基準変数とは何ですか? (説明+例)
基準変数は、従属変数または応答変数の単なる別名です。統計分析で予測される変数です。
説明変数に予測子変数や独立変数などの異なる名前があるのと同様に、応答変数にも従属変数や基準変数などの交換可能な名前があります。
基準変数の例にはどのようなものがありますか?
次のシナリオは、いくつかの異なるコンテキストにおける基準変数の例を示しています。
例 1: 単純な線形回帰
単純線形回帰は、 2 つの変数 x と y の間の関係を理解するために使用される統計手法です。変数 x は、予測子変数として知られています。もう 1 つの変数 y は、基準変数または応答変数として知られています。
単純な線形回帰では、予測変数と基準変数の間の関係を表す「最適な直線」が見つかります。
たとえば、学習時間を予測変数として、テストのスコアを基準変数として使用して、単純な線形回帰モデルをデータセットに当てはめることができます。この場合、単純な線形回帰を使用して、基準変数テスト スコアの値の予測を試みます。
または、別の例として、重みを使用して単純な線形回帰モデルをデータセットに当てはめて、人々のグループのサイズの値を予測することもできます。この場合、予測したい値は身長であるため、基準変数は身長です。
身長と体重の値を散布図にプロットすると、基準変数の高さがY 軸になります。
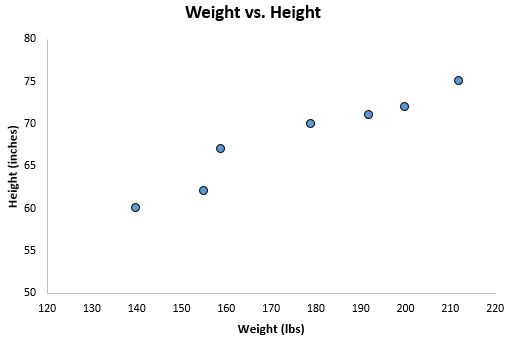
一般に、散布図を作成するとき、基準変数は Y 軸に沿って配置され、予測変数は X 軸に沿って配置されます。
例 2: 重回帰
多重線形回帰は、基準変数の値を予測するために複数の予測子変数を使用することを除いて、単純線形回帰に似ています。
たとえば、予測変数の学習時間とテスト前夜の睡眠時間を使用して、基準変数のテスト得点値を予測できます。この場合、基準変数はこの分析で予測される変数です。
例 3: 分散分析
ANOVA (分散分析) は、3 つ以上の独立したグループの平均間に統計的に有意な差があるかどうかを判断するために使用される統計手法です。
たとえば、3 つの異なる運動プログラムが減量に異なる影響を与えるかどうかを判断したい場合があります。私たちが研究する予測変数は運動プログラムであり、3 つのレベルがあります。
基準変数はポンド単位で測定される体重減少です。 一元配置分散分析を実行して、3 つのプログラムによる体重減少の間に統計的に有意な差があるかどうかを判断できます。
この場合、減量基準変数の値が 3 つの運動プログラム間で異なるかどうかを理解したいと考えています。
代わりに、運動プログラムと夜間の平均睡眠時間数を分析する場合は、 2 つの要因が体重減少にどのように影響するかを確認したいため、二元配置分散分析を実行します。
ただし、繰り返しになりますが、基準変数は体重減少のままです。これは、この変数の値が運動と睡眠のさまざまなレベルでどのように異なるかに興味があるためです。
詳細情報:基準の有効性の簡単な説明
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る