F分電盤の見方
このチュートリアルでは、 F 分布表を読み取って解釈する方法を説明します。
F分布表とは何ですか?
F分布表は、 F分布の臨界値を示す表である。 F 分布テーブルを使用するには、次の 3 つの値のみが必要です。
- 分子の自由度
- 分母の自由度
- アルファ レベル (一般的な選択肢は 0.01、0.05、0.10)
次の表は、alpha = 0.10 の場合の F 分布表を示しています。表の上部の数字は分子の自由度 (表ではDF1と表示) を表し、表の左側の数字は分母の自由度 (表ではDF2と表示) を表します。
表をクリックして拡大してください。
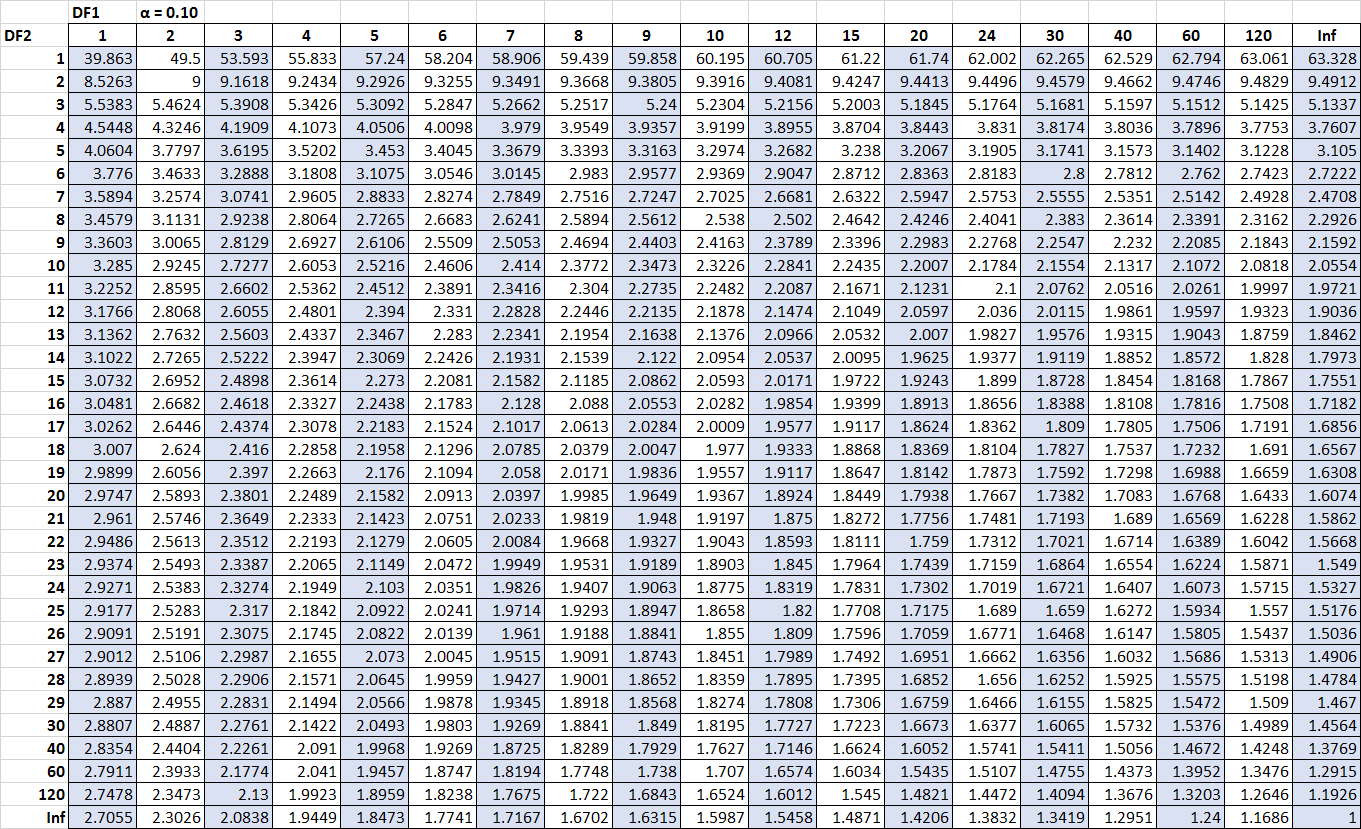
表内の臨界値は、F 検定の F 統計量と比較されることがよくあります。 F 統計量が表にある臨界値より大きい場合、F 検定の帰無仮説を棄却し、検定の結果が統計的に有意であると結論付けることができます。
F分布表の使用例
F 分布表は、F 検定の臨界値を見つけるために使用されます。 F テストを実行する最も一般的なシナリオは次の 3 つです。
- 回帰分析における F 検定は、回帰モデルの全体的な有意性を検定します。
- ANOVA (分散分析) での F 検定は、グループ平均間の全体的な差異を検定します。
- F 検定を使用して、2 つの母集団の分散が等しいかどうかを確認します。
これらの各シナリオで F 分布テーブルを使用する例を見てみましょう。
回帰分析における F 検定
学習時間と受けた予備試験を予測変数として、最終試験の成績を応答変数として使用して重回帰分析を実行するとします。回帰分析を実行すると、次の結果が得られます。
| ソース | SS | DF | MS。 | F | P. |
|---|---|---|---|---|---|
| 回帰 | 546.53 | 2 | 273.26 | 5.09 | 0.033 |
| 残留物 | 483.13 | 9 | 53.68 | ||
| 合計 | 1029.66 | 11 |
回帰分析では、f 統計量は回帰 MS/残差 MS として計算されます。この統計は、回帰モデルが独立変数を含まないモデルよりもデータによく適合するかどうかを示します。基本的に、回帰モデル全体が有用かどうかをテストします。
この例では、 F 統計は 273.26 / 53.68 = 5.09 です。
この F 統計量が alpha = 0.05 レベルで有意であるかどうかを知りたいとします。分子の自由度2 (回帰の df)と分母の自由度9 (残差の df)で alpha = 0.05 の F 分布表を使用すると、臨界値 F が4, 2565であることがわかります。
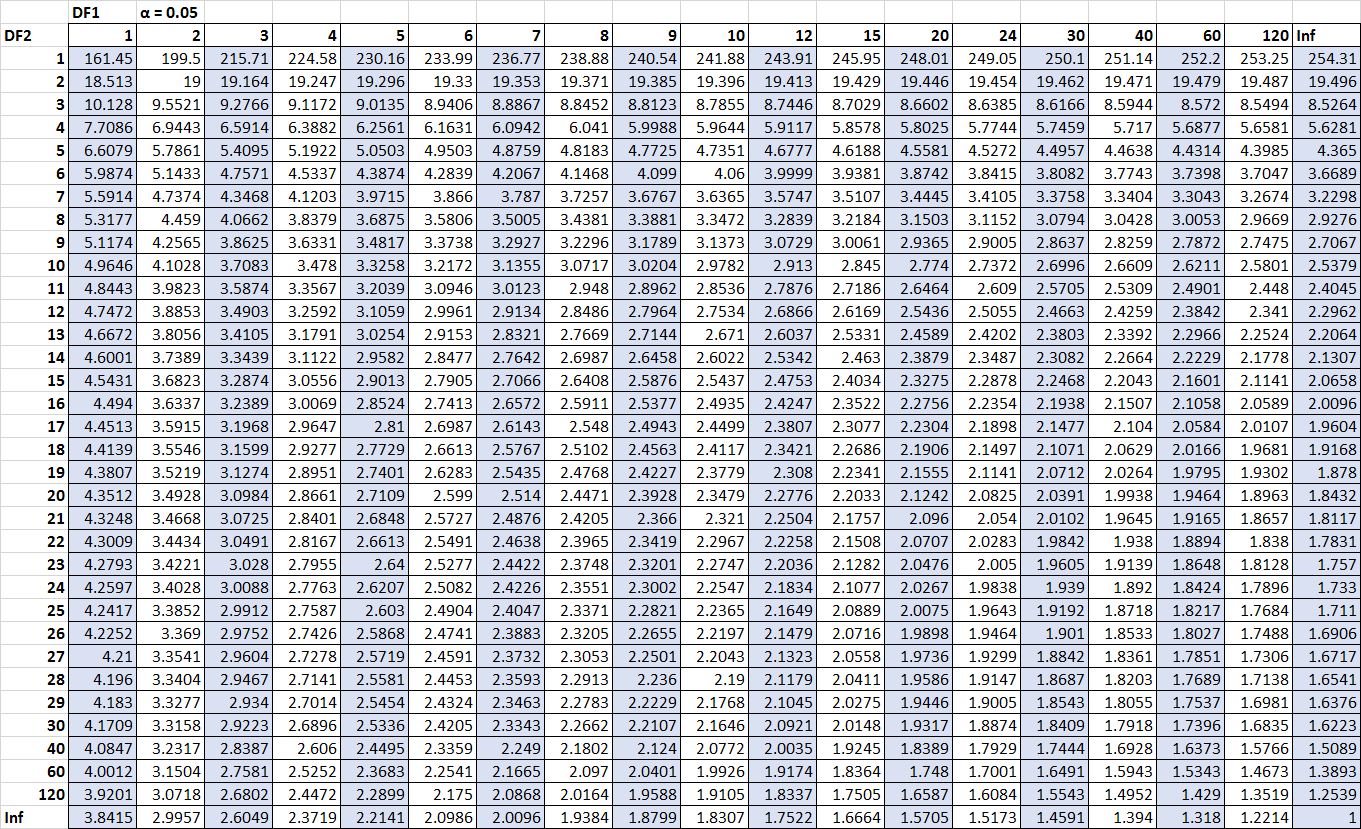
統計 f( 5.09 ) が臨界値 F( 4.2565)より大きいため、回帰モデル全体が統計的に有意であると結論付けることができます。
ANOVA での F 検定
3 つの異なる学習手法が異なるテスト結果につながるかどうかを知りたいとします。これをテストするために、60 名の学生を募集します。私たちは 20 人の学生をそれぞれランダムに割り当て、試験に備えて 1 か月間 3 つの学習テクニックのいずれかを使用します。すべての生徒が試験を受けたら、一元配置分散分析を実行して、学習テクニックが試験結果に影響を与えるかどうかを判断します。次の表は、一元配置分散分析の結果を示しています。
| ソース | SS | DF | MS。 | F | P. |
|---|---|---|---|---|---|
| 処理 | 58.8 | 2 | 29.4 | 1.74 | 0.217 |
| エラー | 202.8 | 12 | 16.9 | ||
| 合計 | 261.6 | 14 |
ANOVA では、f 統計量は治療 MS/誤差 MS として計算されます。この統計は、3 つのグループの平均スコアが等しいかどうかを示します。
この例では、 F 統計量は 29.4 / 16.9 = 1.74 です。
この F 統計量が alpha = 0.05 レベルで有意であるかどうかを知りたいとします。分子の自由度2 (治療の df)と分母の自由度12 (誤差の df)で alpha = 0.05 の F 分布表を使用すると、臨界値 F が3, 8853であることがわかります。
f 統計量 ( 1.74 ) は臨界値 F ( 3.8853)より大きくないため、3 つのグループの平均スコア間に統計的に有意な差はないと結論付けます。
2 つの母集団の等分散に対する F 検定
2 つの母集団の分散が等しいかどうかを知りたいとします。これをテストするには、各母集団から 25 個の観測値のランダムなサンプルを採取し、各サンプルのサンプル分散を求める等分散の F 検定を実行できます。
この F 検定の検定統計量は次のように定義されます。
統計量 F = s 1 2 / s 2 2
ここで、s 1 2と s 2 2は標本分散です。この比率が 1 から遠ざかるほど、母集団内の分散が不均等である証拠が強くなります。
F テストの臨界値は次のように定義されます。
臨界値 F = 自由度 n 1 -1 および n 2 -1、有意水準 α をもつ分布表 F で見つかった値。
サンプル 1 のサンプル分散が 30.5、サンプル 2 のサンプル分散が 20.5 であると仮定します。これは、検定統計量が 30.5 / 20.5 = 1.487であることを意味します。この検定統計量が alpha = 0.10 で有意であるかどうかを調べるには、alpha = 0.10、分子 df = 24、分母 df = 24 に関連付けられた F 分布表で臨界値を見つけることができます。この数値は1.7019 であることがわかります。 。
統計量 f( 1.487 ) は臨界値 F( 1.7019)より大きくないため、これら 2 つの母集団の分散間に統計的に有意な差はないと結論付けます。
追加リソース
アルファ値 0.001、0.01、0.025、0.05、および 0.10 の F 分布表の完全なセットについては、このページを参照してください。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る