Sas: 正規性テストに proc univariate を使用する方法
SAS のproc univariate をNormalステートメントとともに使用して、データセット内の変数に対して複数の正規性テストを実行できます。
この手順では、次の基本構文を使用します。
proc univariate data =my_data normal ;
var my_variable;
run ;
次の例は、この手順を実際に使用する方法を示しています。
例: SAS での正規性テストのための Proc Univariate
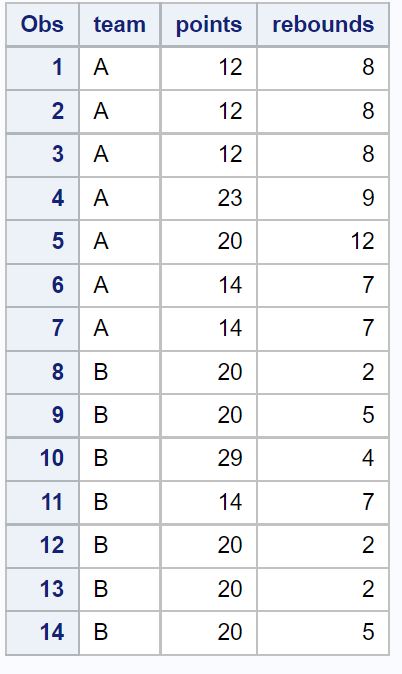
SAS に、さまざまなバスケットボール選手に関する情報を含む次のデータセットがあるとします。
/*create dataset*/
data my_data;
input team $pointsrebounds;
datalines ;
At 12 8
At 12 8
At 12 8
At 23 9
At 20 12
At 14 7
At 14 7
B 20 2
B 20 5
B 29 4
B 14 7
B 20 2
B 20 2
B 20 5
;
run ;
/*view dataset*/
proc print data =my_data;
Normalステートメントでproc univariateを使用すると、 points変数に対してさまざまな正規性テストを実行できます。
proc univariate data =my_data normal ;
var points;
run ;
結果にはいくつかのテーブルが表示されますが、 「正規性テスト」というタイトルのテーブルには正規性テストの結果が含まれています。
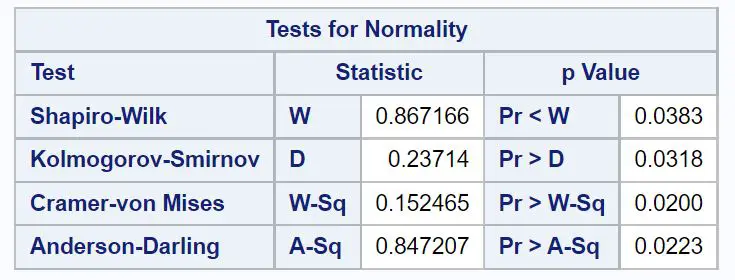
デフォルトでは、SAS は 4 つの正規性検定を実行し、それぞれの検定統計量と対応する p 値を表示します。
- シャピロ・ウィルク検定: W = 0.867、p = 0.0383
- コルモゴロフ・スミルノフ検定: D = .237、p = .0318
- クラマー・フォン・ミーゼス検定: W-Sq = 0.152、p = 0.0200
- アンダーソン・ダーリング検定: A-Sq = 0.847、p = 0.0223
各正規性検定では、次の帰無仮説と対立仮説を使用します。
- H 0 : データは正規分布します。
- H A : データは正規分布していません。
各正規性検定のp 値は0.05 未満であるため、各正規性検定の帰無仮説は棄却されます。
これは、ポイント変数が正規分布していないと結論付けるのに十分な証拠があることを意味します。
正規曲線を重ね合わせたヒストグラムを作成して、ポイント変数の値の分布を視覚化することもできることに注意してください。
proc univariate data =my_data;
histogram points / normal ;
run ;
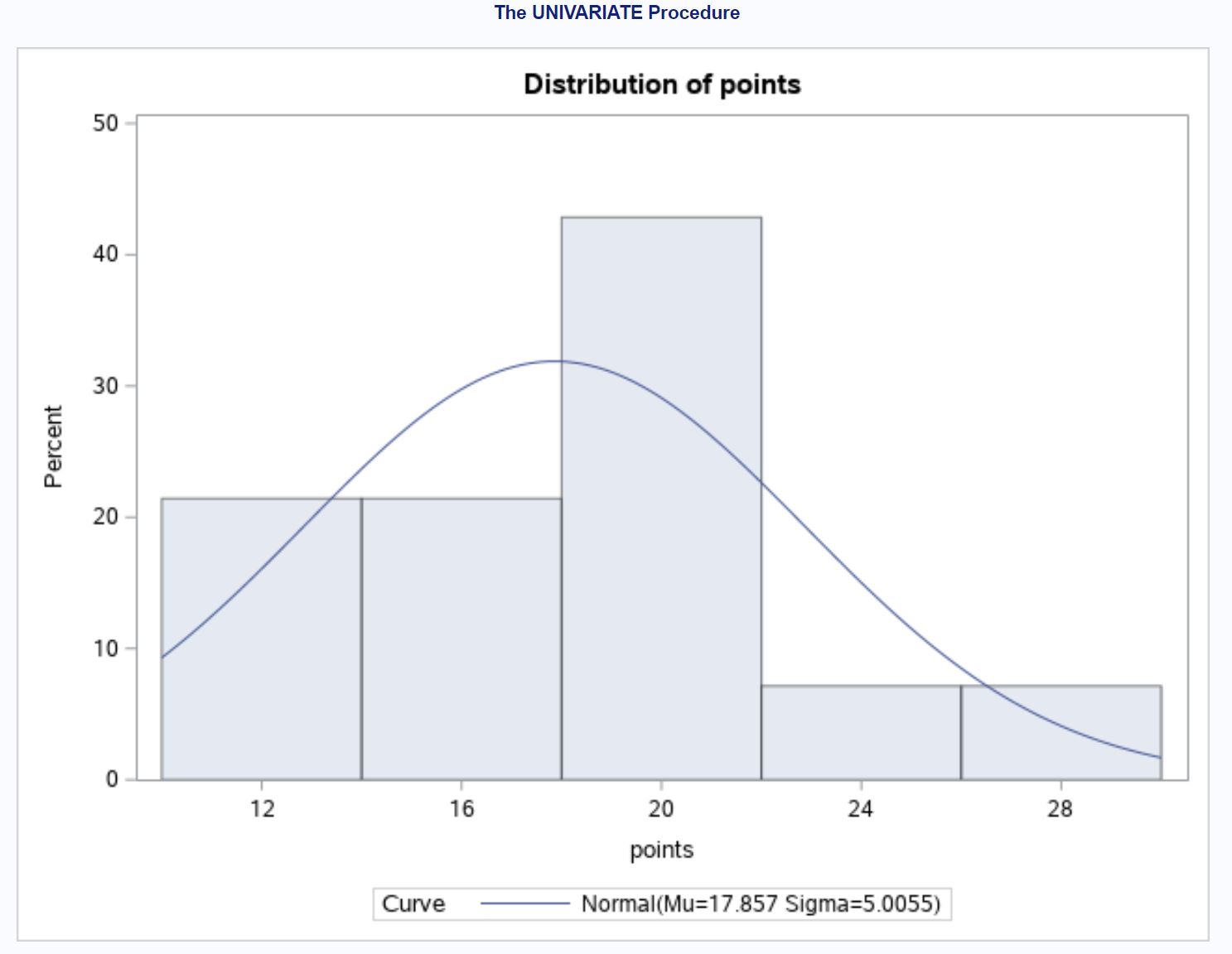
ヒストグラムは、値の分布が正規曲線にあまり従っていないことを示しており、これは実行した正規性テストの結果と一致しています。
追加リソース
次のチュートリアルでは、SAS で他の一般的なタスクを実行する方法について説明します。
SAS での手順の概要の使用方法
SAS で Proc Tabulate を使用する方法
SAS で Proc 照合を使用する方法
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る