Sas で variance inflation factor (vif) を計算する方法
回帰分析では、2 つ以上の予測変数が相互に高度に相関しており、回帰モデル内で固有または独立した情報が提供されない場合に多重共線性が発生します。
変数間の相関度が十分に高い場合、回帰モデルのフィッティングと解釈の際に問題が発生する可能性があります。
多重共線性を検出する 1 つの方法は、分散膨張係数 (VIF)として知られる指標を使用することです。これは、回帰モデル内の説明変数間の相関と相関の強さを測定します。
このチュートリアルでは、SAS で VIF を計算する方法を説明します。
例: SAS での VIF の計算
この例では、10 人のバスケットボール選手の属性を記述するデータセットを作成します。
/*create dataset*/ data my_data; input rating points assists rebounds; datalines ; 90 25 5 11 85 20 7 8 82 14 7 10 88 16 8 6 94 27 5 6 90 20 7 9 76 12 6 6 75 15 9 10 87 14 9 10 86 19 5 7 ; run ; /*view dataset*/ proc print data =my_data;
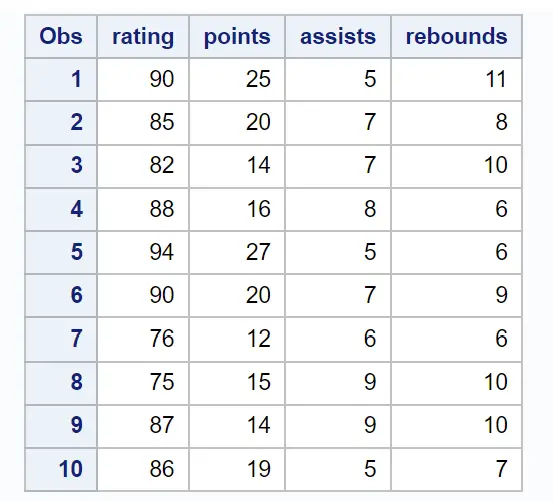
応答変数としてスコアリングを使用し、予測変数としてポイント、アシスト、およびリバウンドを使用して重線形回帰モデルを近似したいとします。
PROC REGを使用して、この回帰モデルをVIFオプションで近似し、モデル内の各予測子変数の VIF 値を計算できます。
/*fit regression model and calculate VIF values*/ proc reg data =my_data; model rating = points assists rebounds / lively ; run ;
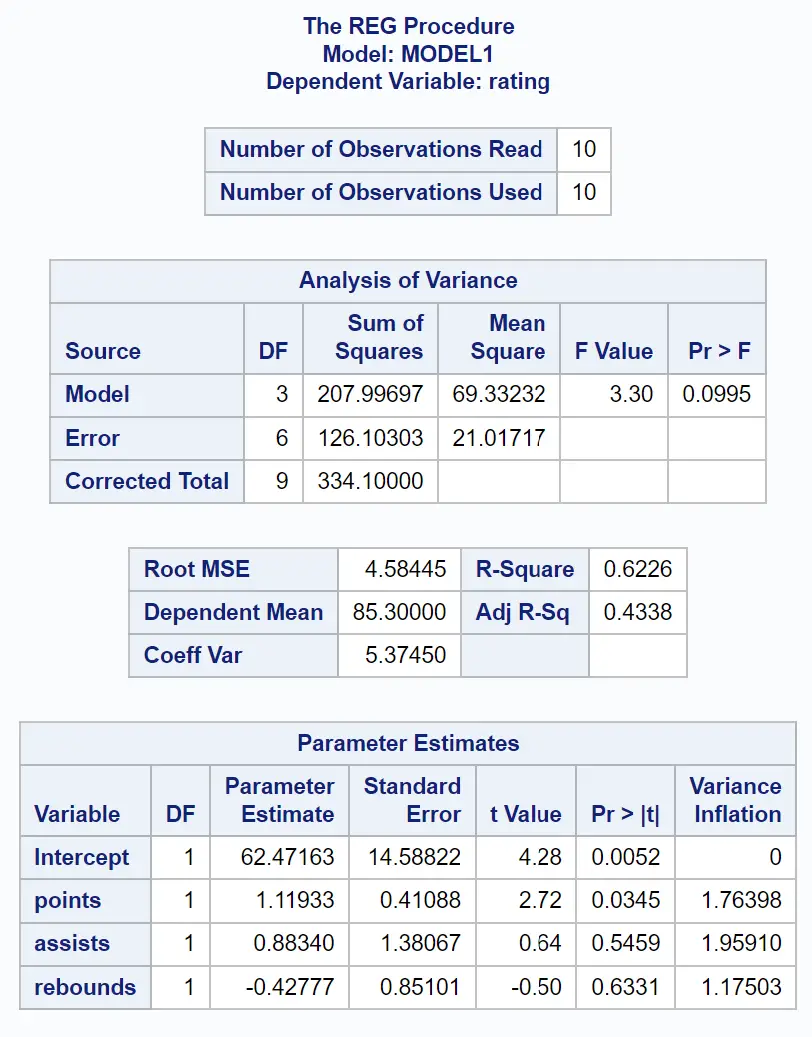
パラメーター推定テーブルから、各予測子変数の VIF 値を確認できます。
- ポイント: 1.76398
- アシスト数: 1.96591
- リバウンド: 1.17503
注:この値は関係ないため、テンプレート内の「Intercept」の VIF は無視してください。
VIF 値は 1 から始まり、上限はありません。 VIF を解釈するための一般的なルールは次のとおりです。
- 値1は、モデル内の特定の予測子変数と他の予測子変数の間に相関がないことを示します。
- 1 ~ 5の値は、モデル内の特定の予測子変数と他の予測子変数の間に中程度の相関関係があることを示しますが、多くの場合、特別な注意を必要とするほど深刻ではありません。
- 5より大きい値は、モデル内の特定の予測子変数と他の予測子変数の間に重大な相関関係がある可能性があることを示します。この場合、回帰結果の係数推定値と p 値は信頼できない可能性があります。
回帰モデルの予測変数の各 VIF 値は 1 に近いため、この例では多重共線性は問題になりません。
多重共線性にどう対処するか
多重共線性が回帰モデルの問題であると判断した場合、それを解決する一般的な方法がいくつかあります。
1. 相関性の高い変数を 1 つ以上削除します。
これはほとんどの場合最も迅速な解決策であり、削除する変数はとにかく冗長であり、モデルに固有の情報や独立した情報をほとんど追加しないため、多くの場合は許容可能な解決策です。
2. 予測子変数を何らかの方法で加算または減算するなど、何らかの方法で線形的に結合します。
そうすることで、両方の変数からの情報を包含する新しい変数を作成でき、多重共線性の問題はなくなります。
3. 主成分分析や部分最小二乗 (PLS) 回帰など、相関性の高い変数を考慮した分析を実行します。
これらの手法は、相関性の高い予測変数を処理するために特別に設計されています。
追加リソース
次のチュートリアルでは、SAS で他の一般的なタスクを実行する方法について説明します。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る