Sas で proc cluster を使用する方法 (例あり)
クラスタリングは、データセット内の観測値のグループを見つけようとする機械学習手法です。
目標は、各クラスター内の観測値が互いに非常に類似している一方で、異なるクラスター内の観測値が互いに大きく異なるようなクラスターを見つけることです。
SAS でクラスタリングを行う最も簡単な方法は、 PROC CLUSTERを使用することです。
次の例は、 PROC CLUSTER を実際に使用する方法を示しています。
例: SAS で PROC CLUSTER を使用する方法
20 人の異なるバスケットボール選手のポイント、アシスト、リバウンドに関する情報を含む次のデータセットがあるとします。
/*create dataset*/
data my_data;
input points assists rebounds;
datalines ;
18 3 15
20 3 14
19 4 14
14 5 10
14 4 8
15 7 14
20 8 13
28 7 9
30 6 5
31 9 4
35 12 11
33 14 6
29 9 5
25 9 5
25 4 3
27 3 8
29 4 12
30 12 7
19 5 6
23 11 5
;
run ;
/*view dataset*/
proc print data =my_data;
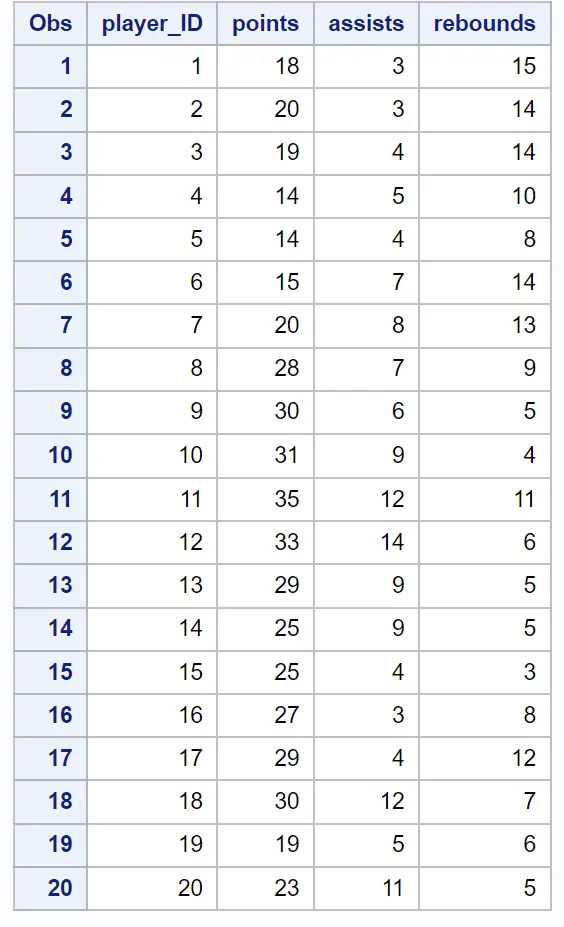
互いに同様の統計情報を持つプレイヤーの「クラスター」を識別するために、いくつかのグループ化を行いたいとします。
次のコードは、SAS でPROC CLUSTER を使用してクラスタリングを実行する方法を示しています。
/*perform clustering using points, assists and rebounds variables*/
proc cluster data =my_data method =average;
var points assists rebounds;
run ;
結果の最初の表には、クラスタリングがどのように実行されたかに関する情報が示されています。
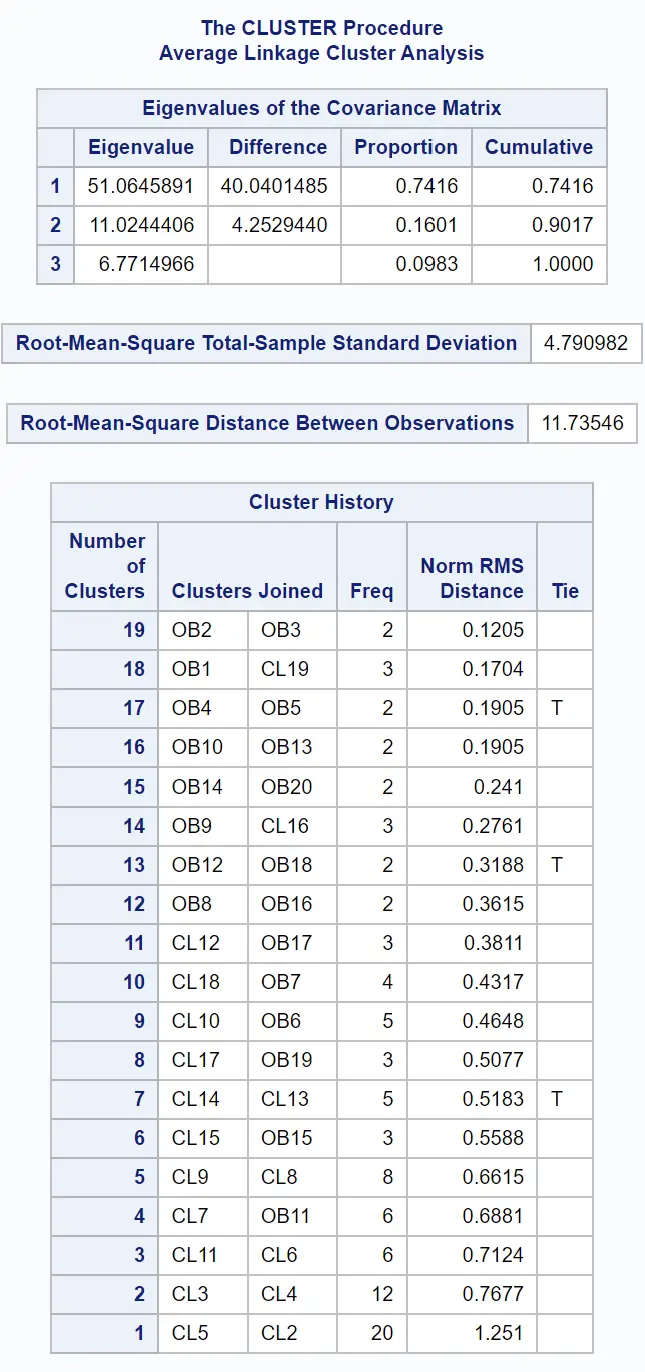
データセット内の観察間の類似性を視覚的に検査できるように、樹形図も生成されます。
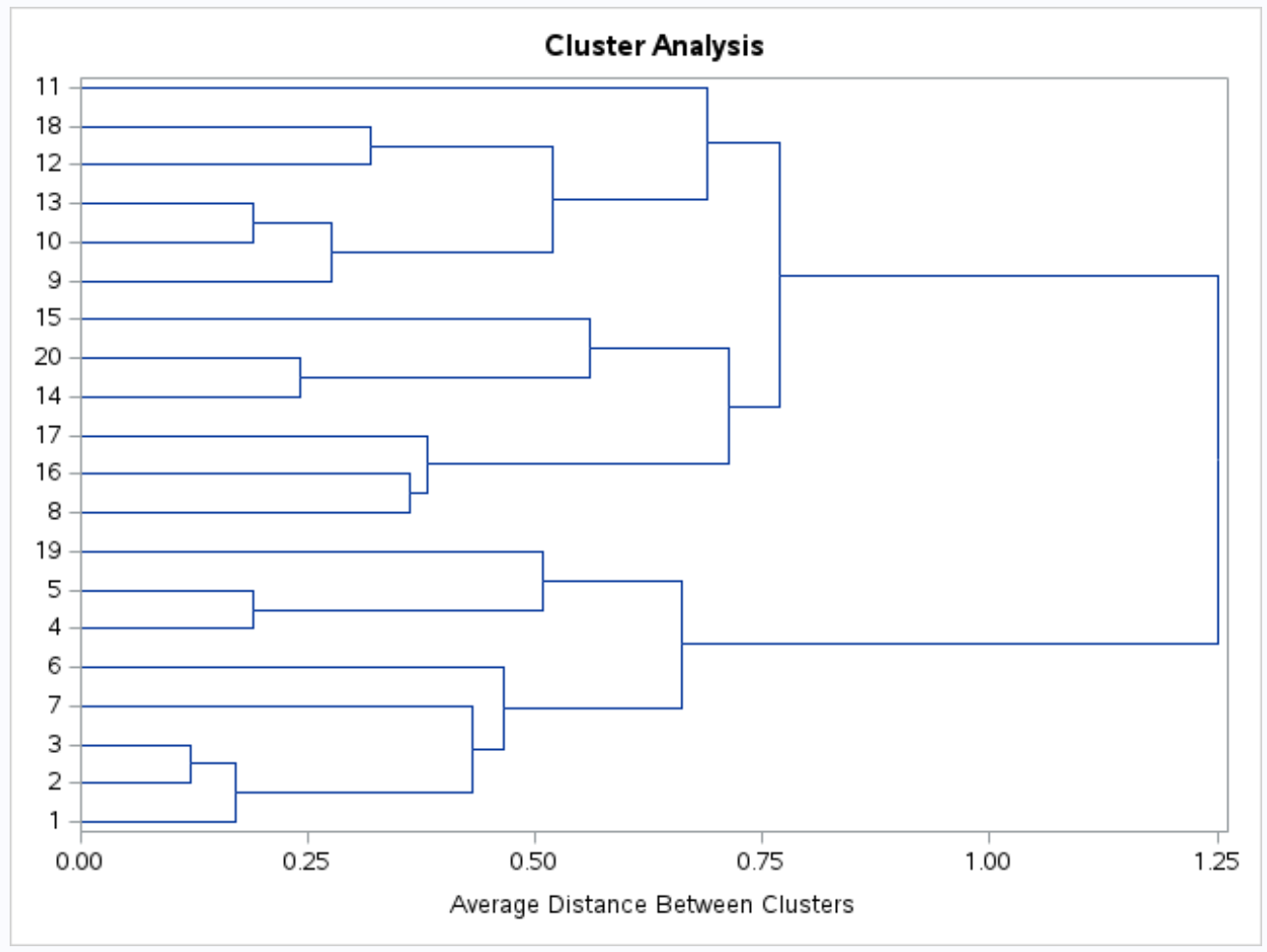
Y 軸は個々の観測値を示し、X 軸はクラスター間の平均距離を示します。
この樹状図を見ると、観察結果は自然に 3 つのグループに分類されるようです。
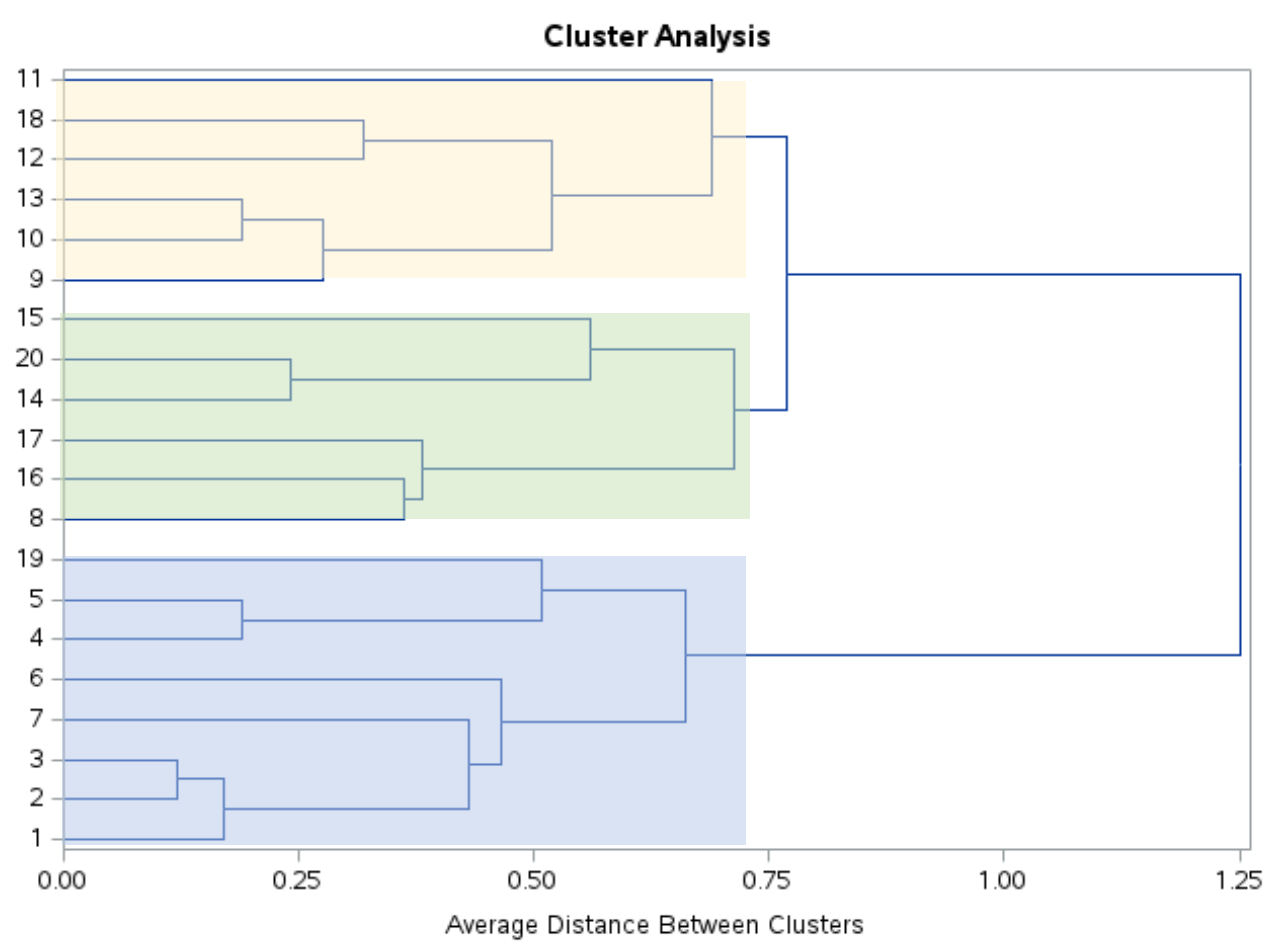
次に、 ncl=3 を指定したPROC TREEステートメントを使用して、元のデータセット内の各観測値を 3 つのクラスターのいずれかに割り当てるように SAS に指示できます。
/*assign each observation to one of three clusters*/
proc tree data =clustd noprint ncl =3 out =clusts;
copy points assists rebounds;
id player_ID;
run ;
proc sort ;
by cluster;
run ;
/*view cluster assignments*/
proc print data = clusters;
id player_ID;
run ;
結果として得られるデータセットには、元の観測値のそれぞれと、それらが属するクラスターが表示されます。
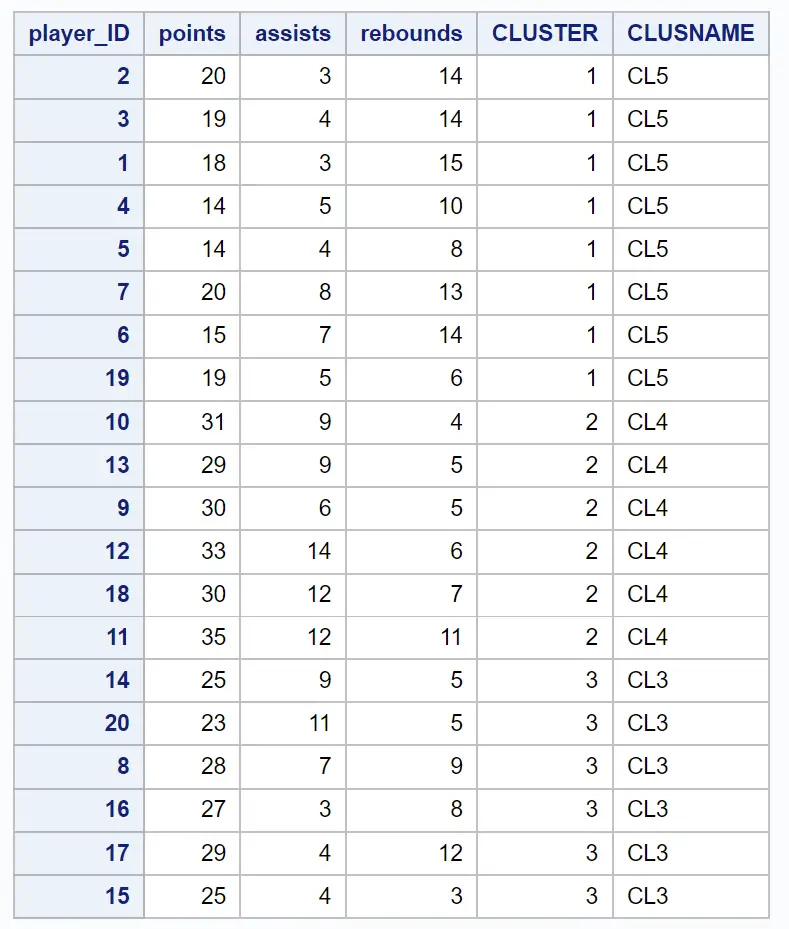
たとえば、 ID 2、3、1、4、5、7、6、および 19 を持つプレーヤーはすべてクラスター1に属していることがわかります。
これは、これら 8 人の選手が得点、アシスト、リバウンドの変数の点で「似ている」ことを示しています。
注: この例では、クラスタリングのリンク方法として平均化を使用することを選択しました。使用できる他のバインド方法の完全なリストについては、 SAS のドキュメントを参照してください。
追加リソース
次のチュートリアルでは、SAS で他の一般的なタスクを実行する方法について説明します。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る