機械学習を強化するための簡単な入門
ほとんどの教師あり機械学習アルゴリズムは、線形回帰、 ロジスティック回帰、リッジ回帰などの単一の予測モデルの使用に基づいています。
ただし、 バギングやランダム フォレストなどの方法では、元のデータセットの繰り返しブートストラップ サンプルに基づいてさまざまなモデルが構築されます。新しいデータの予測は、個々のモデルによって行われた予測の平均を取ることによって行われます。
これらの方法では、次のプロセスを使用するため、単一の予測モデルのみを使用する方法よりも予測精度が向上する傾向があります。
- まず、 分散が高くバイアスが低い個々のモデルを構築します (例: 深く成長したデシジョン ツリー)。
- 次に、個々のモデルによって行われた予測を平均して、分散を削減します。
予測精度をさらに大幅に向上させる傾向のある別の方法は、ブースティングとして知られています。
ブーストとは何ですか?
ブースティングはあらゆるタイプのモデルで使用できる方法ですが、最もよく使用されるのはデシジョン ツリーです。
ブーストの背後にある考え方はシンプルです。
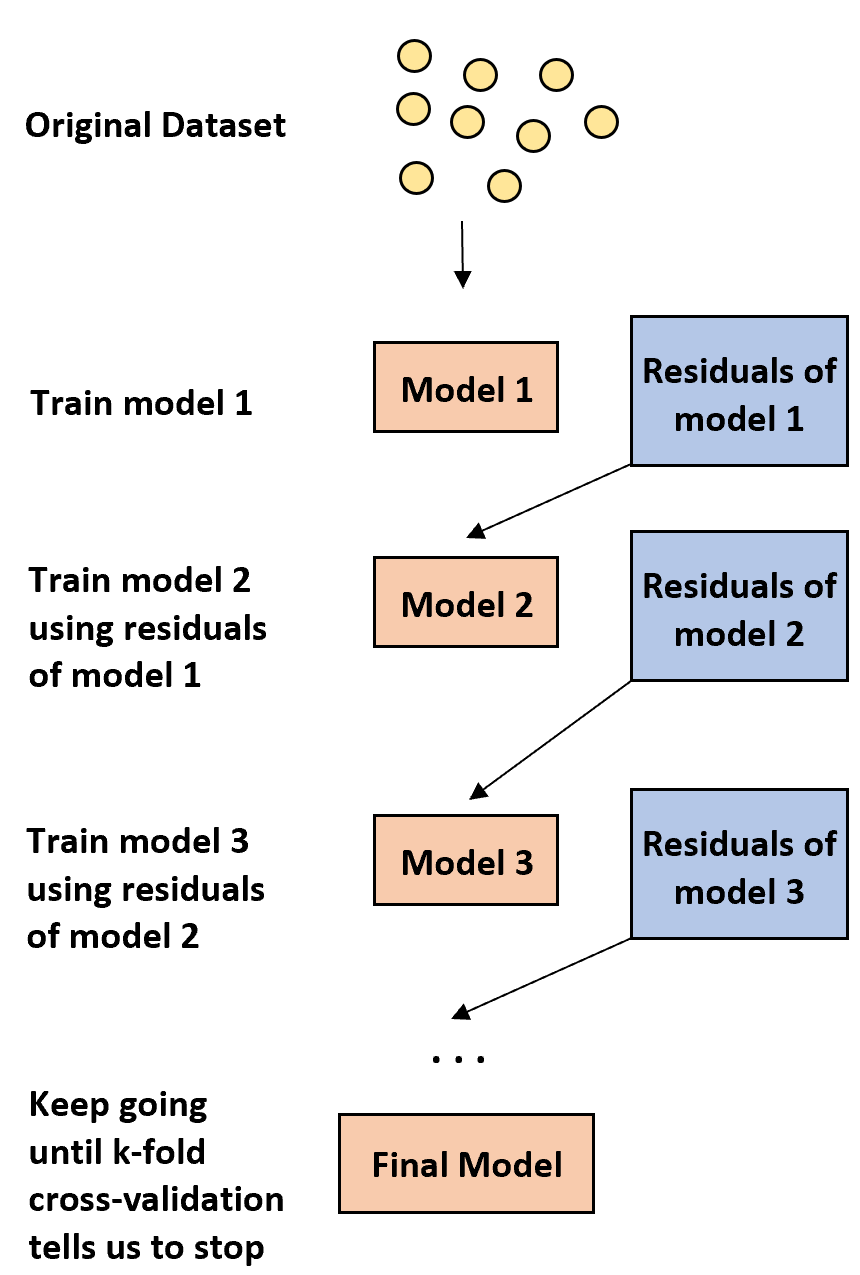
1. まず、弱いモデルを構築します。
- 「弱い」モデルとは、エラー率がランダムな推定よりわずかに優れているだけのモデルです。
- 実際には、これは通常、1 つまたは 2 つの分割のみを含む決定木です。
2. 次に、前のモデルの残差に基づいて別の弱いモデルを構築します。
- 実際には、前のモデルの残差 (つまり、予測の誤差) を使用して、全体的な誤差率をわずかに改善する新しいモデルを適合させます。
3. k 分割相互検証によって停止が指示されるまで、このプロセスを続けます。
- 実際には、k 分割交差検証を使用して、ブースト モデルの開発をいつ停止する必要があるかを特定します。
この方法を使用すると、弱いモデルから開始し、高い予測精度を備えた最終モデルが得られるまで、前のツリーのパフォーマンスを向上させる新しいツリーを順次構築することで、そのパフォーマンスを「向上」し続けることができます。
なぜブーストが機能するのでしょうか?
ブースティングにより、あらゆる機械学習の中で最も強力なモデルのいくつかを生成できることが判明しました。
多くの業界では、ブースト モデルは他のすべてのモデルよりも優れたパフォーマンスを発揮する傾向があるため、本番環境の参照モデルとして使用されます。
ブーストされたテンプレートが非常にうまく機能する理由は、次のような単純なアイデアを理解することにあります。
1.まず、改良されたモデルは、予測精度が低い弱い決定木を構築します。この決定木は、分散が低く、バイアスが高いと言われています。
2.改善されたモデルは以前のデシジョン ツリーの逐次的な改善プロセスに従うため、モデル全体は分散を大幅に増加させることなく、各ステップでのバイアスをゆっくりと減らすことができます。
3.最終的に適合されたモデルは、バイアスと分散が十分に低い傾向があり、新しいデータに対して低いテスト エラー率を生成できるモデルになります。
ブーストのメリットとデメリット
ブースティングの明白な利点は、他のほとんどすべてのタイプのモデルと比較して、高い予測精度でモデルを生成できることです。
潜在的な欠点は、適合された改良モデルの解釈が非常に難しいことです。新しいデータの応答値を予測する非常に優れた機能を提供できますが、これを達成するために使用される正確なプロセスを説明するのは困難です。
実際には、ほとんどのデータ サイエンティストと機械学習の専門家は、新しいデータの応答値を正確に予測できるようにするために、改良されたモデルを作成します。したがって、改良されたモデルの解釈が難しいという事実は、一般的には問題ではありません。
実践中のブースター
実際には、ブーストには次のようなさまざまな種類のアルゴリズムが使用されます。
データセットのサイズとマシンの処理能力に応じて、これらの方法のいずれかが他の方法よりも優先される場合があります。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る