ランダムな選択またはランダムな割り当て
ランダム選択とランダム割り当ては、よく使用される 2 つの統計手法ですが、しばしば混同されます。
ランダム選択とは、研究に参加する個人を母集団からランダムに選択するプロセスを指します。
ランダム割り当てとは、研究に参加している個人を治療グループまたは対照グループにランダムに割り当てるプロセスを指します。
ランダム選択は、個人を研究に「参加させる」ためのプロセスと考えることができ、ランダム割り当ては、研究の一部として選択された後にその個人に対して「行う」ことと考えることができます。
ランダムな選択とランダムな割り当ての重要性
研究でランダム選択が使用される場合、ランダムなプロセスを使用して母集団から個人が選択されます。たとえば、母集団に 1,000 人の個人がいる場合、コンピューターを使用してデータベースからそれらの個人のうち 100 人をランダムに選択できます。これは、各個人が研究の参加者として選ばれる確率が同じであることを意味し、代表的なサンプル、つまり一般集団と同様の特徴を持つサンプルを取得する可能性が高まります。
研究で代表的なサンプルを使用することで、研究の結果を母集団に一般化することができます。統計用語では、これは外部妥当性があると呼ばれます。つまり、結果を一般集団に対して外部化することが妥当です。
研究でランダム割り当てが使用される場合、個人は治療グループまたは対照グループにランダムに割り当てられます。たとえば、研究に 100 人の個人が参加している場合、乱数発生器を使用して、50 人の個人を対照グループに、50 人の個人を治療グループにランダムに割り当てることができます。
ランダムな割り当てを使用することにより、2 つのグループがほぼ同様の特性を持つ可能性が高まります。これは、2 つのグループ間で観察された差異が治療に起因する可能性があることを意味します。これは、この研究には内部的妥当性があることを意味します。つまり、グループ内の個人間の差異ではなく、グループ間の差異を治療そのものに帰することは正当です。
ランダム選択とランダム割り当ての例
研究では、ランダム選択とランダム割り当ての両方を使用することも、これらの手法の 1 つだけを使用することも、どちらの手法も使用しないことも可能です。強力な研究とは、両方のテクニックを使用する研究です。
次の例は、研究でこれらの手法の両方を使用する方法、一方を使用する方法、またはどちらも使用しない方法と、その結果として生じる効果を示しています。
例 1: ランダム選択とランダム割り当ての両方を使用する
研究:研究者らは、10,000 人の特定のコミュニティにおいて、新しい食事療法が標準的な食事療法よりも大きな体重減少をもたらすかどうかを知りたいと考えています。彼らは、コンピューターを使用してデータベースから 100 人の名前をランダムに選択することにより、研究に参加する 100 人を募集します。 100 人全員が揃ったら、再びコンピューターを使用して、50 人を対照グループ (標準的な食事に固執するなど) にランダムに割り当て、50 人を治療グループ (新しい食事に従うなど) に割り当てます。彼らは、1か月後の各個人の総体重減少を記録します。
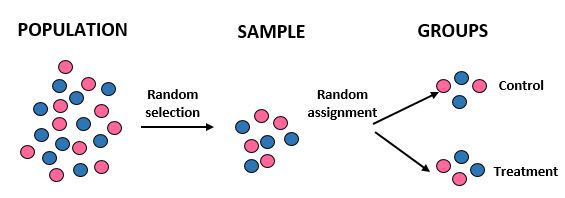
結果:研究者らは、サンプルを取得するためにランダム選択を使用し、個人を治療グループまたは対照グループに割り当てる際にランダムな割り当てを行いました。そうすることで、研究結果を人口全体に一般化して、 2 つのグループ間の平均体重減少の違いを新しい食事のせいにすることができます。
例 2: ランダムな選択のみを使用する
研究:研究者らは、10,000 人の特定のコミュニティにおいて、新しい食事療法が標準的な食事療法よりも大きな体重減少をもたらすかどうかを知りたいと考えています。彼らは、コンピューターを使用してデータベースから 100 人の名前をランダムに選択することにより、研究に参加する 100 人を募集します。しかし、彼らは性別のみに基づいて個人をグループに分けることを決定しました。女性は対照群に割り当てられ、男性は治療群に割り当てられます。彼らは、1か月後の各個人の総体重減少を記録します。
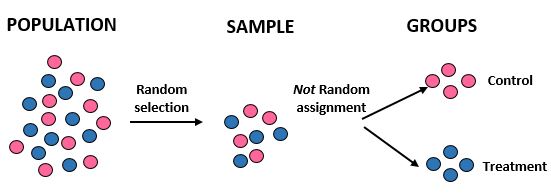
結果:研究者らはサンプルを取得するためにランダム選択を使用しましたが、個人を治療グループまたは対照グループに割り当てる際にはランダム割り当てを使用しませんでした。代わりに、特定の要素、つまり性別を使用して、個人をどのグループに割り当てるかを決定しました。そうすることで、研究結果を集団全体に一般化することはできますが、2 つのグループ間の平均体重減少の違いを新しい食事のせいにすることはできません。体重減少の違いは、実際には新しい食事ではなく単に性別によるものである可能性があるため、この研究の内部妥当性は損なわれました。
例 3: ランダムな割り当てのみを使用する
研究:研究者らは、10,000 人の特定のコミュニティにおいて、新しい食事療法が標準的な食事療法よりも大きな体重減少をもたらすかどうかを知りたいと考えています。彼らは研究に参加する男性アスリート100人を募集している。次に、コンピューター プログラムを使用して、50 人の男性アスリートを対照グループに、50 人を治療グループにランダムに割り当てます。彼らは、1か月後の各個人の総体重減少を記録します。
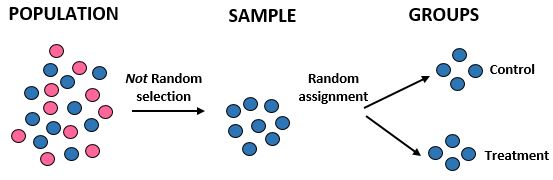
結果:研究者らは、特に 100 人の男性アスリートを選択したため、サンプルを取得するためにランダム選択を使用しませんでした。このため、彼らのサンプルは母集団全体を代表するものではなく、したがってその外部的妥当性が損なわれます。研究結果を母集団全体に一般化することはできません。ただし、彼らはランダムな割り当てを使用しました。つまり、体重減少の違いは新しい食事によるものである可能性があります。
例 4: どちらの手法も使用しない
研究:研究者らは、10,000 人の特定のコミュニティにおいて、新しい食事療法が標準的な食事療法よりも大きな体重減少をもたらすかどうかを知りたいと考えています。彼らは研究に参加する男性アスリート50名と女性アスリート50名を募集している。次に、すべての女性アスリートを対照グループに割り当て、すべての男性アスリートを治療グループに割り当てます。彼らは、1か月後の各個人の総体重減少を記録します。
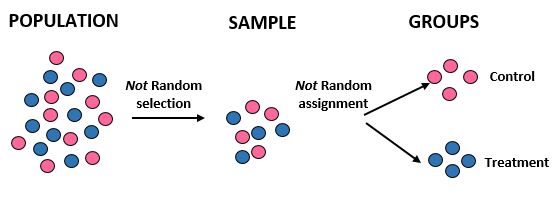
結果:研究者らは、特に 100 人のアスリートを選択したため、サンプルを取得するためにランダム選択を使用しませんでした。このため、彼らのサンプルは母集団全体を代表するものではなく、したがってその外部的妥当性が損なわれます。研究結果を母集団全体に一般化することはできません。さらに、ランダムな割り当てに依存するのではなく、性別に基づいて個人をグループに分けます。これは、個人の内的妥当性も損なわれることを意味します。つまり、体重減少の違いは、食事ではなく性別によるものである可能性があります。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る