Python で正規分布を生成する方法 (例付き)
次の構文を使用するnumpy.random.normal()関数を使用すると、Python で正規分布をすばやく生成できます。
numpy. random . normal (loc=0.0, scale=1.0, size=None)
金:
- loc:分布の平均。デフォルト値は 0 です。
- スケール:分布の標準偏差。デフォルト値は 1 です。
- サイズ:サンプルサイズ。
このチュートリアルでは、この関数を使用して Python で正規分布を生成する例を示します。
例: Python での正規分布の生成
次のコードは、Python で正規分布を生成する方法を示しています。
from numpy. random import seed
from numpy. random import normal
#make this example reproducible
seed(1)
#generate sample of 200 values that follow a normal distribution
data = normal (loc=0, scale=1, size=200)
#view first six values
data[0:5]
array([ 1.62434536, -0.61175641, -0.52817175, -1.07296862, 0.86540763])
この分布の平均と標準偏差をすぐに見つけることができます。
import numpy as np
#find mean of sample
n.p. mean (data)
0.1066888148479486
#find standard deviation of sample
n.p. std (data, ddof= 1 )
0.9123296653173484
簡単なヒストグラムを作成して、データ値の分布を視覚化することもできます。
import matplotlib. pyplot as plt
count, bins, ignored = plt. hist (data, 30)
plt. show ()
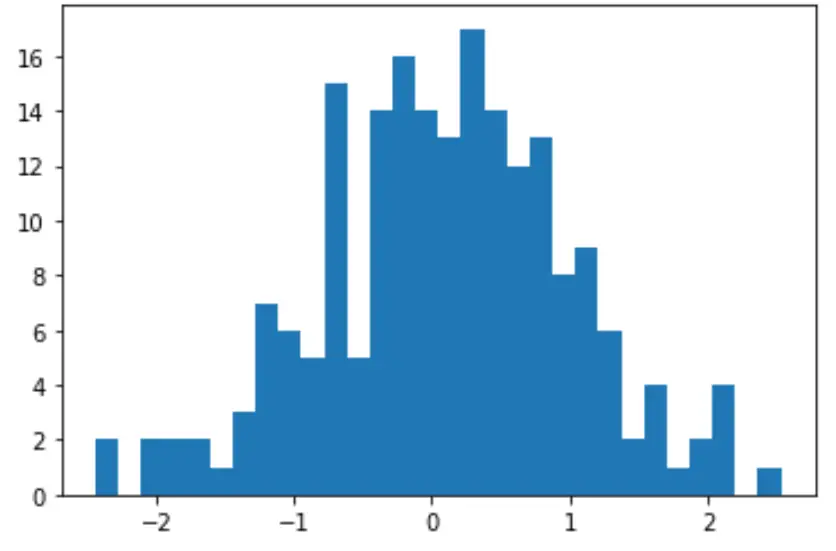
Shapiro-Wilk 検定を実行して、データセットが正規母集団からのものであるかどうかを確認することもできます。
from scipy. stats import shapiro
#perform Shapiro-Wilk test
shapiro(data)
ShapiroResult(statistic=0.9958659410, pvalue=0.8669294714)
検定の p 値は0.8669であることがわかります。この値は 0.05 未満ではないため、サンプル データは正規分布した母集団からのものであると想定できます。
正規分布からデータのランダムなサンプルを生成するnumpy.random.normal()関数を使用してデータを生成したため、この結果は驚くべきことではありません。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る