R で chow テストを実行する方法
チャウ検定は、異なるデータセット上の 2 つの異なる回帰モデルの係数が等しいかどうかをテストするために使用されます。
このテストは通常、時系列データを使用した計量経済学の分野で、特定の時点でデータに構造的な断絶があるかどうかを判断するために使用されます。
このチュートリアルでは、R で Chow テストを実行する方法の段階的な例を示します。
ステップ 1: データを作成する
まず、偽のデータを作成します。
#create data data <- data.frame(x = c(1, 1, 2, 3, 4, 4, 5, 5, 6, 7, 7, 8, 8, 9, 10, 10, 11, 12, 12, 13, 14, 15, 15, 16, 17, 18, 18, 19, 20, 20), y = c(3, 5, 6, 10, 13, 15, 17, 14, 20, 23, 25, 27, 30, 30, 31, 33, 32, 32, 30, 32, 34, 34, 37, 35, 34, 36, 34, 37, 38, 36)) #view first six rows of data head(data) xy 1 1 3 2 1 5 3 2 6 4 3 10 5 4 13 6 4 15
ステップ 2: データを視覚化する
次に、データを視覚化するための単純な散布図を作成します。
#load ggplot2 visualization package library (ggplot2) #create scatterplot ggplot(data, aes (x = x, y = y)) + geom_point(col=' steelblue ', size= 3 )
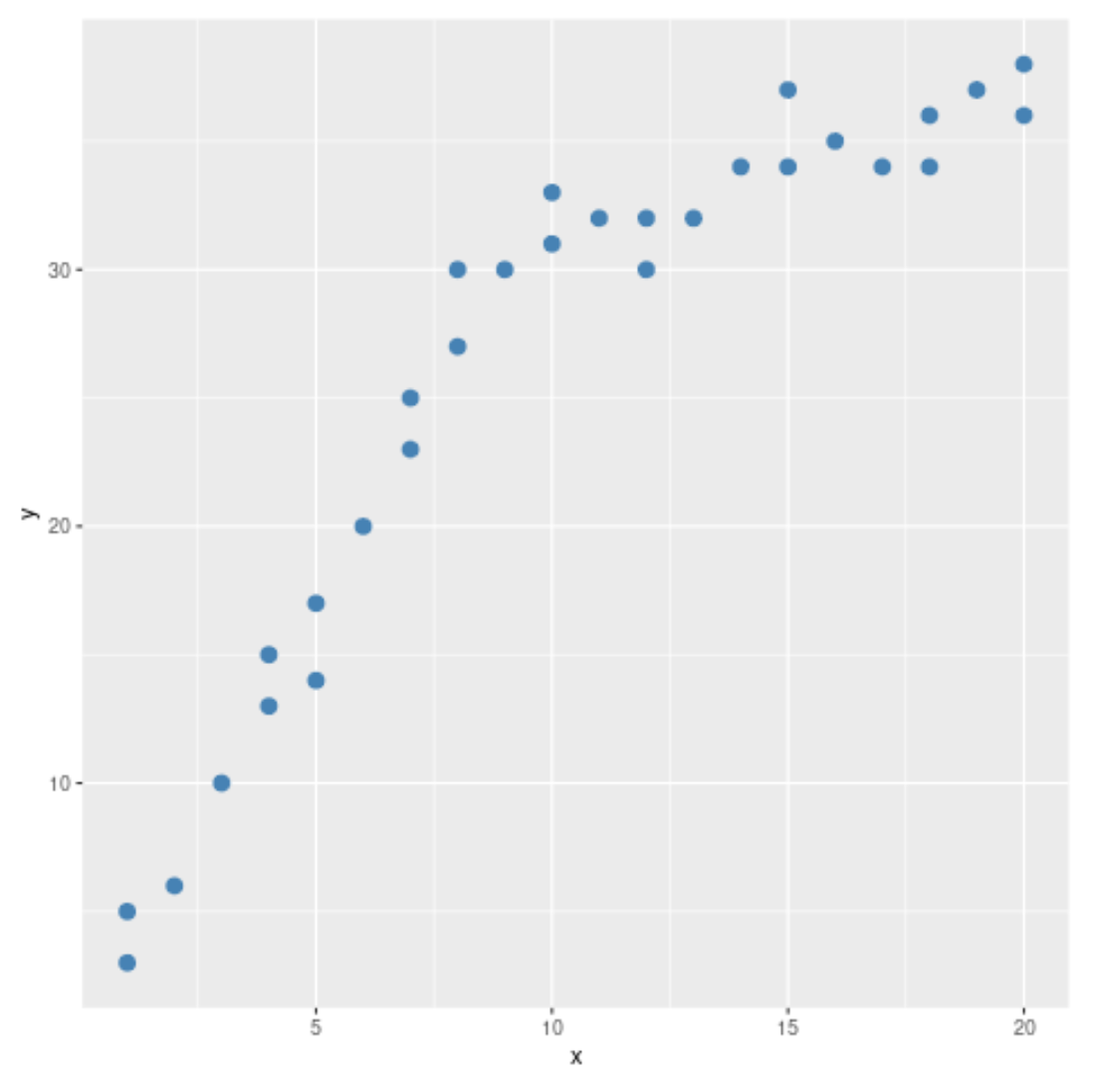
散布図から、データのパターンが x = 10 で変化しているように見えることがわかります。したがって、Chow 検定を実行して、x = 10 でデータに構造的ブレークポイントがあるかどうかを判断できます。
ステップ 3: 食事テストを実行する
strucchangeパッケージのsctest関数を使用して、Chow テストを実行できます。
#load strucchange package library (strucchange) #perform Chow test sctest(data$y ~ data$x, type = " Chow ", point = 10 ) Chow test data: data$y ~ data$x F = 110.14, p-value = 2.023e-13
テスト結果から次のことがわかります。
- F 検定統計量: 110.14
- p値: <.0000
p 値は 0.05 未満であるため、検定の帰無仮説を棄却できます。これは、データ内に構造的ブレークポイントが存在すると言える十分な証拠があることを意味します。
言い換えれば、2 つの回帰直線は 1 つの回帰直線よりも効果的にデータにモデルを当てはめることができます。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る