ラッソ回帰の概要
通常の重線形回帰では、 p 個の予測子変数のセットと応答変数を使用して、次の形式のモデルを近似します。
Y = β 0 + β 1 X 1 + β 2 X 2 + … + β p
金:
- Y : 応答変数
- X j : j番目の予測変数
- β j : 他のすべての予測子を固定したまま、X jの 1 単位増加が Y に与える平均効果
- ε : 誤差項
β 0 、β 1 、B 2 、…、β pの値は、残差の二乗和 (RSS) を最小化する最小二乗法を使用して選択されます。
RSS = Σ(y i – ŷ i ) 2
金:
- Σ : 和を意味するギリシャ語の記号
- y i : i 番目の観測値の実際の応答値
- ŷ i : 重回帰モデルに基づく予測応答値
ただし、予測変数の相関性が高い場合、 多重共線性が問題になる可能性があります。これにより、モデルの係数推定の信頼性が低くなり、大きな分散が示される可能性があります。つまり、モデルがこれまでに見たことのない新しいデータセットに適用されると、パフォーマンスが低下する可能性があります。
この問題を回避する 1 つの方法は、なげなわ回帰として知られる方法を使用することです。この方法では、代わりに以下を最小限に抑えようとします。
RSS + λΣ|β j |
ここで、j は1 からpまで変化し、λ ≥ 0 となります。
方程式のこの 2 番目の項は、撤退ペナルティとして知られています。
λ = 0 の場合、このペナルティ項は効果がなく、ラッソ回帰では最小二乗法と同じ係数推定値が生成されます。
ただし、λ が無限大に近づくにつれて、削除ペナルティの影響が大きくなり、モデルにインポートできない予測変数はゼロに削減され、一部はモデルから削除されることもあります。
なぜなげなわ回帰を使用するのでしょうか?
最小二乗回帰に対するラッソ回帰の利点は、 バイアスと分散のトレードオフです。
平均二乗誤差 (MSE) は特定のモデルの精度を測定するために使用できるメトリクスであり、次のように計算されることを思い出してください。
MSE = Var( f̂( x 0 )) + [バイアス( f̂( x 0 ))] 2 + Var(ε)
MSE = 分散 + バイアス2 + 既約誤差
ラッソ回帰の基本的な考え方は、分散を大幅に低減できるように小さなバイアスを導入し、全体的な MSE を下げることです。
これを説明するために、次のグラフを考えてみましょう。

λ が増加すると、バイアスがわずかに増加するだけで分散が大幅に減少することに注意してください。ただし、ある点を超えると、分散の減少速度が鈍くなり、係数の減少により係数が大幅に過小評価され、バイアスが急激に増加します。
グラフから、バイアスと分散の間の最適なトレードオフを生み出す λ の値を選択すると、テストの MSE が最も低くなることがわかります。
λ = 0 の場合、ラッソ回帰のペナルティ項は効果がないため、最小二乗法と同じ係数推定値が生成されます。ただし、λ を特定の点まで増やすことによって、テスト全体の MSE を減らすことができます。
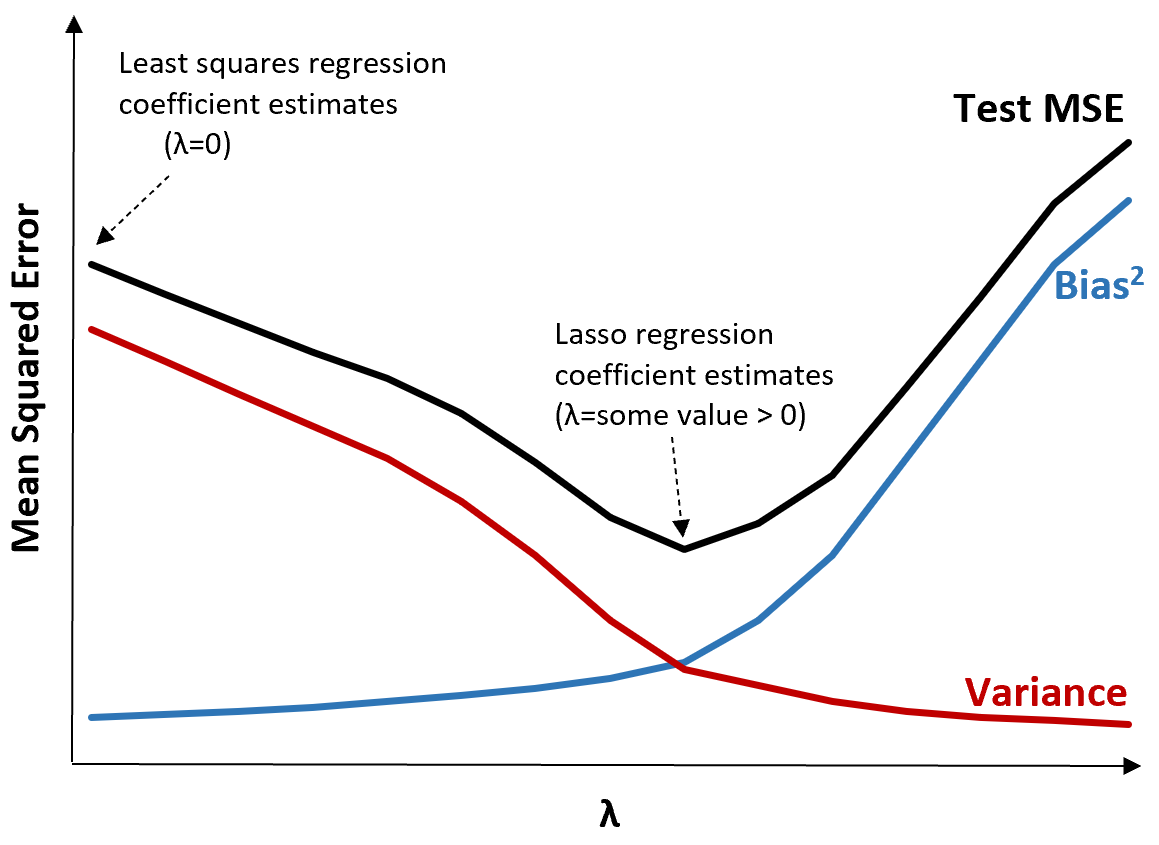
これは、ラッソ回帰によるモデル フィッティングの方が、最小二乗回帰によるモデル フィッティングよりも小さなテスト誤差が生じることを意味します。
ラッソ回帰とリッジ回帰
ラッソ回帰とリッジ回帰は両方とも、残差二乗和 (RSS) と特定のペナルティ項を最小化しようとするため、正則化手法として知られています。
言い換えれば、モデル係数の推定値を制約または正規化します。
ただし、彼らが使用するペナルティ条件は少し異なります。
- ラッソ回帰では、RSS + λΣ|β j |を最小化しようとします。
- リッジ回帰はRSS + λΣβ j 2を最小化することを試みます
リッジ回帰を使用すると、各予測子の係数はゼロに減らされますが、どれも完全にゼロになることはできません。
逆に、なげなわ回帰を使用すると、λ が十分に大きくなると一部の係数が完全にゼロになる可能性があります。
技術的に言えば、ラッソ回帰は「疎」モデル、つまり予測変数のサブセットのみを含むモデルを生成できます。
ここで疑問が生じます:リッジ回帰となげなわ回帰のどちらが優れているのでしょうか?
答え: それは状況次第です!
少数の予測子変数のみが重要である場合、ラッソ回帰は重要でない変数を完全にゼロにしてモデルから削除できるため、より適切に機能する傾向があります。
ただし、多くの予測子変数がモデル内で重要であり、それらの係数がほぼ等しい場合は、すべての予測子をモデル内に保持するため、リッジ回帰がより適切に機能する傾向があります。
どのモデルが予測を行うのに最も効果的であるかを判断するために、k 分割相互検証を実行します。最小の平均二乗誤差 (MSE) を生成するモデルが、使用するのに最適なモデルです。
実際になげなわ回帰を実行する手順
次の手順を使用して、なげなわ回帰を実行できます。
ステップ 1: 予測子変数の相関行列と VIF 値を計算します。
まず、 相関行列を作成し、各予測変数のVIF (分散膨張係数) 値を計算する必要があります。
予測変数と高い VIF 値との間に強い相関関係が検出された場合 (一部のテキストでは「高い」VIF 値を 5 と定義していますが、他のテキストでは 10 を使用しています)、おそらくラッソ回帰が適切です。
ただし、データに多重共線性がない場合は、そもそもラッソ回帰を実行する必要がない可能性があります。代わりに、通常の最小二乗回帰を実行できます。
ステップ 2: ラッソ回帰モデルを適合させ、λ の値を選択します。
ラッソ回帰が適切であると判断したら、(R や Python などの一般的なプログラミング言語を使用して) λ の最適値を使用してモデルを当てはめることができます。
λ の最適な値を決定するには、異なる λ 値を使用して複数のモデルを適合させ、最低の MSE テストを生成する値として λ を選択します。
ステップ 3: なげなわ回帰をリッジ回帰および通常の最小二乗回帰と比較します。
最後に、ラッソ回帰モデルをリッジ回帰モデルおよび最小二乗回帰モデルと比較して、k 分割相互検証を使用してどのモデルが最も低い MSE 検定を生成するかを判断できます。
予測変数と応答変数の間の関係に応じて、これら 3 つのモデルのいずれかがさまざまなシナリオで他のモデルよりも優れたパフォーマンスを発揮する可能性は十分にあります。
R と Python でのなげなわ回帰
次のチュートリアルでは、R と Python でなげなわ回帰を実行する方法について説明します。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る