仮説の対比
この記事では、統計学における仮説検定とは何かについて説明します。したがって、仮説テストの方法、さまざまな種類の仮説テスト、および仮説テストを実行するときに起こり得る間違いについて学びます。
仮説検証とは何ですか?
仮説検定は、統計的仮説を棄却または棄却するために使用される手順です。仮説検定では、母集団パラメータの値が、その母集団のサンプルで観察されたものと一致するかどうかを判断します。
つまり、仮説検定では、統計サンプルが分析され、得られた結果に基づいて、以前に確立された仮説を棄却するか受け入れるかが決定されます。
一般に、仮説検定からは、仮説が真であるか偽であるかを完全に確実に推論することはできず、得られた結果に基づいて仮説が単に棄却されるか否かが推測されることに留意してください。したがって、仮説をテストする場合、下された決定が最も可能性が高いという統計的証拠がある場合でも、エラーが発生する可能性があります。
統計学では、仮説検定は、仮説検定、仮説検定、 または有意検定 とも呼ばれます。
仮説検定の理論はイギリスの統計学者ロナルド・フィッシャーによって確立され、イェジー・ネイマンとエゴン・ピアソンによってさらに発展させられました。
帰無仮説と対立仮説
仮説検定は、次の 2 種類の統計的仮説で構成されます。
- 帰無仮説 (H 0 ) : これは、母集団パラメータに関して持っている最初の仮説が偽であることを維持する仮説です。したがって、帰無仮説は棄却したい仮説です。
- 対立仮説 (H 1 ) : その真実性が証明されると考えられる研究仮説です。つまり、対立仮説は研究者の事前仮説であり、それが正しいことを証明するために対照仮説が実行されます。
実際には、対立仮説は帰無仮説よりも先に定式化されます。これは、対立仮説はデータサンプルの統計分析によって裏付けられることを目的とした仮説であるためです。帰無仮説は対立仮説を否定するだけで定式化されます。
仮説検定の種類
仮説検定は 2 つの異なるタイプに分類できます。
- 両側仮説検定 (または両側仮説検定) : 仮説検定の対立仮説は、母集団パラメーターが特定の値と「異なる」ことを示します。
- 片側仮説検定 (または片側仮説検定) : 仮説検定の対立仮説は、母集団パラメーターが特定の値よりも「大きい」 (右の尾) か、「小さい」 (左の尾) ことを示します。
両側仮説検定
![\begin{cases}H_0: \mu=\mu_0\\[2ex]H_1:\mu\neq\mu_0\end{cases}](https://statorials.org/wp-content/ql-cache/quicklatex.com-4f0c1b65b50009900a6facbefea23ca1_l3.png "Rendered by QuickLaTeX.com")
片側仮説検定 (右尾)
![\begin{cases}H_0: \mu\leq \mu_0\\[2ex]H_1:\mu>\mu_0\end{cases}” title=”Rendered by QuickLaTeX.com” height=”65″ width=”102″ style=”vertical-align: 0px;”></p>
</p>
</div>
<div class=](https://statorials.org/wp-content/ql-cache/quicklatex.com-1393df603c93485a0f75ebd0116c46a2_l3.png)
片側仮説検定 (左尾)
![\begin{cases}H_0: \mu\geq\mu_0\\[2ex]H_1:\mu<\mu_0\end{cases}](https://statorials.org/wp-content/ql-cache/quicklatex.com-570fdfa44817f5392b33075476008f80_l3.png "Rendered by QuickLaTeX.com")
仮説検定の棄却領域と受容領域
以下で詳しく説明しますが、仮説検定は、各タイプの仮説検定の特性値を計算することで構成され、この値は仮説検定統計量と呼ばれます。したがって、コントラスト統計が計算されたら、結論に達するには、それが次の 2 つの領域のどちらに位置するかを観察する必要があります。
- 棄却領域 (または臨界領域) : これは、帰無仮説の棄却 (および対立仮説の受け入れ) を含む仮説検定参照分布のグラフの領域です。
- 受容領域: これは、帰無仮説の受容 (および対立仮説の棄却) を意味する仮説検定参照分布のグラフの領域です。
つまり、検定統計量が棄却ゾーン内にある場合、帰無仮説は棄却され、対立仮説が受け入れられます。逆に、検定統計量が許容範囲内にある場合は、帰無仮説が受け入れられ、対立仮説が棄却されます。
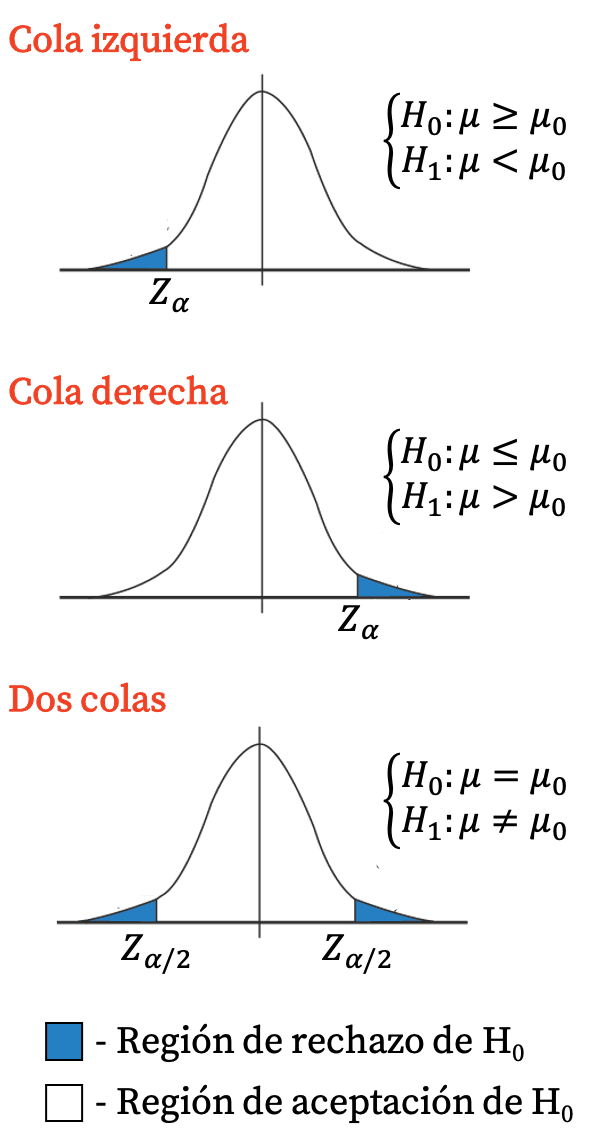
拒絶領域と許容領域の境界を確立する値は臨界値と呼ばれ、同様に、拒絶領域を定義する値の間隔は信頼区間と呼ばれます。そして、両方の値は選択した有意水準によって異なります。
一方、帰無仮説を棄却するか受け入れるかの決定は、仮説検定から得られたp 値(または p 値) を選択した有意水準と比較することによって行うこともできます。
仮説検定のやり方
仮説検定を実行するには、次の手順に従う必要があります。
- 仮説検定の帰無仮説と対立仮説を述べます。
- 目的のアルファ (α) 有意水準を確立します。
- 仮説のコントラスト統計を計算します。
- 仮説検定の棄却領域と許容領域を知るために仮説検定の臨界値を決定します。
- 仮説のコントラスト統計量が棄却領域にあるか受容領域にあるかを観察します。
- 統計量が棄却領域内にある場合、帰無仮説は棄却されます (対立仮説は受け入れられます)。ただし、統計量が許容範囲内にある場合は、帰無仮説が受け入れられます (対立仮説は棄却されます)。
仮説検定のエラー
仮説検定では、1 つの仮説を拒否し、もう 1 つの検定仮説を受け入れると、次の 2 つのエラーのいずれかが発生する可能性があります。
- タイプ I エラー: これは、帰無仮説が実際には真であるにもかかわらず、帰無仮説を棄却するときに発生するエラーです。
- タイプ II エラー: これは、帰無仮説が実際には偽であるにもかかわらず、帰無仮説を受け入れることによって生じるエラーです。

一方、各タイプのエラーが発生する確率は次のように呼ばれます。
- アルファ確率 (α) : タイプ I エラーが発生する確率です。
- ベータ確率 (β) : タイプ II エラーが発生する確率です。
同様に、仮説検定の検出力は、帰無仮説 (H 0 ) が偽の場合に棄却される確率、つまり、対立仮説 (H 1 ) が真の場合に選択される確率として定義されます。したがって、仮説検定の検出力は 1-β に等しくなります。
仮説検定の統計
仮説検定の統計量は、帰無仮説が棄却されるかどうかを決定するために使用される仮説検定参照分布の値です。検定統計量が棄却領域に収まる場合、帰無仮説は棄却されます (対立仮説は受け入れられます)。一方、検定統計量が許容領域に収まる場合、帰無仮説は受け入れられます (対立仮説は受け入れられます)。拒否されました)。対立仮説)。
仮説検定統計量の計算は、検定の種類によって異なります。したがって、仮説検定の種類ごとに統計量を計算する式を以下に示します。
平均値の仮説検定
分散が既知の平均に対する仮説検定統計量の式は次のとおりです。

金:
-

は、平均に対する仮説対照統計量です。
-

はサンプル平均です。
-

は提案された平均値です。
-

は母集団の標準偏差です。
-

はサンプルサイズです。
平均の仮説検定統計量が計算されたら、その結果を解釈して帰無仮説を棄却するかどうかを判断する必要があります。
- 平均値の仮説検定が両側である場合、統計量の絶対値が臨界値 Z α/2より大きい場合、帰無仮説は棄却されます。
- 平均の仮説検定が右裾に一致する場合、統計量が臨界値 Z αより大きい場合、帰無仮説は棄却されます。
- 平均の仮説検定が左裾に一致する場合、統計量が臨界値 -Z αより小さい場合、帰無仮説は棄却されます。
![\begin{array}{l}H_1: \mu\neq \mu_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } |Z|>Z_{\alpha/2} \text{ se rechaza } H_0\\[3ex]H_1: \mu> \mu_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } Z>Z_{\alpha} \text{ se rechaza } H_0\\[3ex]H_1: \mu< \mu_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } Z<-Z_{\alpha} \text{ se rechaza } H_0\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-0e2ccadfc369eb7543b8f86dfccc528e_l3.png "Rendered by QuickLaTeX.com")
この場合、臨界値は標準化正規分布表から取得されます。
一方、分散が不明な平均の仮説検定統計量の式は次のとおりです。

金:
-

は平均の仮説検定統計量であり、スチューデントの t 分布によって定義されます。
-
はサンプル平均です。
-
は提案された平均値です。
-

は標本標準偏差です。
-
はサンプルサイズです。
前と同様に、帰無仮説を棄却するかどうかを決定するには、検定統計量の計算結果を臨界値で解釈する必要があります。
- 平均値の仮説検定が両側である場合、統計量の絶対値が臨界値 t α/2|n-1より大きい場合、帰無仮説は棄却されます。
- 平均の仮説検定が右裾に一致する場合、統計量が臨界値 t α|n-1より大きい場合、帰無仮説は棄却されます。
- 平均の仮説検定が左裾に一致する場合、統計量が臨界値 -t α|n-1より小さい場合、帰無仮説は棄却されます。
![\begin{array}{l}H_1: \mu\neq \mu_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } |t|>t_{\alpha/2|n-1} \text{ se rechaza } H_0\\[3ex]H_1: \mu> \mu_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } t>t_{\alpha|n-1} \text{ se rechaza } H_0\\[3ex]H_1: \mu< \mu_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } t<-t_{\alpha|n-1} \text{ se rechaza } H_0\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-31fb206b75a47181c7c673f54ba28ee8_l3.png "Rendered by QuickLaTeX.com")
分散が不明な場合、臨界検定値はスチューデントの分布表から取得されます。
割合の仮説検定
割合の仮説検定統計量の式は次のとおりです。

金:
-
は、割合の仮説検定統計量です。
-

はサンプルの割合です。
-

提案された比率の値です。
-
はサンプルサイズです。
-

は比率の標準偏差です。
比率の仮説検定統計量を計算するだけでは十分ではなく、結果を解釈する必要があることに注意してください。
- 比率の仮説検定が両側である場合、統計量の絶対値が臨界値 Z α/2より大きい場合、帰無仮説は棄却されます。
- 比率の仮説検定が右裾に一致する場合、統計量が臨界値 Z αより大きい場合、帰無仮説は棄却されます。
- 割合の仮説検定が左裾に一致する場合、統計量が臨界値 -Z αより小さい場合、帰無仮説は棄却されます。
![\begin{array}{l}H_1: p\neq p_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } |Z|>Z_{\alpha/2} \text{ se rechaza } H_0\\[3ex]H_1: p> p_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } Z>Z_{\alpha} \text{ se rechaza } H_0\\[3ex]H_1: p< p_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } Z<-Z_{\alpha} \text{ se rechaza } H_0\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-7d5bd583532769e3014286e8ffd94c9f_l3.png "Rendered by QuickLaTeX.com")
臨界値は標準正規分布表から簡単に取得できることを覚えておいてください。
分散の仮説検定
分散の仮説検定統計量を計算する式は次のとおりです。

金:
-

は分散の仮説検定統計量であり、カイ二乗分布を持ちます。
-
はサンプルサイズです。
-

は標本分散です。
-

は、提案された母集団の分散です。
統計の結果を解釈するには、得られた値をテストの臨界値と比較する必要があります。
- 分散の仮説検定が両側検定である場合、統計量が臨界値より大きい場合、帰無仮説は棄却されます。

またはクリティカル値が以下の場合

。
- 分散の仮説検定が右裾に一致する場合、統計量が臨界値より大きい場合、帰無仮説は棄却されます。

。
- 分散の仮説検定が左裾に一致する場合、統計量が臨界値未満であれば帰無仮説は棄却されます。

。
![\begin{array}{l}H_1: \sigma^2\neq \sigma_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } \chi^2>\chi^2_{1-\alpha/2|n-1}\text{ se rechaza } H_0\\[3ex]H_1: \sigma^2\neq \sigma_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si }\chi^2<\chi^2_{\alpha/2|n-1}\text{ se rechaza } H_0 \\[3ex]H_1: \sigma^2> \sigma_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } \chi^2>\chi^2_{1-\alpha|n-1}\text{ se rechaza } H_0\\[3ex]H_1: \sigma^2< \sigma_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } \chi^2<\chi^2_{\alpha|n-1}\text{ se rechaza } H_0\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-ca46378c1a2ee04b5cc5bfa93002fe9c_l3.png "Rendered by QuickLaTeX.com")
分散の重要仮説検定値は、カイ二乗分布表から取得されます。カイ二乗分布の自由度はサンプルサイズから 1 を引いたものであることに注意してください。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る