Sas: 正しい部分文字列を抽出する方法
SAS のSUBSTR関数を使用して、文字列の一部を抽出できます。
この関数は次の基本構文を使用します。
SUBSTR(ソース、位置、N)
金:
- ソース: 分析するチャネル
- Position : 読み取りの開始位置
- N : 読み込む文字数
Position引数の値は、文字列の左側の開始位置を指定します。
代わりに、文字列の右側に開始位置を指定するには、次の構文を使用できます。
data new_data;
set original_data;
last_three = substr (team , length (team) -2,3 );
run ;
この特定の例では、 last_threeという新しい変数を作成し、 teamという文字列変数の右側の最後の 3 文字を抽出します。
次の例は、この構文を実際に使用する方法を示しています。
例: SAS の Right から部分文字列を抽出する
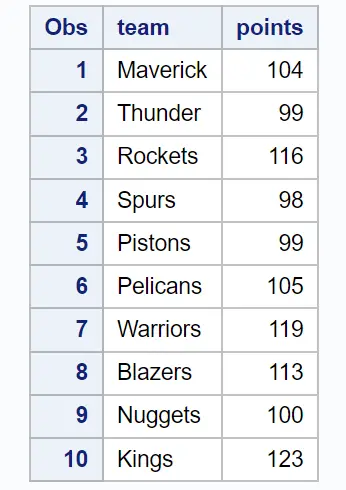
SAS に、さまざまなバスケットボール チームに関する情報を含む次のデータセットがあるとします。
/*create dataset*/
data original_data;
input team $points;
datalines ;
Mavericks 104
Thunder 99
Rockets 116
Spurs 98
Pistons 99
Pelicans 105
Warriors 119
Blazers 113
Nuggets 100
Kings 123
;
run ;
/*view dataset*/
proc print data = original_data;
次のコードを使用して、チーム変数から最後の 3 文字を抽出できます。
/*create new dataset*/
data new_data;
set original_data;
last_three = substr (team , length (team) -2,3 );
run ;
/*view new dataset*/
proc print data = new_data;
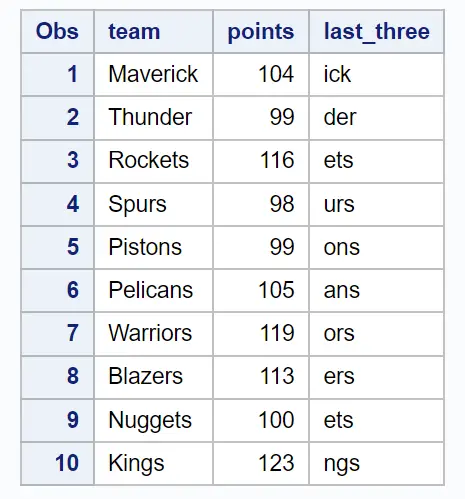
last_threeという列には、チーム列の最後の 3 文字が含まれていることに注意してください。
SUBSTR関数の値を簡単に変更して、文字列の右側から異なる数の文字を抽出することもできます。
たとえば、次の構文を使用して、右側から最後の 5 文字を抽出できます。
/*create new dataset*/
data new_data;
set original_data;
last_five = substr (team , length (team) -4,5 );
run ;
/*view new dataset*/
proc print data = new_data;
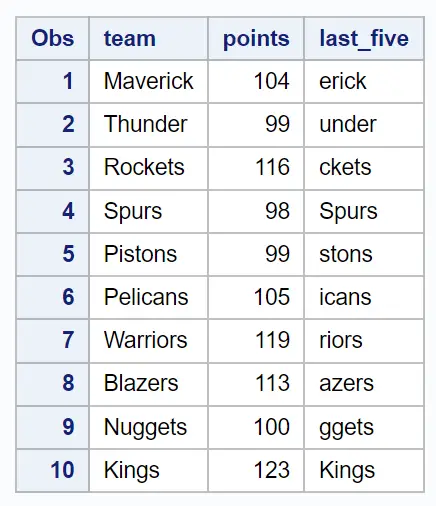
last_fiveという列には、チーム列の最後の 5 文字が含まれていることに注意してください。
追加リソース
次のチュートリアルでは、SAS で他の一般的なタスクを実行する方法について説明します。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る