残留ギャップとは何ですか? (定義&例)
残差分散(「説明不能な分散」とも呼ばれます) は、モデル変数では説明できないモデル内の分散を指します。
モデルの残差分散が高くなるほど、モデルがデータの変動を説明できなくなります。
残差分散は、2 つの異なる統計モデルの結果に現れます。
1. ANOVA: 3 つ以上の独立したグループの平均を比較するために使用されます。
2. 回帰: 1 つ以上の予測変数と応答変数の間の関係を定量化するために使用されます。
次の例は、これらの各方法で残差分散を解釈する方法を示しています。
ANOVA モデルの残差分散
ANOVA (分散分析) モデルを当てはめるたびに、次のような ANOVA テーブルが作成されます。
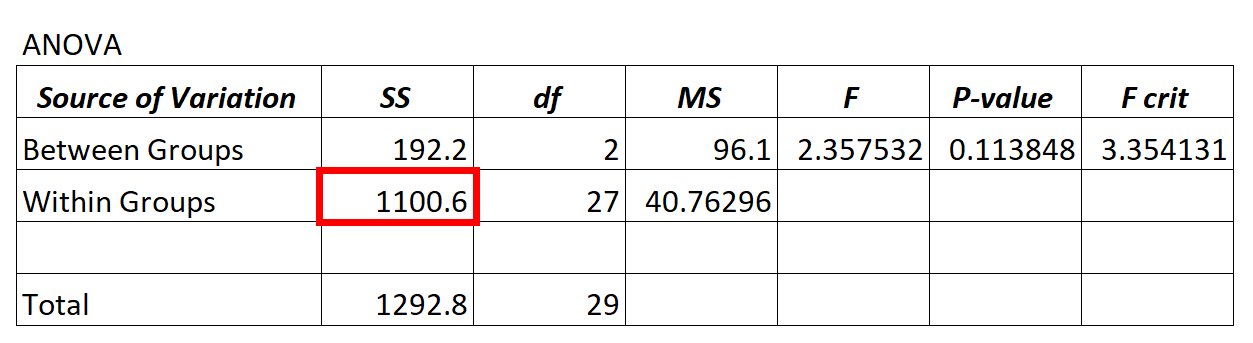
ANOVA モデルからの残差分散値は、グループ内変動の SS (「平方和」) 列に表示されます。
この値は「二乗誤差の合計」とも呼ばれ、次の式を使用して計算されます。
Σ(X ij – X j ) 2
金:
- Σ : 「和」を意味するギリシャ語の記号
- X ij : グループ j のi 番目の観測値
- X j : グループ j の平均
上記の ANOVA モデルでは、残差分散が 1100.6 であることがわかります。
この残差分散が「高い」かどうかを判断するには、グループ内の平均平方和とグループ間の平均平方和を計算し、その 2 つの比を求めます。これにより、ANOVA 表の全体的な F 値が得られます。
- F = MSが入る/ MSが入る
- F = 96.1 / 40.76296
- F = 2.357
上記の ANOVA 表の F 値は 2.357 で、対応する p 値は 0.113848 です。この p 値は α = 0.05 以上であるため、帰無仮説を棄却する十分な証拠がありません。
これは、比較しているグループ間の平均差が大幅に異なると言える十分な証拠がないことを意味します。
これは、ANOVA モデルの残差分散が、モデルが実際に説明できる変動と比較して高いことを示しています。
回帰モデルの残差分散
回帰モデルでは、残差分散は、予測データ ポイントと観測データ ポイントの差の二乗和として定義されます。
次のように計算されます。
Σ(ŷ i – y i ) 2
金:
- Σ : 「和」を意味するギリシャ語の記号
- ŷ i :予測されたデータ点
- y i :観測されたデータ点
回帰モデルを当てはめると、通常は次のような結果が得られます。
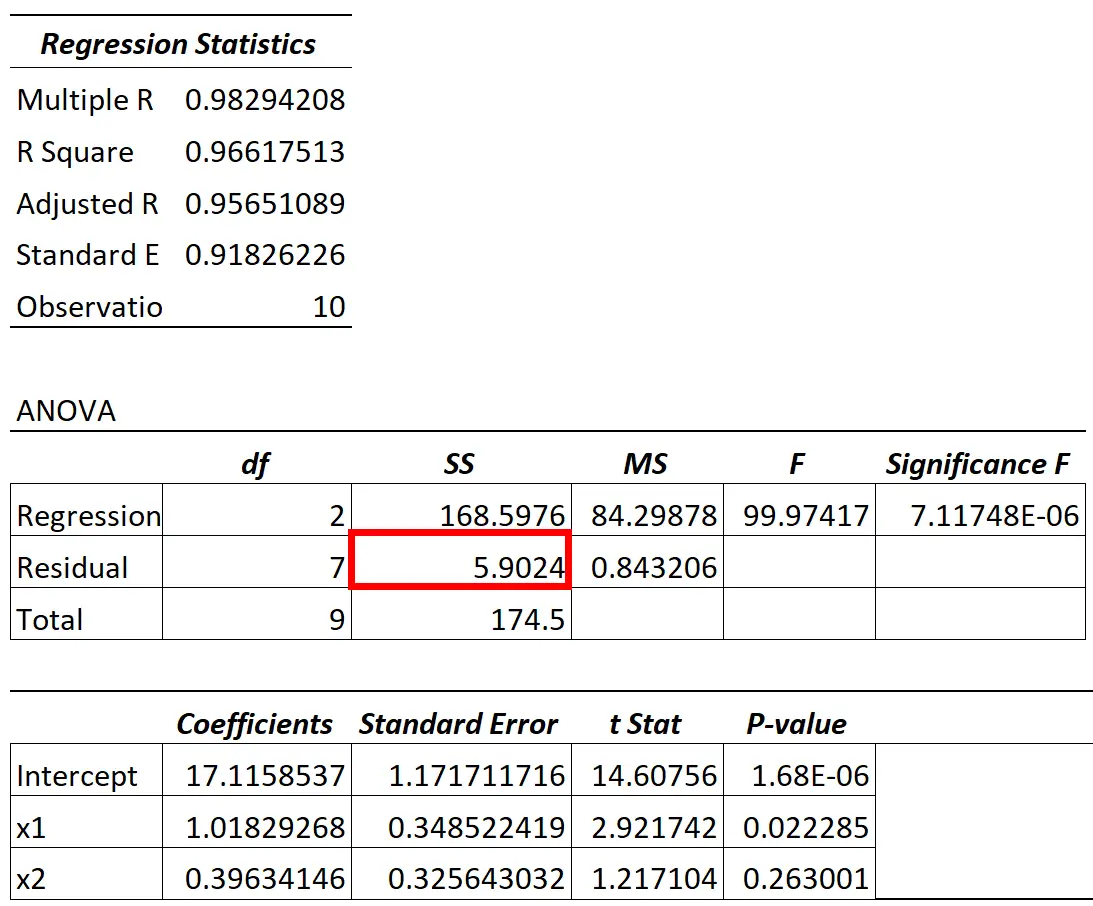
ANOVA モデルの残差分散値は、残差変動の SS (「平方和」) 列で確認できます。
モデル内の総変動に対する残差変動の比率は、モデル内の予測変数では説明できない応答変数の変動のパーセンテージを示します。
たとえば、上の表では、このパーセンテージは次のように計算されます。
- 説明できない変動 = SS 残留 / SS 合計
- 説明できない変動 = 5.9024 / 174.5
- 説明できない変動 = 0.0338
この値は、次の式を使用して計算することもできます。
- 説明できない変動 = 1 – R 2
- 説明できない変動 = 1 – 0.96617
- 説明できない変動 = 0.0338
モデルの R 二乗値は、予測変数によって説明できる応答変数の変動のパーセンテージを示します。
したがって、説明できない変動が少ないほど、モデルは予測変数を使用して応答変数の変動を説明する能力が高くなります。
追加リソース
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る