R の iris データセットの完全ガイド
アヤメのデータセットは、R の統合データセットで、3 つの異なる種の 50 個の花の 4 つの異なる属性 (センチメートル単位) の測定値が含まれています。
このチュートリアルでは、例として iris データセットを使用して、R でデータセットを探索して要約する方法を説明します。
アイリスデータセットをロードする
iris データセットは R の組み込みデータセットであるため、次のコマンドを使用してロードできます。
data(iris)
head()関数を使用して、データセットの最初の 6 行を確認できます。
#view first six rows of iris dataset
head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
Iris データセットを要約する
summary()関数を使用すると、データセット内の各変数をすばやく要約できます。
#summarize iris dataset
summary(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4,300 Min. :2,000 Min. :1,000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median: 5,800 Median: 3,000 Median: 4,350 Median: 1,300
Mean:5.843 Mean:3.057 Mean:3.758 Mean:1.199
3rd Qu.:6,400 3rd Qu.:3,300 3rd Qu.:5,100 3rd Qu.:1,800
Max. :7,900 Max. :4,400 Max. :6,900 Max. :2,500
Species
setosa:50
versicolor:50
virginica :50
各数値変数について、次の情報を確認できます。
- Min : 最小値。
- 1st Qu : 最初の四分位数 (25 パーセンタイル) の値。
- 中央値: 中央値。
- 平均: 平均値。
- 3rd Qu : 第 3 四分位数 (75 パーセンタイル) の値。
- Max : 最大値。
データセット内の唯一のカテゴリ変数 (種) について、各値の頻度数が表示されます。
- setosa : この種は 50 回存在します。
- versicolor : この種は 50 回発生します。
- virginica : この種は 50 回存在します。
dim()関数を使用して、行数と列数に関してデータセットの次元を取得できます。
#display rows and columns
dim(iris)
[1] 150 5
データセットには150行と5列があることがわかります。
names()関数を使用して、データ フレームの列名を表示することもできます。
#display column names
names(iris)
[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"
Iris データセットを視覚化する
プロットを作成してデータセットの値を視覚化することもできます。
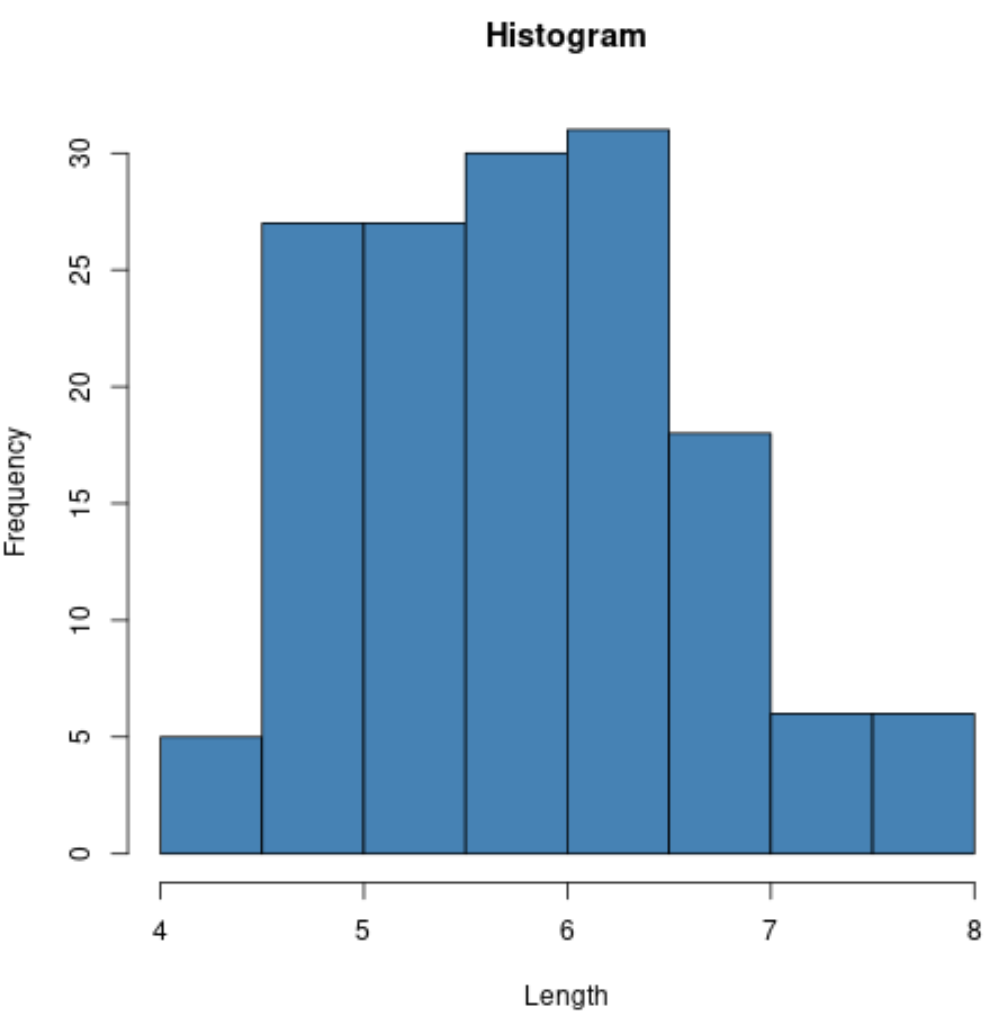
たとえば、 hist()関数を使用して、特定の変数の値のヒストグラムを作成できます。
#create histogram of values for sepal length
hist(iris$Sepal.Length,
col=' steelblue ',
main=' Histogram ',
xlab=' Length ',
ylab=' Frequency ')
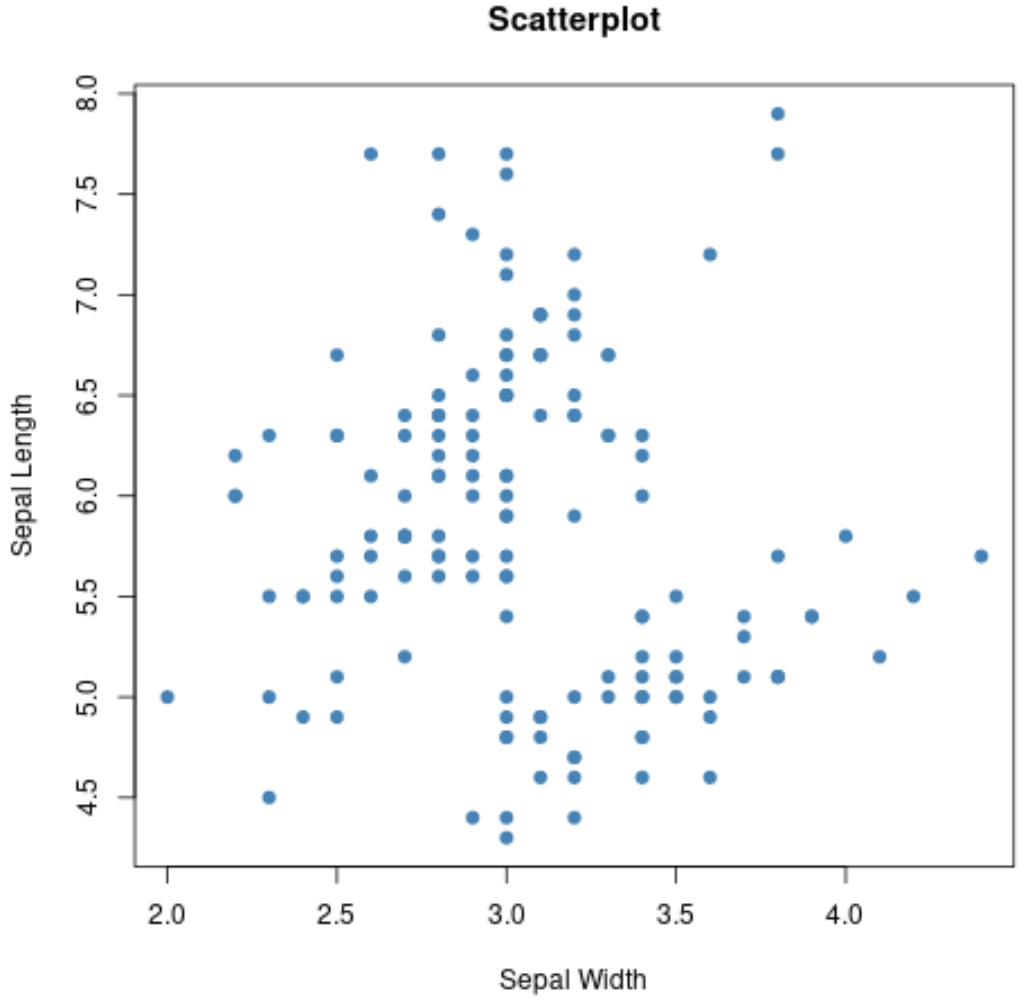
また、 plot()関数を使用して、変数のペアごとの組み合わせの散布図を作成することもできます。
#create scatterplot of sepal width vs. sepal length
plot(iris$Sepal.Width, iris$Sepal.Length,
col=' steelblue ',
main=' Scatterplot ',
xlab=' Sepal Width ',
ylab=' Sepal Length ',
pch= 19 )
boxplot()関数を使用して、グループごとに箱ひげ図を作成することもできます。
#create scatterplot of sepal width vs. sepal length
boxplot(Sepal.Length~Species,
data=iris,
main=' Sepal Length by Species ',
xlab=' Species ',
ylab=' Sepal Length ',
col=' steelblue ',
border=' black ')
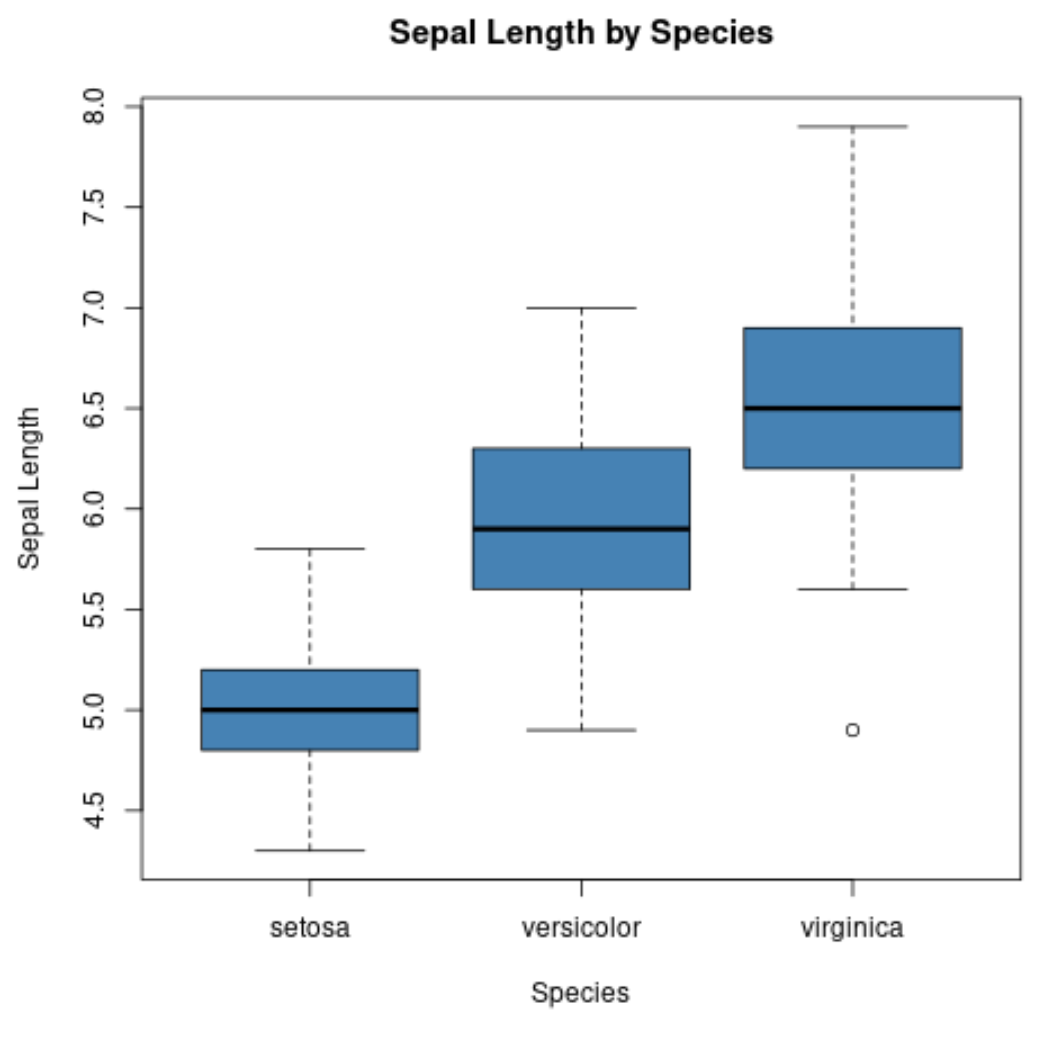
X 軸は 3 つの種を表示し、Y 軸は各種のがく片の長さの値の分布を表示します。
このタイプのプロットを使用すると、がく片の長さが virginica 種で最大となり、setosa 種で最小になる傾向があることがすぐにわかります。
追加リソース
次のチュートリアルでは、R でデータセットを要約する方法を詳しく説明します。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る