Stata で多重共線性をテストする方法
回帰分析における 多重共線性は、2 つ以上の説明変数が相互に高度に相関しており、回帰モデル内で固有または独立した情報を提供しない場合に発生します。変数間の相関度が十分に高い場合、回帰モデルのフィッティングと解釈の際に問題が発生する可能性があります。
たとえば、次の変数を使用して重回帰を実行するとします。
可変応答:最大垂直ジャンプ
説明変数:靴のサイズ、身長、練習に費やした時間
この場合、背の高い人は靴のサイズが大きい傾向があるため、説明変数の靴のサイズと身長にはおそらく強い相関があると考えられます。これは、この回帰では多重共線性が問題になる可能性が高いことを意味します。
幸いなことに、分散膨張係数 (VIF)と呼ばれる指標を使用して多重共線性を検出することができます。この指標は、回帰モデル内の説明変数間の相関と相関の強さを測定します。
このチュートリアルでは、VIF を使用して Stata の回帰分析で多重共線性を検出する方法について説明します。
例: Stata の多重共線性
この例では、 autoという Stata の組み込みデータセットを使用します。次のコマンドを使用してデータセットをロードします。
自動的に使用する
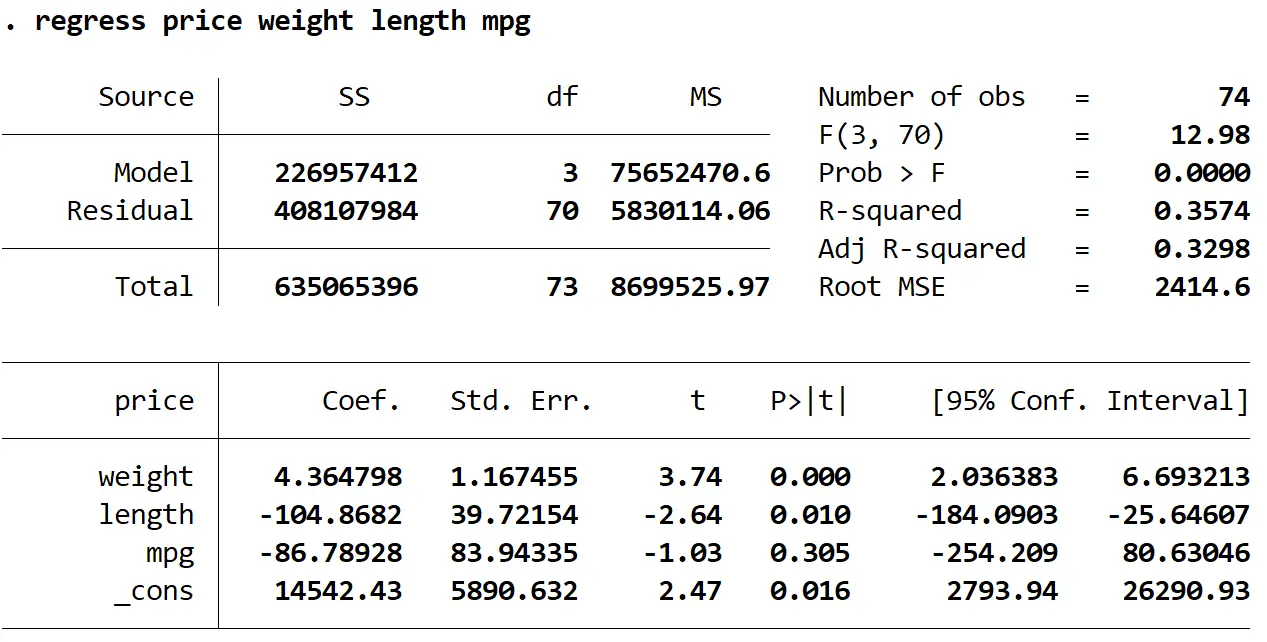
regressコマンドを使用して、応答変数として価格、説明変数として重量、長さ、mpg を使用して重線形回帰モデルを近似します。
回帰 価格 重量 長さ mpg
次に、 viveコマンドを使用して多重共線性をテストします。
活気のある
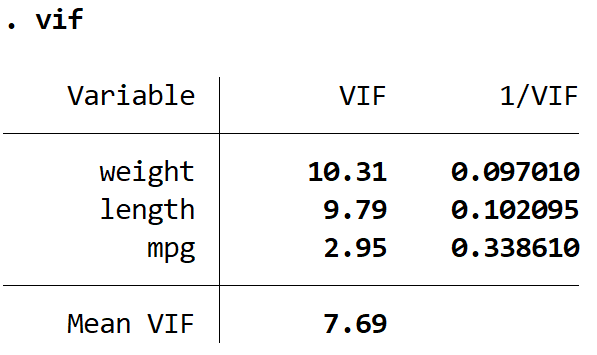
これにより、モデル内の各説明変数の VIF 値が生成されます。 VIF 値は 1 から始まり、上限はありません。 VIF を解釈するための一般的なルールは次のとおりです。
- 値 1 は、モデル内の特定の説明変数と他の説明変数の間に相関関係がないことを示します。
- 1 ~ 5 の値は、特定の説明変数とモデル内の他の説明変数の間に中程度の相関関係があることを示しますが、多くの場合、特別な注意を必要とするほど深刻ではありません。
- 5 より大きい値は、モデル内の特定の説明変数と他の説明変数の間に重大な相関関係がある可能性があることを示します。この場合、回帰結果の係数推定値と p 値は信頼できない可能性があります。
重さと長さの VIF 値が 5 より大きいことがわかり、回帰モデルで多重共線性が問題である可能性が高いことを示しています。
多重共線性にどう対処するか
多くの場合、多重共線性に対処する最も簡単な方法は、問題の変数の 1 つを単純に削除することです。これは、削除しようとしている変数はいずれにしても冗長である可能性が高く、モデルに固有の情報や独立した情報をほとんど追加しないためです。
どの変数を削除するかを決定するには、 corrコマンドを使用して相関行列を作成し、モデル内の各変数間の相関係数を表示します。これは、どの変数が相互に高い相関関係にあり、問題を引き起こす可能性があるかを特定するのに役立ちます。多重共線性の問題:
正しい価格、重量、長さ、mpg
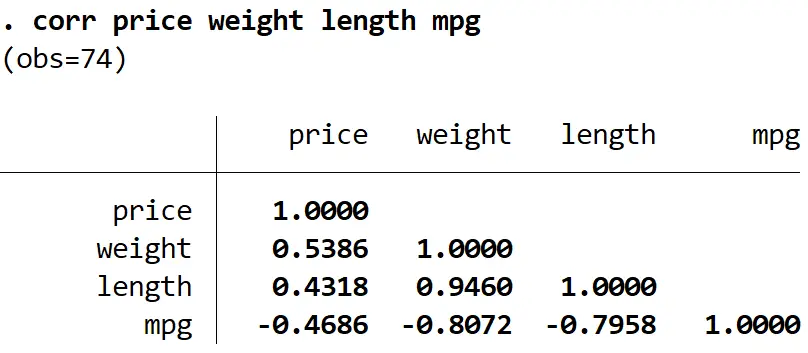
長さは重量とmpgの両方と高い相関があり、応答変数価格との相関が最も低いことがわかります。したがって、モデルの長さを削除すると、回帰モデル全体の品質を低下させることなく多重共線性の問題を解決できる可能性があります。
これをテストするには、説明変数として体重と mpg のみを使用して回帰分析を再度実行します。
回帰価格重量mpg
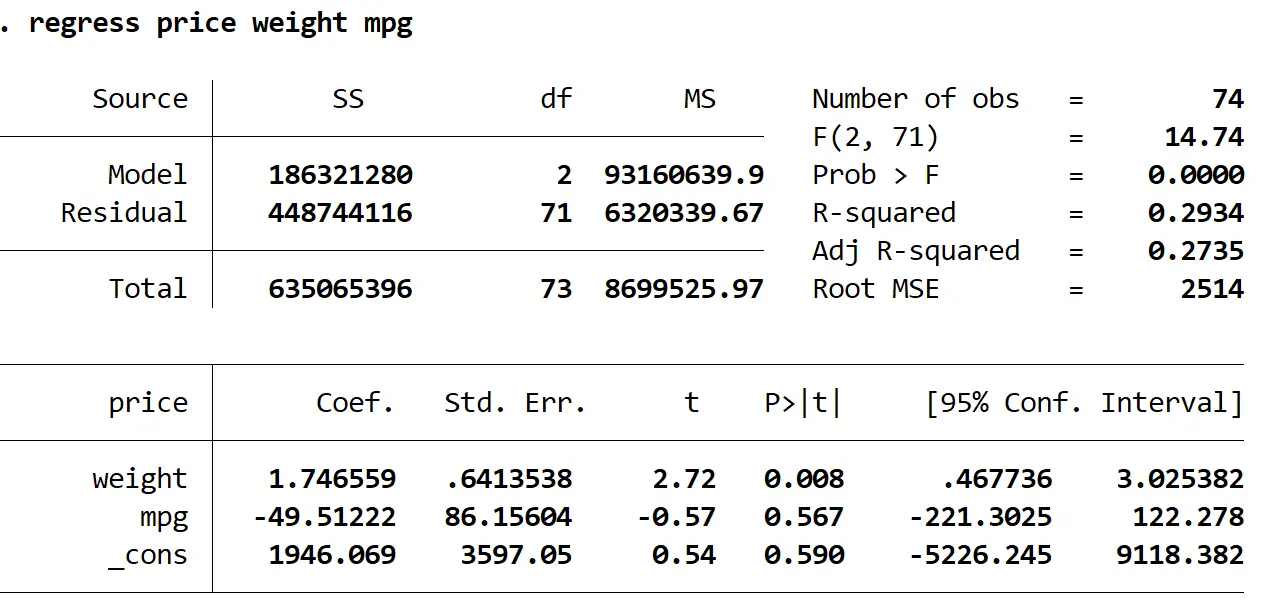
このモデルの調整後の R 二乗は、前のモデルの0.3298と比較して0.2735であることがわかります。これは、モデルの全体的な有用性がわずかに低下しただけであることを示しています。次に、 VIFコマンドを使用して VIF 値を見つけることができます。
活気のある
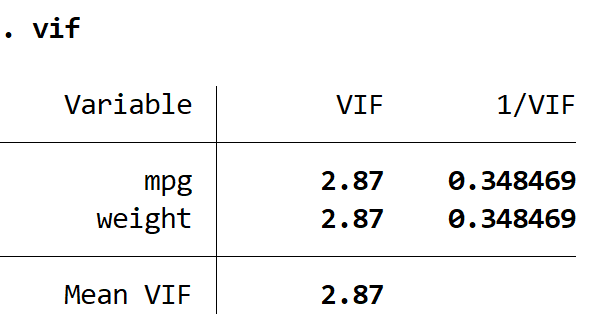
どちらの VIF 値も 5 未満であり、モデル内で多重共線性が問題ではなくなっていることを示しています。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る