Sas での indexc 関数の使用方法
SAS でINDEXC関数を使用すると、文字列内の個々の文字が最初に出現する位置を返すことができます。
この関数は次の基本構文を使用します。
INDEXC(ソース、抜粋)
金:
- ソース: 分析するチャネル
- extract :ソース内で検索する文字列
次の例は、この関数を実際に使用する方法を示しています。
例: SAS での INDEXC 関数の使用
SAS に名前の列を含む次のデータセットがあるとします。
/*create dataset*/
data original_data;
input name $25.;
datalines ;
Andy Lincoln Bernard
Michael Smith
Chad Simpson Arnolds
Derrick Smith Henrys
Eric Millerton Smith
Frank Giovanni Goode
;
run ;
/*view dataset*/
proc print data = original_data;
INDEXC関数を使用すると、文字x 、 y 、またはzが最初に出現する位置を見つけることができます。
/*find position of first occurrence of either x, y or z in name*/
data new_data;
set original_data;
first_xyz = indexc (name, 'xyz');
run ;
/*view results*/
proc print data = new_data;
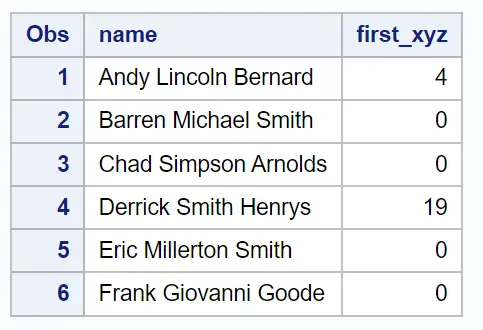
first_xyzという新しい列には、 name列内で文字x 、 y 、またはzが最初に出現する位置が表示されます。
これら 3 つの文字がname列に存在しない場合、 INDEXC関数は単に値0を返します。
たとえば、結果から次のことがわかります。
最初の行で最初に出現する x、y、または z の位置は、位置4です。最初の行の 4 番目の文字がyであることがわかります。
これら 3 つの文字が 2 行目の名前に存在しないため、2 行目で最初に出現する x、y、または z の位置は0になります。
等々。
INDEX 関数と INDEXC 関数の違い
SAS のINDEX関数は、別の文字列内で特定の部分文字列が最初に出現する位置を返します。
次の例は、 INDEX関数とINDEXC関数の違いを示しています。
/*create new dataset*/
data new_data;
set original_data;
index_smith = index (name, 'Smith');
indexc_smith = indexc (name, 'Smith');
run ;
/*view new dataset*/
proc print data =new_data;
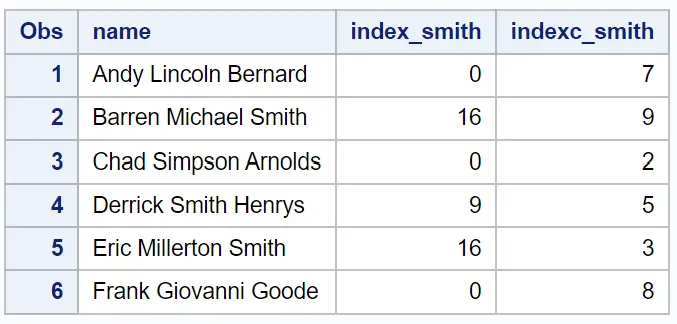
Index_smith列には、 name列内で部分文字列「Smith」が最初に出現する位置が表示されます。
Indexc_smith列には、 name列内で文字s 、 m 、 i 、 t 、またはhが最初に出現する位置が表示されます。
たとえば、結果から次のことがわかります。
部分文字列 ‘Smith’ が名に現れることはないため、 index_smith は値0を返します。
文字i は名の 7 番目の位置にあるため、 indexc_smith は値7を返します。
等々。
追加リソース
次のチュートリアルでは、SAS の他の一般的な関数の使用方法について説明します。
SAS で SUBSTR 関数を使用する方法
SAS で COMPRESS 機能を使用する方法
SAS で FIND 関数を使用する方法
SAS での COALESCE 機能の使用方法
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る