検証セットとテストセット: 違いは何ですか?
機械学習アルゴリズムをデータセットに適応させるときは、通常、データセットを 3 つの部分に分割します。
1. トレーニング セット: モデルのトレーニングに使用されます。
2. 検証セット: モデルパラメータを最適化するために使用されます。
3. テスト セット: 最終モデルのパフォーマンスの不偏推定値を取得するために使用されます。
次の図は、これら 3 つの異なるタイプのデータ セットを視覚的に説明しています。
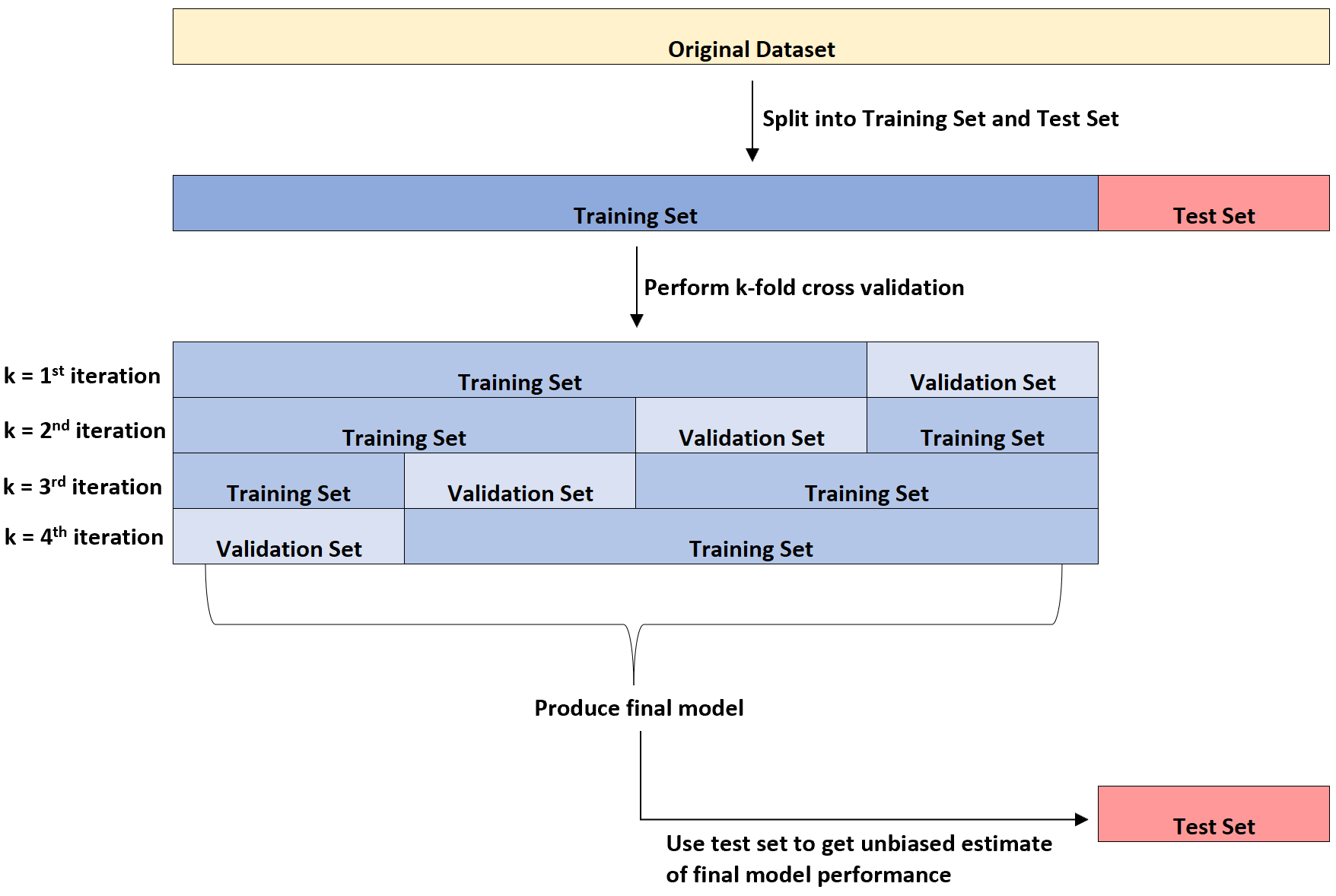
学生が混乱する点の 1 つは、検証セットとテスト セットの違いです。
簡単に言えば、検証セットはモデル パラメーターを最適化するために使用され、テスト セットは最終モデルの不偏推定を提供するために使用されます。
モデルが未確認のデータセットに適用されると、k 分割相互検証によって測定された誤り率は真の誤り率を過小評価する傾向があることがわかります。
したがって、最終モデルをテスト セットに適合させて、現実世界における真の誤り率がどの程度になるかについて不偏推定値を取得します。
次の例は、実際の検証セットとテスト セットの違いを示しています。
例: 検証セットとテスト セットの違いを理解する
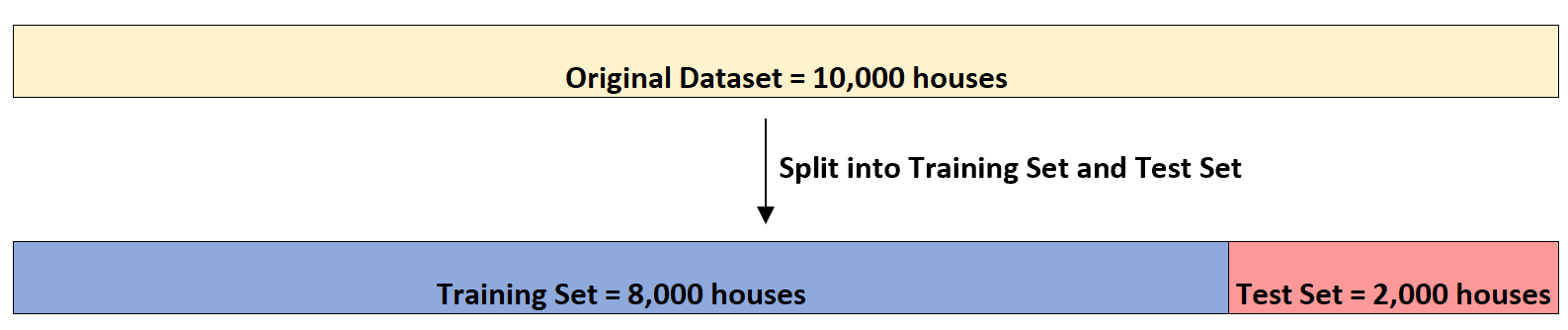
不動産投資家が、(1) 寝室の数、(2) 総平方フィート数、(3) バスルームの数を使用して、特定の家の販売価格を予測したいとします。
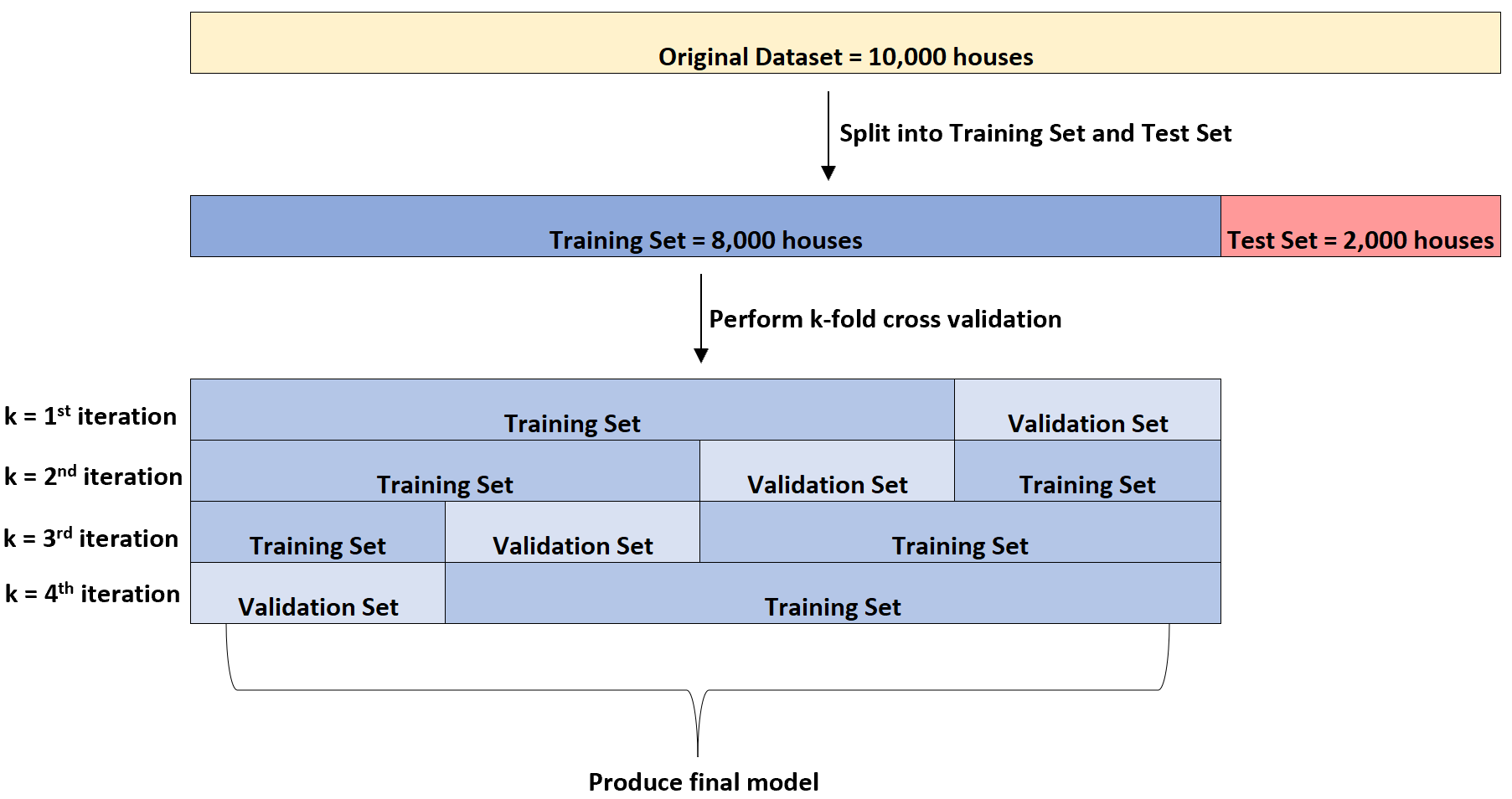
彼が 10,000 軒の住宅に関する情報を含むデータセットを持っているとします。まず、データセットを 8,000 軒のトレーニング セットと 2,000 軒のテスト セットに分割します。
次に、重線形回帰モデルをデータセットに 4 回当てはめます。毎回、トレーニング セットに 6,000 軒、検証セットに 2,000 軒を使用します。
これは、 k 分割相互検証と呼ばれます。
トレーニング セットはモデルのトレーニングに使用され、検証セットはモデルのパフォーマンスの評価に使用されます。検証セットには毎回、2,000 軒の異なるグループが使用されます。
この k 分割交差検証をいくつかの異なるタイプの回帰モデルに対して実行して、誤差が最も低いモデルを特定します (つまり、データセットに最も適合するモデルを特定します)。
最適なモデルを特定した後でのみ、最初に提示した 2,000 軒のテスト セットを使用して、モデルの最終パフォーマンスの不偏な推定値を取得します。
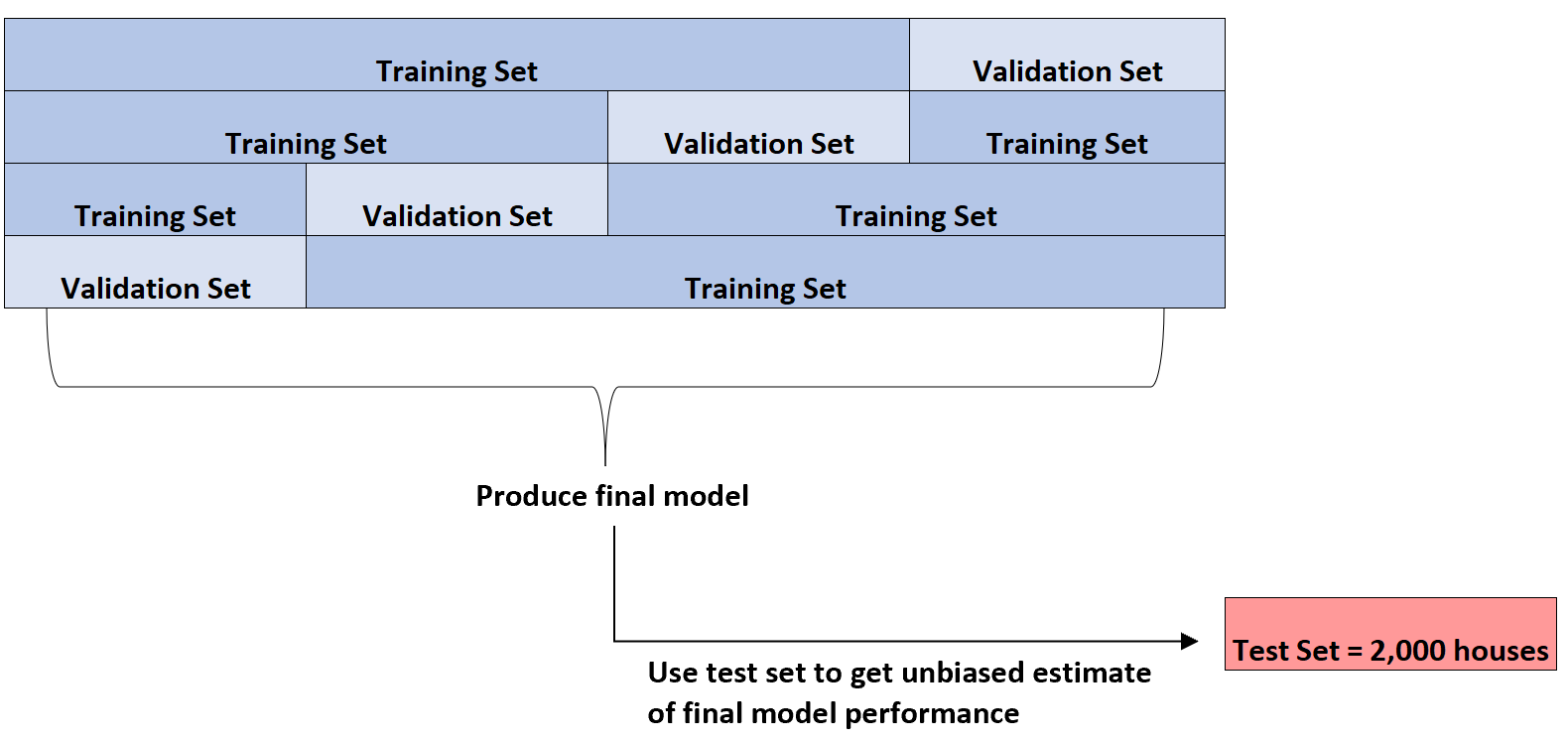
たとえば、平均絶対誤差が8.345である特定のタイプの回帰モデルを識別できます。つまり、予測された住宅価格と実際の住宅価格の間の絶対差の平均は 8,345 ドルになります。
次に、この正確な回帰モデルを、まだ使用されていない 2,000 軒の住宅のテスト セットに当てはめると、モデルの平均絶対誤差が8.847であることがわかります。
したがって、モデルの真の平均絶対誤差の不偏推定値は、8,847 ドルになります。
追加リソース
K-Fold 相互検証の簡単なガイド
Python で K-Fold 相互検証を実行する方法
R で K-Fold 相互検証を実行する方法
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る