Sas で proc glmselect ステートメントを使用する方法
SAS でPROC GLMSELECTステートメントを使用すると、潜在的な予測変数のリストに基づいて最適な回帰モデルを選択できます。
次の例は、このステートメントを実際に使用する方法を示しています。
例: SAS でモデル選択に PROC GLMSELECT を使用する方法
(1)学習に費やした時間数、 (2)受験した予備試験の数、および(3)性別を使用して、生徒の最終成績試験を予測する重回帰モデルを当てはめたいとします。
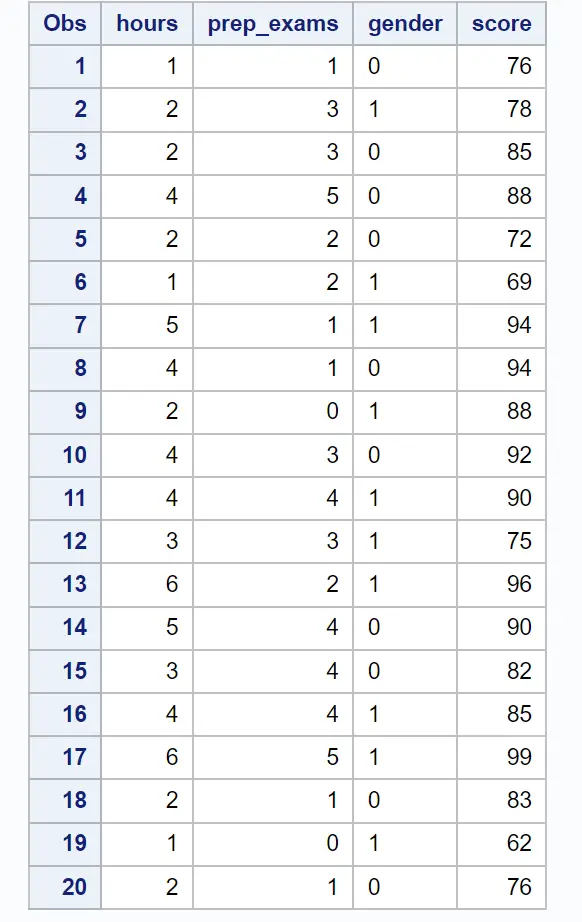
まず、次のコードを使用して、20 人の生徒の情報を含むデータセットを作成します。
/*create dataset*/ data exam_data; input hours prep_exams gender $score; datalines ; 1 1 0 76 2 3 1 78 2 3 0 85 4 5 0 88 2 2 0 72 1 2 1 69 5 1 1 94 4 1 0 94 2 0 1 88 4 3 0 92 4 4 1 90 3 3 1 75 6 2 1 96 5 4 0 90 3 4 0 82 4 4 1 85 6 5 1 99 2 1 0 83 1 0 1 62 2 1 0 76 ; run ; /*view dataset*/ proc print data =exam_data;
次に、 PROC GLMSELECTステートメントを使用して、最良の回帰モデルを生成する予測子変数のサブセットを特定します。
/*perform model selection*/
proc glmselect data =exam_data;
classgender ;
model score = hours prep_exams gender;
run ;
注: 性別はカテゴリ変数であるため、クラスステートメントに性別を含めました。
出力の最初のグループの表には、GLMSELECT プロシージャの概要が示されています。
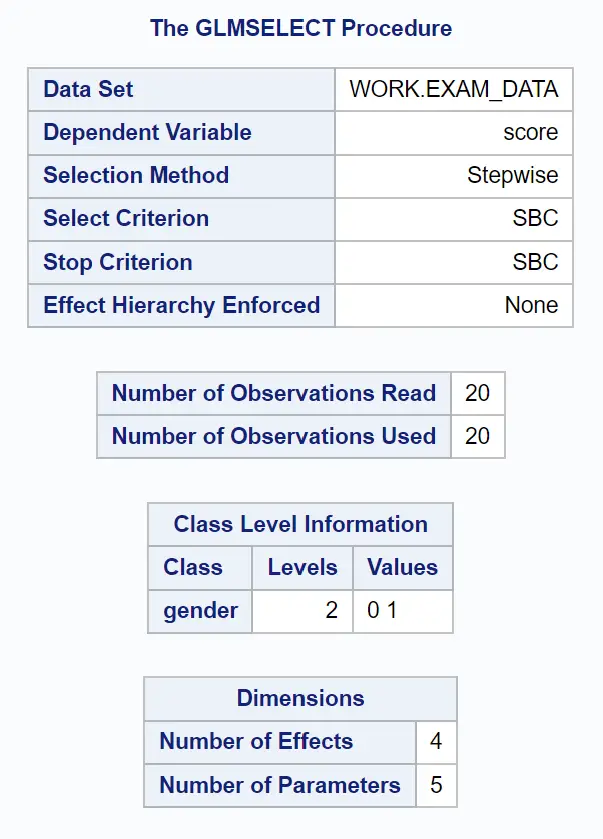
モデルへの変数の追加または削除を停止するために使用された基準はSBCであったことがわかります。これはシュワルツ情報量基準であり、ベイジアン情報量基準とも呼ばれます。
基本的に、 PROC GLMSELECTステートメントは、SBC 値が最も低いモデル (「最良の」モデルとみなされる) が見つかるまで、モデルへの変数の追加または削除を続けます。
次の表のグループは、段階的な選択がどのように終了したかを示しています。
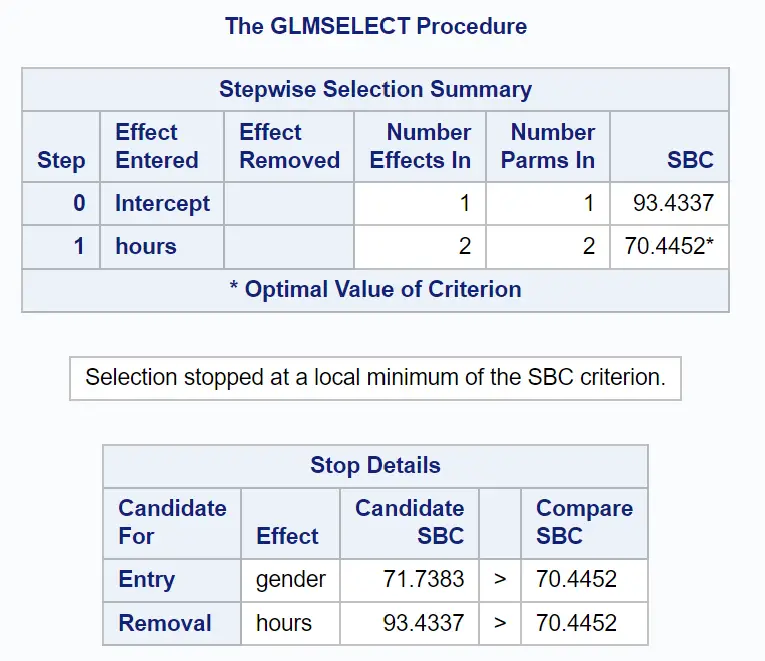
元の項のみを含むモデルの SBC 値は93.4337であることがわかります。
モデルに予測変数として時間を追加すると、SBC 値は70.4452に低下しました。
モデルを改善する最善の方法は、予測変数として性別を追加することでしたが、これにより実際には SBC 値が71.7383 に増加しました。
したがって、最終的なモデルには、切片項と調査された時間のみが含まれます。
結果の最後の部分には、この適合回帰モデルの概要が表示されます。
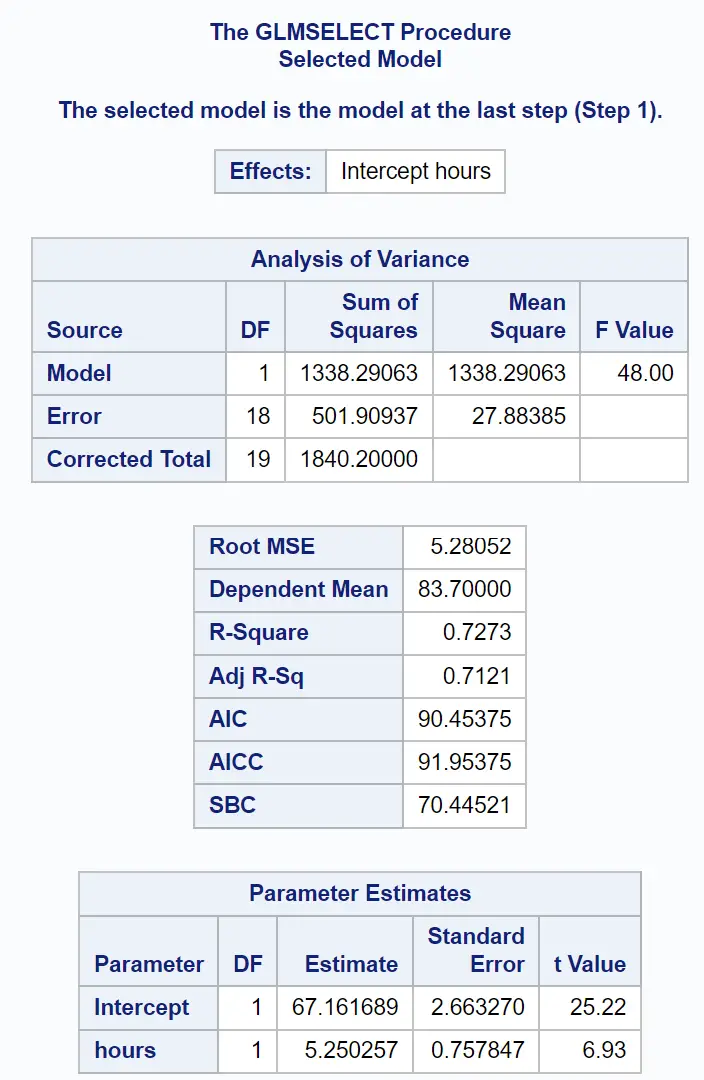
パラメーター推定テーブルの値を使用して、近似回帰モデルを作成できます。
試験スコア = 67.161689 + 5.250257 (勉強時間)
このモデルがデータにどの程度適合しているかを示すさまざまな指標も確認できます。
R 二乗値は、勉強時間数と受けた予備試験の数によって説明できる試験得点の変動のパーセンテージを示します。
この場合、試験得点の変動の72.73%は、勉強時間数と受験した予備試験の数によって説明できます。
ルート MSE値も知っておくと役に立ちます。これは、観測値と回帰直線の間の平均距離を表します。
この回帰モデルでは、観測値は回帰直線から平均して5.28052単位逸脱します。
注: PROC GLMSELECTで使用できる潜在的な引数の完全なリストについては、 SAS ドキュメントを参照してください。
追加リソース
次のチュートリアルでは、SAS で他の一般的なタスクを実行する方法について説明します。
SAS で単純な線形回帰を実行する方法
SAS で重回帰を実行する方法
SAS で多項式回帰を実行する方法
SAS でロジスティック回帰を実行する方法
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る