評価者間信頼性とは何ですか? (定義&例)
統計において、評価者間信頼性は、複数の評価者または裁判官の間の一致レベルを測定する方法です。
これは、テストのさまざまな項目によって生成された応答の信頼性を評価するために使用されます。テストの評価者間信頼性が低い場合は、テスト項目がわかりにくい、不明瞭である、または役に立たないことを示している可能性があります。
評価者間信頼性を測定するには、次の 2 つの一般的な方法があります。
1. 一致率
評価者間の信頼性を測定する簡単な方法は、審査員が同意する項目の割合を計算することです。
これはパーセント一致と呼ばれ、常に 0 と 1 の間に収まります。0 は評価者間で一致がないことを示し、1 は評価者間で完全な一致を示します。
たとえば、2 人の審査員がテストの 10 項目の難易度を 1 から 3 のスケールで評価するよう求められたとします。結果は次のとおりです。
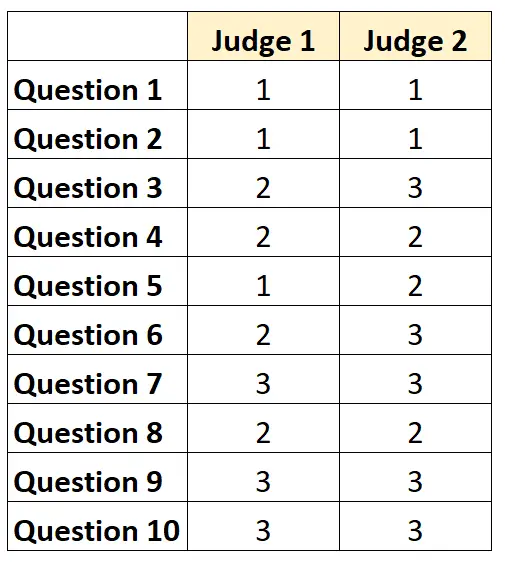
各質問について、両方のジャッジが同意する場合は「1」、同意しない場合は「0」を記入できます。
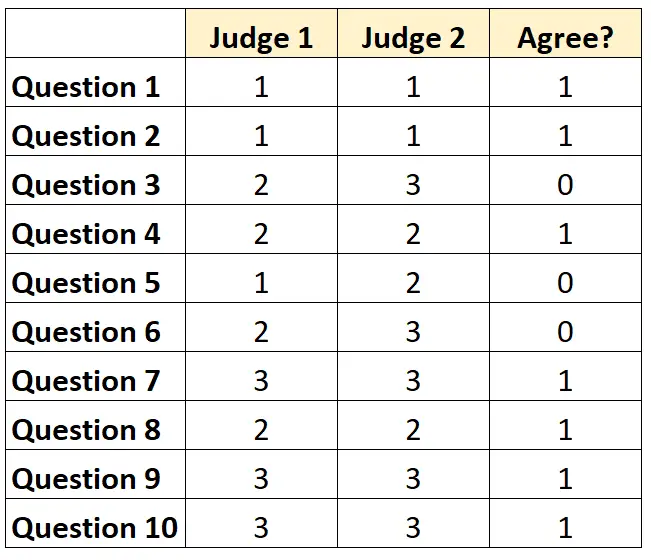
審査員が同意した質問の割合は 7/10 = 70%でした。
2. コーエンのカッパ
評価者間の信頼性を測定する最も困難な (そして最も厳密な) 方法は、 コーエンのカッパを使用することです。これは、評価者が特定の要素についてのみ同意する可能性があることを考慮しながら、評価者が同意する項目の割合を計算します。幸いなことに。
コーエンのカッパ式は次のように計算されます。
k = (p o – p e ) / (1 – p e )
金:
- p o :評価者間で観察された相対的な一致
- p e :偶然の一致の仮説確率
コーエンのカッパは常に 0 ~ 1 の範囲で、0 は評価者間で一致しないことを示し、1 は評価者間で完全に一致することを示します。
コーエンのカッパを計算する方法の段階的な例については、 このチュートリアルを参照してください。
評価者間信頼性を解釈する方法
評価者間の信頼性が高いほど、複数の審査員がテストの項目または質問をより一貫して同様のスコアで評価します。
一般に、テストが信頼できるとみなされるには、ほとんどの分野で少なくとも 75% の評価者間の合意が必要です。ただし、特定のドメインでは、より高い評価者間信頼性が必要になる場合があります。
たとえば、テレビ番組がどの程度受信されるかを判定するテストでは、評価者間信頼性 75% が許容される可能性があります。
一方、複数の医師が特定の患者に対して特定の治療法を適用すべきかどうかを判断する医療現場では、95% の評価者間信頼性が要求される場合があります。
ほとんどの学術環境や厳密な研究分野では、評価者間信頼性の計算にコーエンのカッパが使用されることに注意してください。
追加リソース
信頼性解析の概要
信頼性を 2 つに分けるとは何ですか?
テストと再テストの信頼性とは何ですか?
平行形状の信頼性とは何ですか?
測定の標準誤差とは何ですか?
コーエンのカッパ計算機
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る