R でフィッシャーの最小有意差 (lsd) を使用する方法
一元配置分散分析は、 3 つ以上の独立したグループの平均間に統計的に有意な差があるかどうかを判断するために使用されます。
一元配置分散分析で使用される仮定は次のとおりです。
- H 0 : 平均は各グループで等しい。
- H A : 少なくとも 1 つの方法は他の方法とは異なります。
ANOVA のp 値が特定の有意レベル (α = 0.05 など) を下回っている場合、帰無仮説を棄却し、グループ平均の少なくとも 1 つが他の平均とは異なると結論付けることができます。
しかし、どのグループが互いに異なっているかを正確に知るには、事後テストを行う必要があります。
一般的に使用される事後検定は、フィッシャーの最小有意差 (LSD) 検定です。
agricolaeパッケージのLSD.test()関数を使用して、R でこのテストを実行できます。
次の例は、この関数を実際に使用する方法を示しています。
例: R でのフィッシャーの LSD テスト
教授が、3 つの異なる学習方法が生徒間でテストの得点に差をもたらすかどうかを知りたいと考えているとします。
これをテストするために、彼女は 10 人の生徒をランダムに割り当てて各学習手法を使用させ、試験結果を記録しました。
次の表は、使用した学習手法に基づいた各生徒の試験結果を示しています。
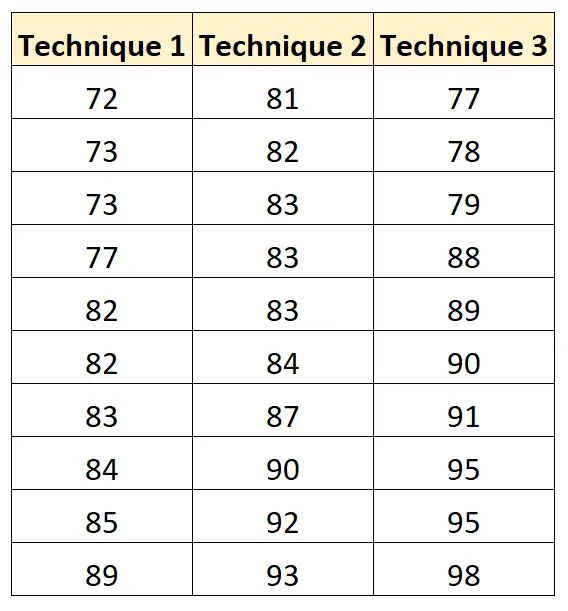
次のコードを使用してこのデータセットを作成し、R で一元配置分散分析を実行できます。
#create data frame
df <- data. frame (technique = rep(c("tech1", "tech2", "tech3"), each = 10 ),
score = c(72, 73, 73, 77, 82, 82, 83, 84, 85, 89,
81, 82, 83, 83, 83, 84, 87, 90, 92, 93,
77, 78, 79, 88, 89, 90, 91, 95, 95, 98))
#view first six rows of data frame
head(df)
technical score
1 tech1 72
2 tech1 73
3 tech1 73
4 tech1 77
5 tech1 82
6 tech1 82
#fit one-way ANOVA
model <- aov(score ~ technique, data = df)
#view summary of one-way ANOVA
summary(model)
Df Sum Sq Mean Sq F value Pr(>F)
technical 2 341.6 170.80 4.623 0.0188 *
Residuals 27,997.6 36.95
---
Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
ANOVA 表の p 値 (0.0188) は 0.05 未満であるため、3 つのグループ間の試験の平均得点はすべて等しくないと結論付けることができます。
したがって、フィッシャーの LSD 検定を実行して、どのグループの平均値が異なるかを判断できます。
次のコードは、これを行う方法を示しています。
library (agricolae)
#perform Fisher's LSD
print( LSD.test (model," technic "))
$statistics
MSerror Df Mean CV t.value LSD
36.94815 27 84.6 7.184987 2.051831 5.57767
$parameters
test p.adjusted name.t ntr alpha
Fisher-LSD none technical 3 0.05
$means
std score r LCL UCL Min Max Q25 Q50 Q75
tech1 80.0 5.868939 10 76.05599 83.94401 72 89 74.00 82.0 83.75
tech2 85.8 4.391912 10 81.85599 89.74401 81 93 83.00 83.5 89.25
tech3 88.0 7.557189 10 84.05599 91.94401 77 98 81.25 89.5 94.00
$comparison
NULL
$groups
score groups
tech3 88.0 a
tech2 85.8a
tech1 80.0 b
attr(,"class")
[1] “group”
結果の中で最も興味深い部分は、 $groupsと呼ばれるセクションです。グループ列に異なる文字が含まれるテクニックは非常に異なります。
結果から次のことがわかります。
- テクニック 1 とテクニック 3 の平均試験スコアは大きく異なります (tech1 の値は「b」、tech3 の値は「a」であるため)。
- テクニック 1 とテクニック 2 の平均試験スコアは大きく異なります (tech1 の値は「b」、tech2 の値は「a」であるため)。
- テクニック 2 とテクニック 3 の平均試験スコアは大きく異なりません(両方とも「a」値を持っているため)。
追加リソース
次のチュートリアルでは、R で他の一般的なタスクを実行する方法について説明します。
R で一元配置分散分析を実行する方法
R で Bonferroni 事後テストを実行する方法
R でシェッフェ事後テストを実行する方法
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る