#install ggplot2 if not already installed
install. packages (' ggplot2 ')
#load ggplot2
library (ggplot2)
ggplot2 をロードしたら、 data()関数を使用してダイヤモンドデータセットをロードできます。
data(diamonds)
head()関数を使用して、データセットの最初の 6 行を確認できます。
#view first six rows of diamonds dataset
head(diamonds)
carat cut color clarity depth table price xyz
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.290 Premium I VS2 62.4 58 334 4.2 4.23 2.63
5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
ダイヤモンド データセットを要約する
summary()関数を使用すると、データセット内の各変数をすばやく要約できます。
#summarize diamonds dataset
summary(diamonds)
carat cut color clarity depth
Min. :0.2000 Fair: 1610 D: 6775 SI1:13065 Min. :43.00
1st Qu.:0.4000 Good: 4906 E: 9797 VS2:12258 1st Qu.:61.00
Median: 0.7000 Very Good: 12082 F: 9542 SI2: 9194 Median: 61.80
Mean: 0.7979 Premium: 13791 G: 11292 VS1: 8171 Mean: 61.75
3rd Qu.:1.0400 Ideal:21551 H:8304 VVS2:5066 3rd Qu.:62.50
Max. :5.0100 I: 5422 VVS1: 3655 Max. :79.00
D: 2808 (Other): 2531
table price xyz Min. :43.00 Min. : 326 Min. : 0.000 Min. : 0.000 Min. : 0.000
1st Qu.: 56.00 1st Qu.: 950 1st Qu.: 4.710 1st Qu.: 4.720 1st Qu.: 2.910
Median: 57.00 Median: 2401 Median: 5.700 Median: 5.710 Median: 3.530
Mean: 57.46 Mean: 3933 Mean: 5.731 Mean: 5.735 Mean: 3.539
3rd Qu.: 59.00 3rd Qu.: 5324 3rd Qu.: 6.540 3rd Qu.: 6.540 3rd Qu.: 4.040
Max. :95.00 Max. :18823 Max. :10,740 Max. :58,900 Max. :31,800
各数値変数について、次の情報を確認できます。
- Min : 最小値。
- 1st Qu : 最初の四分位数 (25 パーセンタイル) の値。
- 中央値: 中央値。
- 平均: 平均値。
- 3rd Qu : 第 3 四分位数 (75 パーセンタイル) の値。
- Max : 最大値。
データセット内のカテゴリ変数 (カット、カラー、透明度) については、各値の頻度数が表示されます。
たとえば、 cut変数の場合は次のようになります。
- Fair : この値は 1,610 回出現します。
- Good : この値は 4,906 回出現します。
- 非常に良い: この値は 12,082 回表示されます。
- プレミアム: この値は 13,791 回出現します。
- Ideal : この値は 21,551 回出現します。
dim()関数を使用して、行数と列数に関してデータセットの次元を取得できます。
#display rows and columns
dim(diamonds)
[1] 53940 10
データセットには53,940行と10列があることがわかります。
names()関数を使用して、データ フレームの列名を表示することもできます。
#display column names
names(diamonds)
[1] "carat" "cut" "color" "clarity" "depth" "table" "price" "x"
[9] “y” “z”
ダイヤモンド データセットを視覚化する
プロットを作成してデータセットの値を視覚化することもできます。
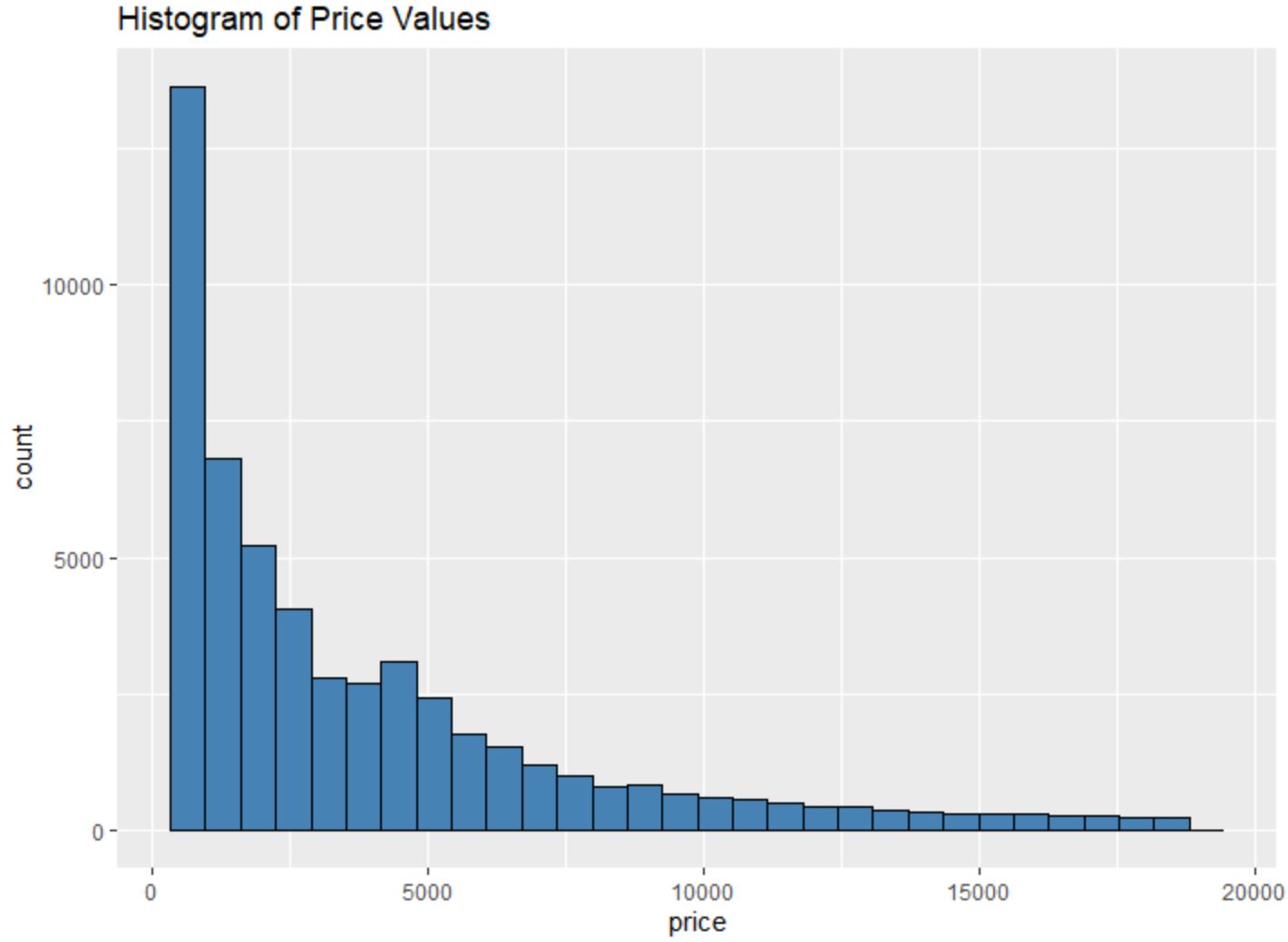
たとえば、 geom_histogram()関数を使用して、特定の変数の値のヒストグラムを作成できます。
#create histogram of values for price
ggplot(data=diamonds, aes (x=price)) +
geom_histogram(fill=" steelblue ", color=" black ") +
ggtitle(" Histogram of Price Values ")
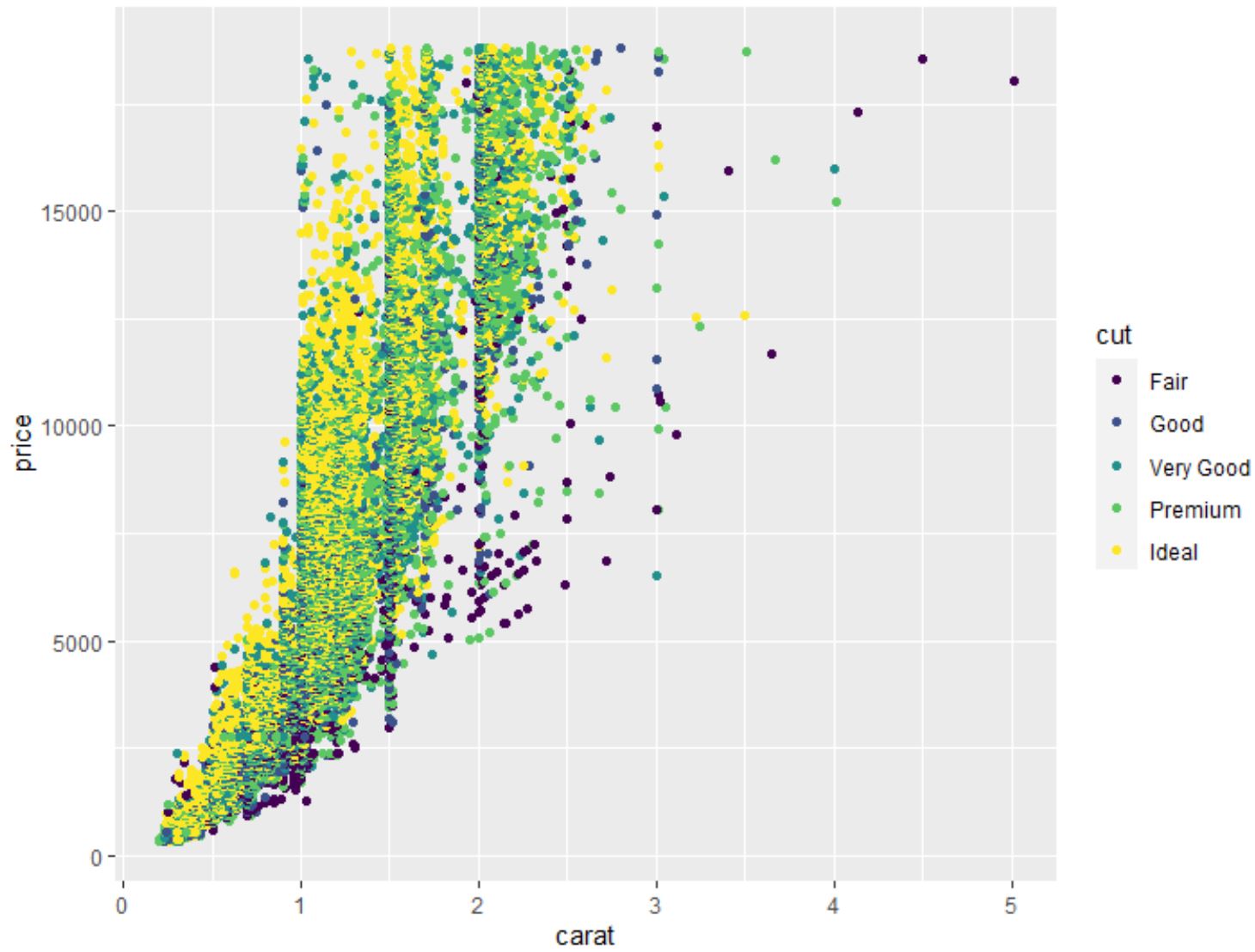
geom_point()関数を使用して、変数のペアごとの組み合わせの点群を作成することもできます。
#create scatterplot of carat vs. price, using cut as color variable
ggplot(data=diamonds, aes (x=carat, y=price, color=cut)) +
geom_point()
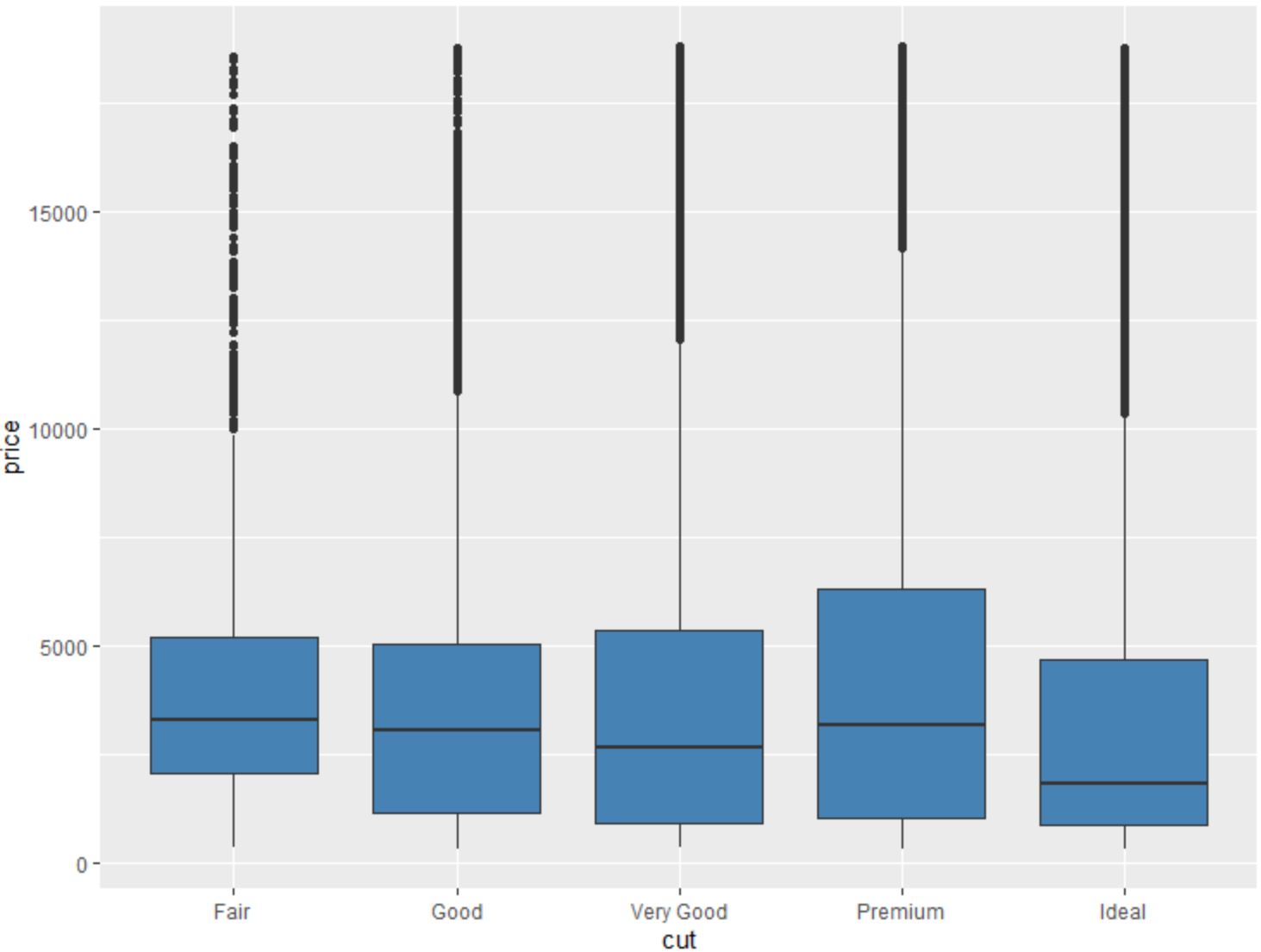
geom_boxplot()関数を使用して、別の変数でグループ化された変数の箱ひげ図を作成することもできます。
#create scatterplot of price, grouped by cut
ggplot(data=diamonds, aes (x=cut, y=price)) +
geom_boxplot(fill=" steelblue ")
これらの ggplot2 関数を使用すると、ダイヤモンドデータセット内の変数について多くのことを学ぶことができます。
追加リソース
次のチュートリアルでは、R で他のデータセットを探索する方法について説明します。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る