サンプリング (統計)
この記事では、統計的サンプリングとは何かについて説明します。さらに、さまざまな種類のサンプルがどのように作成されるか、およびそれぞれの例を確認できます。
統計におけるサンプリングとは何ですか?
統計学におけるサンプリングは、母集団のサンプルを選択するプロセスです。言い換えれば、サンプリングは、統計調査を実行するために個人のグループを選択する方法です。
たとえば、サンプリングの 1 つの方法は、個人をランダムに選択することです。したがって、統計的母集団のサイズを研究したい場合は、単純なランダムサンプリングによって研究サンプルを選択できます。
母集団を抽出するにはいくつかの方法があり、それぞれに長所と短所があります。以下では、さまざまなタイプの統計的サンプリングがどのようなものであるかを見ていきます。
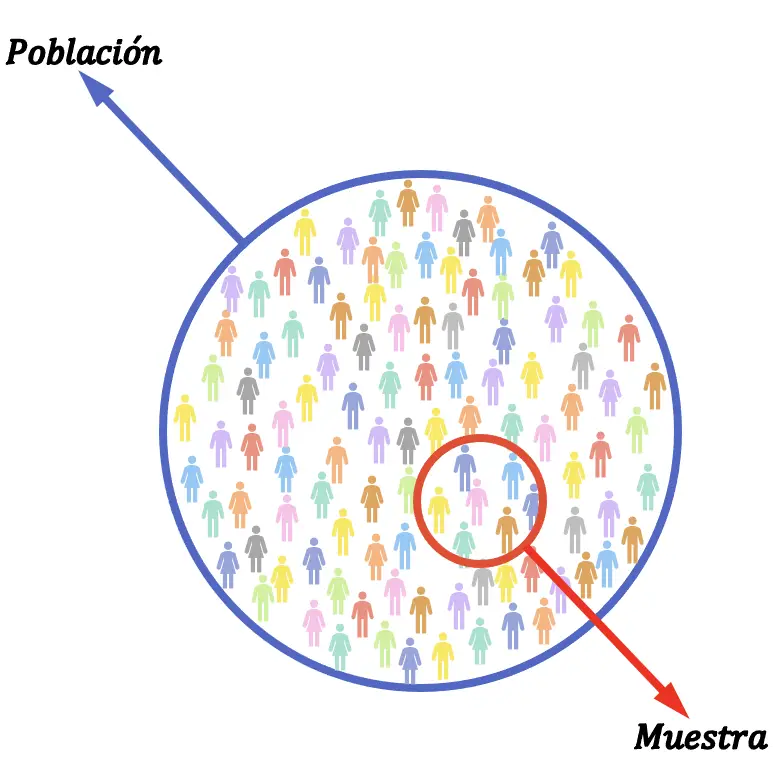
統計におけるサンプリングは、対象母集団の一部のみを調査し、サンプルの分析によって得られた結論を統計的推論によって母集団全体に推定できるため、非常に便利です。これは、検索時間とコストを削減できるため、大きな利点です。
サンプリングフレーム
統計学において、サンプリング フレーム(またはサンプリング フレーム) は、サンプル内で選択できる母集団のすべての要素のリストです。言い換えれば、サンプリング フレームは、統計研究の対象となる宇宙のすべての要素のリストです。
たとえば、ある都市の住民について統計調査を実行したい場合、この調査のサンプリング フレームはその都市の登録簿です。これは、この都市に住んでいるすべての人々が含まれるリストであるためです。
したがって、サンプリングフレームは、統計調査のサンプルを取得するために使用されます。サンプリング フレームが適切に設計されていれば、統計分析のためのサンプリングがはるかに簡単になります。
統計におけるサンプリングの種類
統計におけるサンプリングの種類は次のとおりです。
- 確率サンプリング: サンプルがランダムに選択されるサンプリング。
- 単純なランダム サンプリング: サンプルは単純にランダムに選択されます。
- 系統的サンプリング: 最初の個人がランダムに選択され、サンプルの残りの要素が一定の間隔に従って選択されます。
- 層化サンプリング: サンプルを構成するために、対象母集団を層 (グループ) に分割し、各層から個人をランダムに選択します。
- クラスター サンプリング: サンプルは、ランダムに選択されたクラスター (自然グループ) で構成されます。
- 非確率サンプリング: 研究者がプロセスに偶然を含まず、基準に従ってサンプルを選択するサンプリング。
- 目的的サンプリング: 研究者の判断のみに基づいてサンプルから個人が選択されます。
- 利便性の高いサンプリング: サンプル メンバーは、アクセスのしやすさに基づいて選択されます。
- 連続サンプリング: 最初の初期サンプルが選択されて調査され、次に別のサンプルが選択されます。そして、研究の結論が得られるまで、さまざまなサンプルが研究されます。
- クォータ サンプリング: 最初にグループが形成され、次に各グループからクォータが選択されて調査サンプルが形成されます。
- 雪だるま式サンプリング: 研究者はサンプル内の最初の個人を選択し、その後、研究のために他の被験者を募集します。
統計サンプリングの各タイプについては、以下で詳しく説明します。
確率サンプリング
確率サンプリング手法は、サンプルの要素をランダムに選択することで構成されます。つまり、選択される確率はすべて同じです。
これは、サンプリングが確率であるとみなされるための必須の条件であり、統計母集団のすべての要素が選択可能でなければならず、さらに、選択される可能性が同じでなければなりません。
これまで見てきたように、さまざまなタイプの確率サンプリング方法には、単純ランダムサンプリング、系統的サンプリング、層化サンプリング、およびクラスターサンプリングがあります。
単純なランダムサンプリング
単純なランダムサンプリングでは、統計母集団の各要素が調査対象のサンプルに含まれる同じ確率が与えられます。したがって、サンプル内の個人は、他の基準を使用せずに単純にランダムに選択されます。
ランダムにシミュレーションするにはいくつかの方法がありますが、現在では時間を大幅に節約できる Excel などのコンピューター プログラムを使用して実行するのが一般的です。
体系的なサンプリング
系統的サンプリングでは、まず母集団の 1 つの要素がランダムに選択され、次にサンプル内の残りの要素が一定の間隔を使用して選択されます。
したがって、系統的サンプリングでは、サンプルから最初の個人をランダムに選択したら、サンプルから次の個人を選択するために、必要な間隔と同じだけ数をカウントする必要があります。そして、取得したいサンプルサイズと同じ数の個体がサンプル内に含まれるまで、同じ手順を繰り返します。
層化抽出法
層化サンプリング手法では、まず母集団を複数の層 (グループ) に分割し、次に各層から数人の個人をランダムに選択して研究サンプル全体を形成します。したがって、サンプルには各層から少なくとも 1 人のメンバーが存在することになります。
階層は均質なグループである必要があります。つまり、階層内の個人は、他の階層とは異なる独自の特性を持っています。したがって、個人は 1 つの階層にのみ属することができます。
集落抽出
クラスター サンプリングと層化サンプリングは非常に似ているため混同される可能性がありますが、よく見ると、これらは 2 つの異なるタイプの確率サンプリングです。
クラスター サンプリングでは、母集団内に自然クラスター (グループ) がすでに存在しているという事実を利用して、母集団内のすべての個人ではなく、少数のクラスターのみを研究します。
層化サンプリングとは異なり、この方法ではクラスターから特定の個人を選択する必要はありませんが、研究対象のグループを選択したら、そのメンバー全員を分析する必要があります。
クラスター サンプリングは、クラスター サンプリング、クラスター サンプリング、エリア サンプリングとも呼ばれます。
非確率サンプリング
非確率サンプリングでは、研究者の主観的な基準に基づいて個人が選択されます。したがって、非確率サンプリングでは、選択がランダムではないため、母集団のすべての要素がサンプルとして選択される確率が同じであるわけではありません。この機能は、非確率サンプリングと確率サンプリングを区別します。
論理的には、非確率サンプリングでは、誰をサンプルに含めるかを決定するのはその人であるため、調査の責任者は非常に重要です。そのため、信頼できる結果を得るには、研究者がその研究分野で豊富な知識と経験を持っていることが不可欠です。
上で説明したように、さまざまな種類の非確率サンプリング手法には、目的的サンプリング、便宜的サンプリング、連続的サンプリング、クォータ サンプリング、および雪だるま式サンプリングがあります。
目的を持ったサンプリング
目的のあるサンプリングは、研究サンプルを選択する際の研究者の裁量のみに依存します。
そのため、調査担当者はサンプル要素を選択するためのすべての決定権を持っています。したがって、あなたがその分野の専門家であることが重要です。
目的的サンプリングは、判断的サンプリング、判断的サンプリング、批判的サンプリング、目的的サンプリング、または意見サンプリングとも呼ばれます。
コンビニエンスサンプリング
コンビニエンスサンプリングでは、研究者はプロセスに偶然を含めることなく、個人へのアクセスの容易さの基準に基づいてサンプル対象を選択します。
つまり、母集団から個人を選択するこのタイプの非確率サンプリングでは、選択の利用可能性、近さ、または選択のコストなどの側面が評価されます。サンプリングをさらに促進するために、ボランティアが受け入れられることもあります。
便宜的サンプリングは、目的的選択サンプリングまたは機会サンプリングとも呼ばれます。
連続サンプリング
連続サンプリングでは、最初に最初のサンプルが選択されて調査され、最初のサンプルの結果が得られた後、別のサンプルが調査されます。そして、研究全体の最終結論が得られるまで、このプロセスが連続的に繰り返されます。
したがって、連続サンプリングでは単一のサンプルに焦点を当てるのではなく、同じ統計母集団からの異なるサンプルを研究し、最終的にすべてのグループから得られた情報から結論を導き出します。
クォータのサンプリング
クォータサンプリングでは、少なくとも 1 つの特性を共有する個人のグループ (または層) が最初に確立され、次に各グループからクォータが選択され、研究サンプルが形成されます。
集団をグループに分けるために使用される個人の特性も研究者によって決定されるため、研究を実施する責任者は、得られる結果に大きな影響を与えます。
雪だるまサンプリング
雪だるま式サンプリングでは、研究者は最初の参加者を選択し、その後、研究のために追加の参加者を募集します。
雪だるま式サンプリングのこの特徴により、参加者が研究のためにより多くの人を募集するにつれて、サンプルサイズがますます増加します(雪だるま効果)。
雪だるま式サンプリングは、チェーン サンプリングまたはチェーン参照サンプリングとも呼ばれます。
サンプリングと表示
統計学におけるサンプルとは、分析を実行するために母集団から選択された個人のグループです。つまり、実際には、統計調査を行う場合、対象となる母集団全体のうち、サンプルと呼ばれる母集団の一部のみが分析されます。
したがって、サンプリングとサンプルの違いは、サンプルが調査対象の母集団の一部であるということです。一方、サンプリングは統計研究のサンプルを選択する方法です。
したがって、サンプリングは、ターゲット母集団から調査対象のサンプルに移動することを可能にする手法であるため、統計において非常に重要です。
論理的には、選択したサンプルは誰でも良いというわけにはいきませんが、結論を母集団全体に推定できるようにするためには、特定の条件を満たしている必要があります。たとえば、サンプルが代表的であるためには、研究の特性に応じた最小サイズが必要です。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る