完全ガイド: sas で anova 結果を解釈する方法
一元配置分散分析は、 3 つ以上の独立したグループの平均間に統計的に有意な差があるかどうかを判断するために使用されます。
次の例は、SAS で一元配置 ANOVA の結果を解釈する方法を示しています。
例: SAS での ANOVA 結果の解釈
研究者が研究に参加する 30 人の学生を募集するとします。学生は、試験の準備のために 3 つの学習方法のいずれかを使用するようにランダムに割り当てられます。
各生徒の試験結果は以下のとおりです。
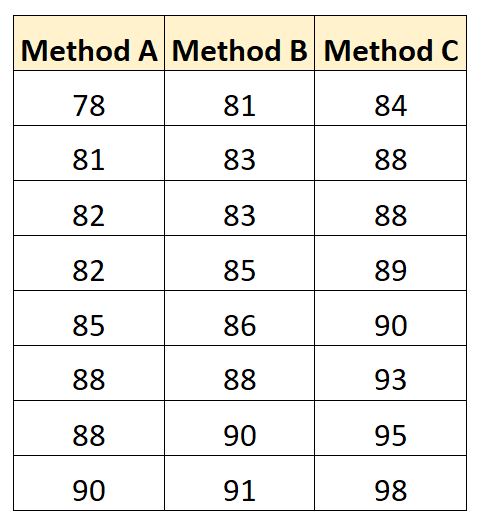
次のコードを使用して、SAS でこのデータセットを作成できます。
/*create dataset*/
data my_data;
input Method $Score;
datalines ;
At 78
At 81
At 82
At 82
At 85
At 88
At 88
At 90
B 81
B 83
B 83
B85
B 86
B 88
B90
B91
C 84
C 88
C 88
C 89
C 90
C 93
C 95
C 98
;
run ;
次に、 proc ANOVA を使用して一元配置分散分析を実行します。
/*perform one-way ANOVA*/
proc ANOVA data =my_data;
classMethod ;
modelScore = Method;
means Method / tukey cldiff ;
run ;
注: 一元配置分散分析からの全体的な p 値が統計的に有意である場合に Tukey 事後検定を (信頼区間を使用して) 実行する必要があることを指定するために、means ステートメントを tukeyおよびcldiffオプションとともに使用しました。
まず、結果の ANOVA テーブルを確認します。
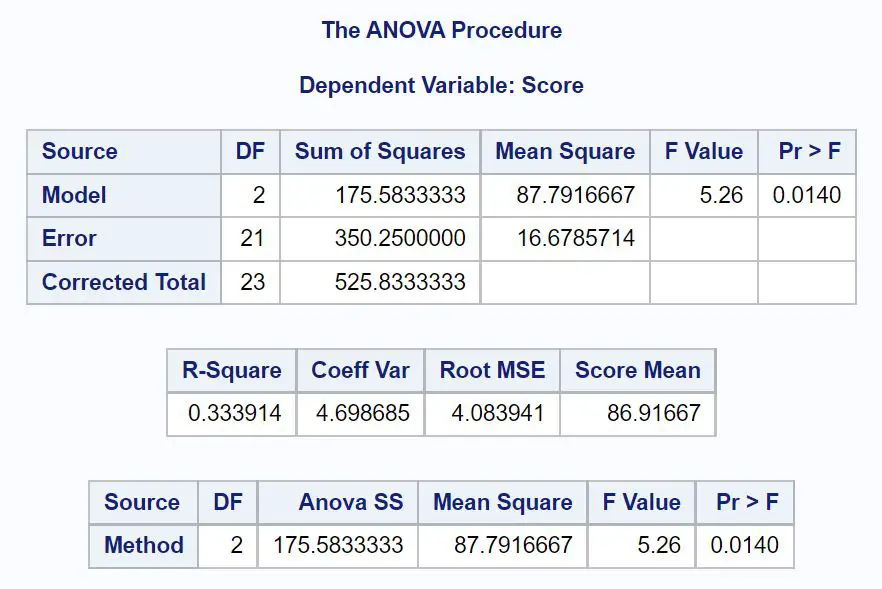
出力内の各値を解釈する方法は次のとおりです。
DF モデル:変数メソッドの自由度。これは #groups -1 として計算されます。この場合、3 つの異なる学習方法があったため、この値は 3-1 = 2となります。
DF 誤差:残差の自由度。これは、観測総数 – グループ数として計算されます。この場合、24 個の観測値と 3 つのグループがあるため、この値は 24-3 = 21となります。
修正された合計: DF モデルと DF 誤差の合計。この値は 2 + 21 = 23です。
二乗和モデル:変数メソッドに関連付けられた二乗和。この値は175.583です。
二乗和誤差:残差または「誤差」に関連付けられた二乗和。この値は350.25です。
修正平方和合計: SS モデルと SS 誤差の合計。この値は525.833です。
平均二乗モデル:メソッドに関連付けられた平均二乗和。これは、SS モデル / DF モデル、つまり 175.583 / 2 = 87.79として計算されます。
平均二乗誤差:残差に関連付けられた平均二乗和。これは SS 誤差 / DF 誤差として計算され、350.25 / 21 = 16.68となります。
F 値: ANOVA モデルの全体的な F 統計量。これは、モデルの平均二乗/平均二乗誤差、つまり 87.79/16.68 = 5.26として計算されます。
Pr >F:分子 df = 2、分母 df = 21 の F 統計量に関連付けられた p 値。この場合、p 値は0.0140です。
一連の結果の中で最も重要な値は p 値です。これにより、3 つのグループ間の平均値に有意な差があるかどうかがわかります。
一元配置分散分析では次の帰無仮説と対立仮説が使用されることを思い出してください。
- H 0 (帰無仮説):すべてのグループ平均は等しい。
- H A (対立仮説):少なくとも 1 つのグループ平均が他のグループ平均とは異なります。
ANOVA 表の p 値 (0.0140) は 0.05 未満であるため、帰無仮説を棄却します。
これは、試験の平均点が 3 つの勉強方法で等しくないと言える十分な証拠があることを意味します。
どのグループ平均が異なるかを正確に判断するには、Tukey の事後検定の結果を示す最終結果テーブルを参照する必要があります。
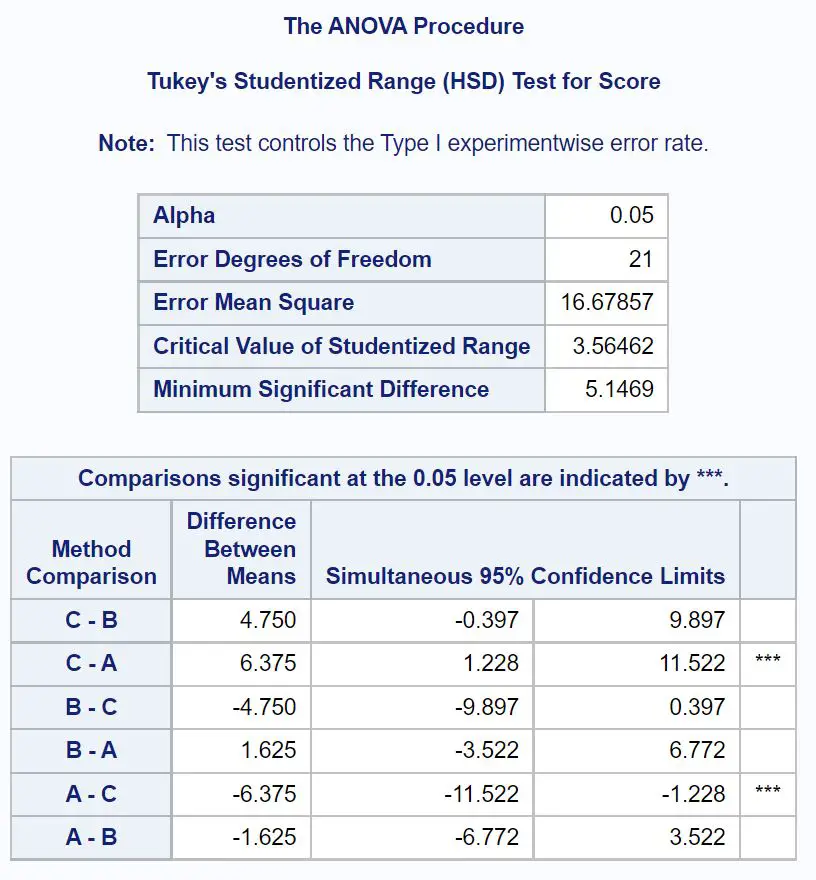
どのグループ平均が異なるかを調べるには、どのペアごとの比較の横に星 ( *** ) が付いているかを確認する必要があります。
この表は、グループ A とグループ C の間で試験の平均点に統計的に有意な差があることを示しています。
具体的には、グループ C とグループ A の試験得点の平均差は6.375です。
平均差の 95% 信頼区間は[1.228, 11.522]です。
他のグループの平均値の間に統計的に有意な差はありません。
追加リソース
次のチュートリアルでは、ANOVA モデルに関する追加情報を提供します。
ANOVA で事後テストを使用するためのガイド
SAS で一元配置分散分析を実行する方法
SAS で二元配置分散分析を実行する方法
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る