パンダ: excel ファイルを読み取るときに行をスキップする方法
次のメソッドを使用して、Excel ファイルを pandas DataFrame に読み取るときに行をスキップできます。
方法 1: 特定の行をスキップする
#import DataFrame and skip row in index position 2 df = pd. read_excel (' my_data.xlsx ', skiprows=[ 2 ])
方法 2: 複数の特定の行を無視する
#import DataFrame and skip rows in index positions 2 and 4 df = pd. read_excel (' my_data.xlsx ' , skiprows=[2,4 ] )
方法 3: 最初の N 行を無視する
#import DataFrame and skip first 2 rows df = pd. read_excel (' my_data.xlsx ', skiprows= 2 )
次の例は、 player_data.xlsxという Excel ファイルを使用して各メソッドを実際に使用する方法を示しています。
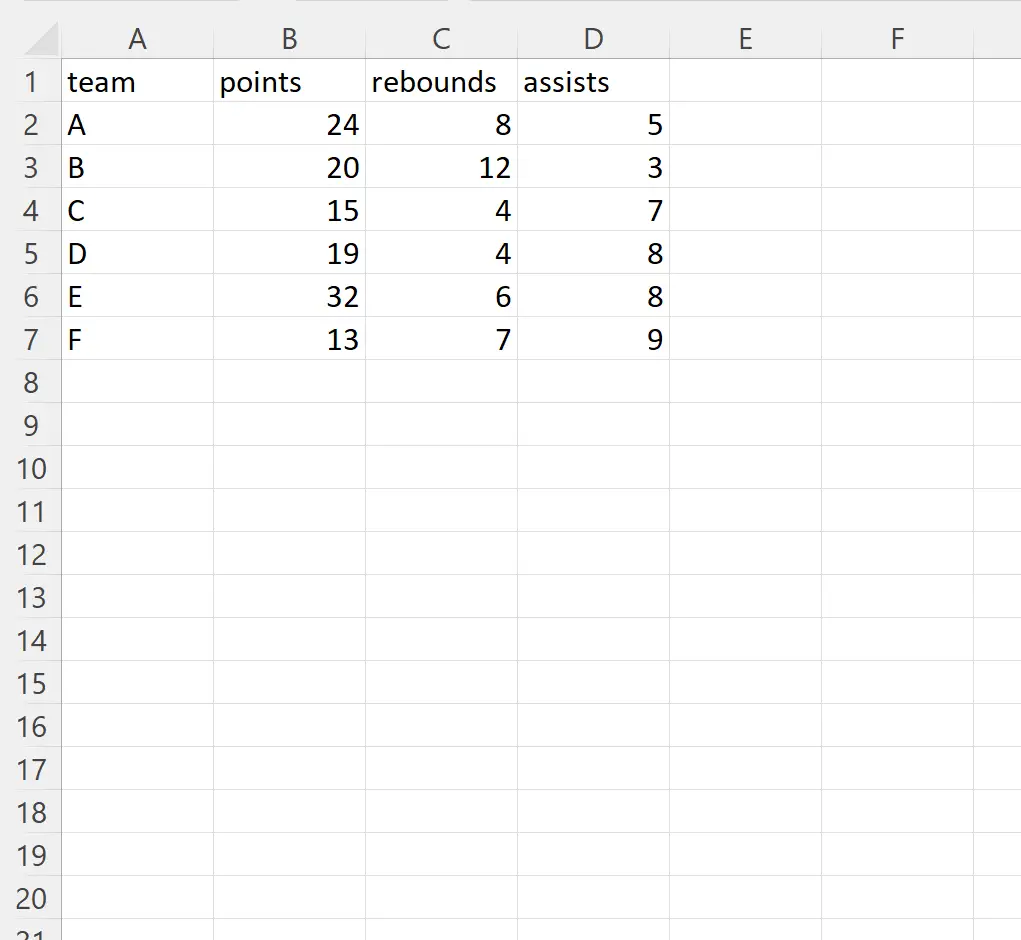
例 1: 特定の行を無視する
次のコードを使用して Excel ファイルをインポートし、インデックス位置 2 の行を無視できます。
import pandas as pd #import DataFrame and skip row in index position 2 df = pd. read_excel (' player_data.xlsx ', skiprows=[ 2 ]) #view DataFrame print (df) team points rebound assists 0 to 24 8 5 1 C 15 4 7 2 D 19 4 8 3 E 32 6 8 4 F 13 7 9
Excel ファイルを pandas DataFrame にインポートするときに、インデックス位置 2 の行 (チーム「B」) が無視されることに注意してください。
注: Excel ファイルの最初の行は行 0 とみなされます。
例 2: 複数の特定の行を無視する
次のコードを使用して Excel ファイルをインポートし、インデックス位置 2 と 4 の行を無視できます。
import pandas as pd #import DataFrame and skip rows in index positions 2 and 4 df = pd. read_excel (' player_data.xlsx ', skiprows=[ 2,4 ] ) #view DataFrame print (df) team points rebound assists 0 to 24 8 5 1 C 15 4 7 2 E 32 6 8 3 F 13 7 9
Excel ファイルを pandas DataFrame にインポートするときに、インデックス位置 2 と 4 の行 (チーム「B」と「D」) が無視されることに注意してください。
例 3: 最初の N 行を無視する
次のコードを使用して Excel ファイルをインポートし、最初の 2 行を無視できます。
import pandas as pd #import DataFrame and skip first 2 rows df = pd. read_excel (' player_data.xlsx ', skiprows= 2 ) #view DataFrame print (df) B 20 12 3 0 C 15 4 7 1 D 19 4 8 2 E 32 6 8 3 F 13 7 9
Excel ファイルの最初の 2 行がスキップされ、次に使用可能な行 (チーム「B」) が DataFrame のヘッダー行になっていることに注意してください。
追加リソース
次のチュートリアルでは、Python で他の一般的なタスクを実行する方法について説明します。
Pandas で Excel ファイルを読み取る方法
Pandas DataFrame を Excel にエクスポートする方法
NumPy 配列を CSV ファイルにエクスポートする方法
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る