Spss でカイ二乗適合度検定を実行する方法
カイ二乗適合度検定は、カテゴリ変数が仮説分布に従うかどうかを判断するために使用されます。
このチュートリアルでは、SPSS でカイ二乗適合度検定を実行する方法を説明します。
例: SPSS のカイ二乗適合度検定
店主は、毎日同じ数の顧客が店に来ると言いました。この仮説を検証するために、研究者は特定の週に来店する顧客の数を記録し、次のことを発見しました。
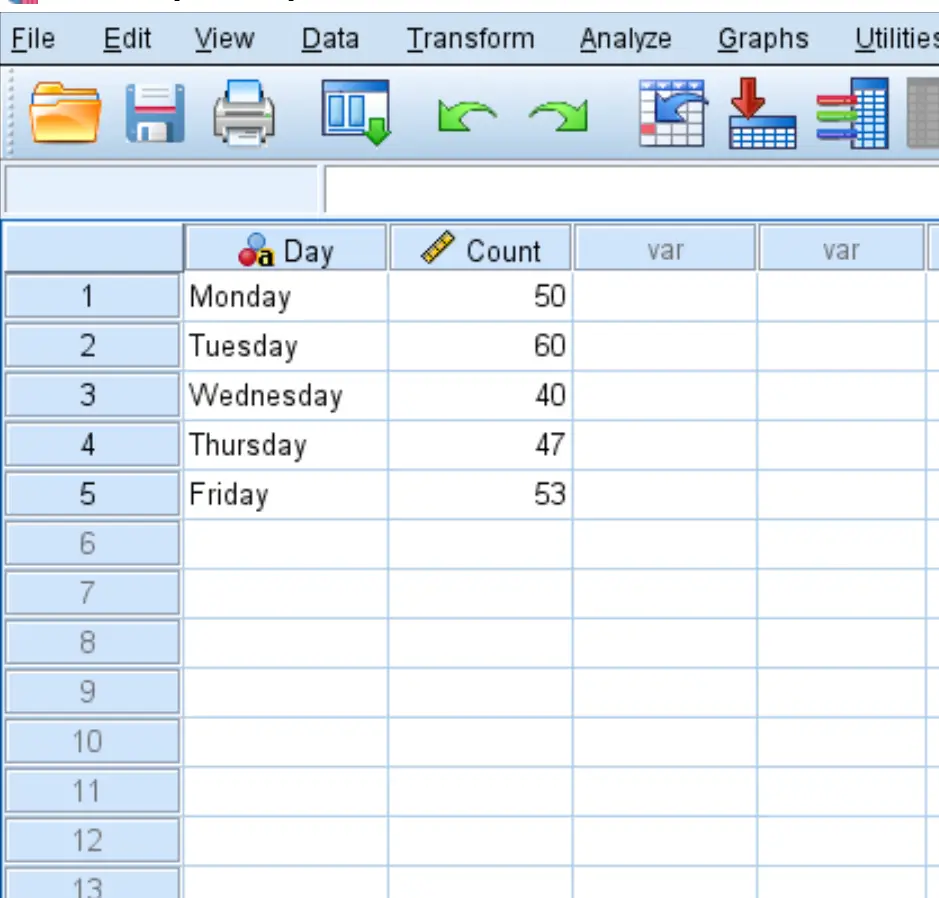
- 月曜日: 50 人の顧客
- 火曜日:お客様60名
- 水曜日:お客様40名
- 木曜日:お客様47名
- 金曜日: 53名のお客様
次の手順を使用して SPSS でカイ 2 乗適合度検定を実行し、データが店舗所有者の主張と一致しているかどうかを判断します。
ステップ 1: データを入力します。
まず、データを次の形式で SPSS に入力します。
ステップ 2: 重みのあるボックスを使用します。
テストが正しく機能するには、「Day」変数が「Number」変数によって重み付けされる必要があることを SPSS に伝える必要があります。
[データ]タブをクリックし、 [ウェイト ケース]をクリックします。
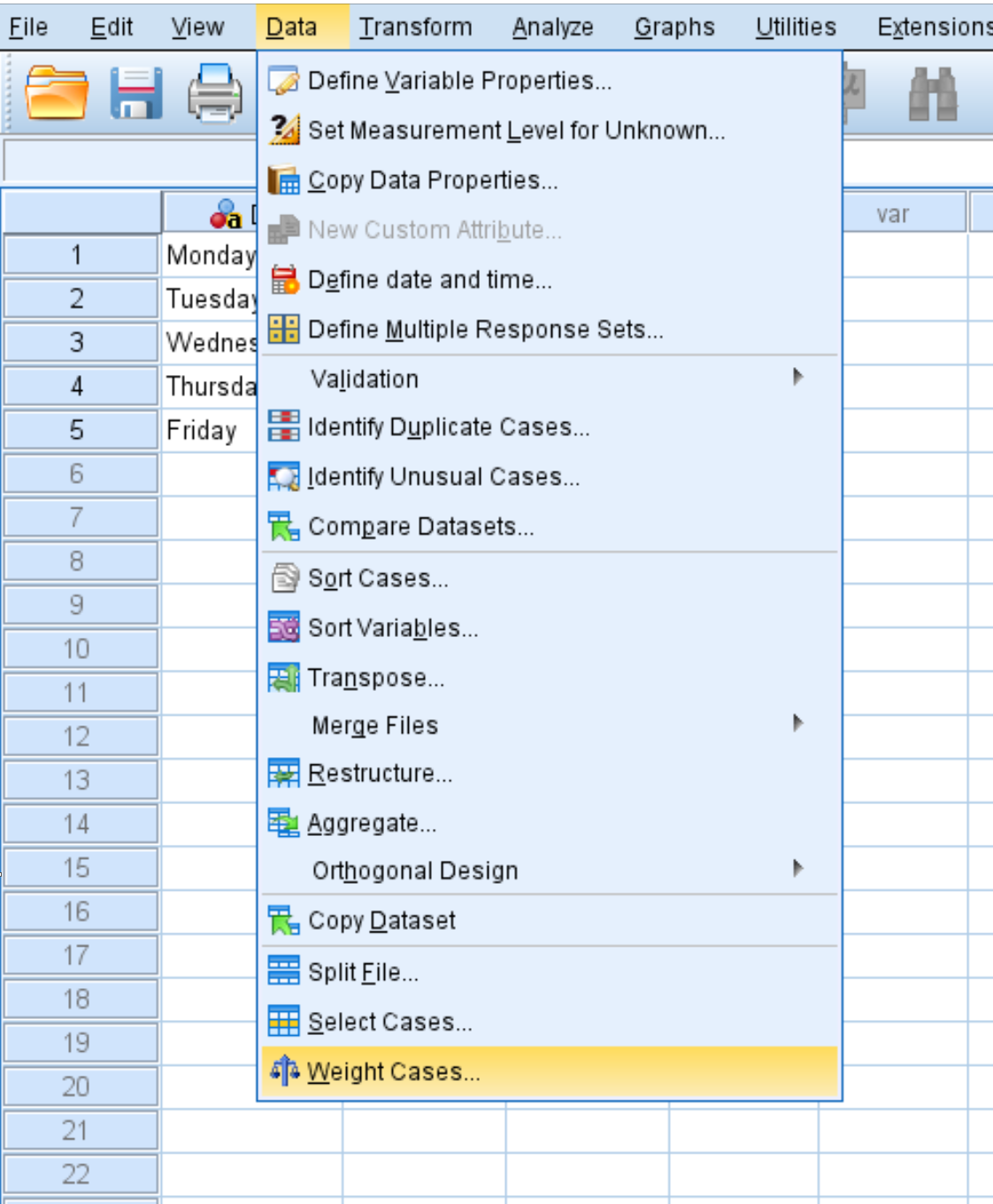
表示される新しいウィンドウで、 Count変数を「Test Variable List」というラベルの付いた領域にドラッグします。次に、 「OK」をクリックします。
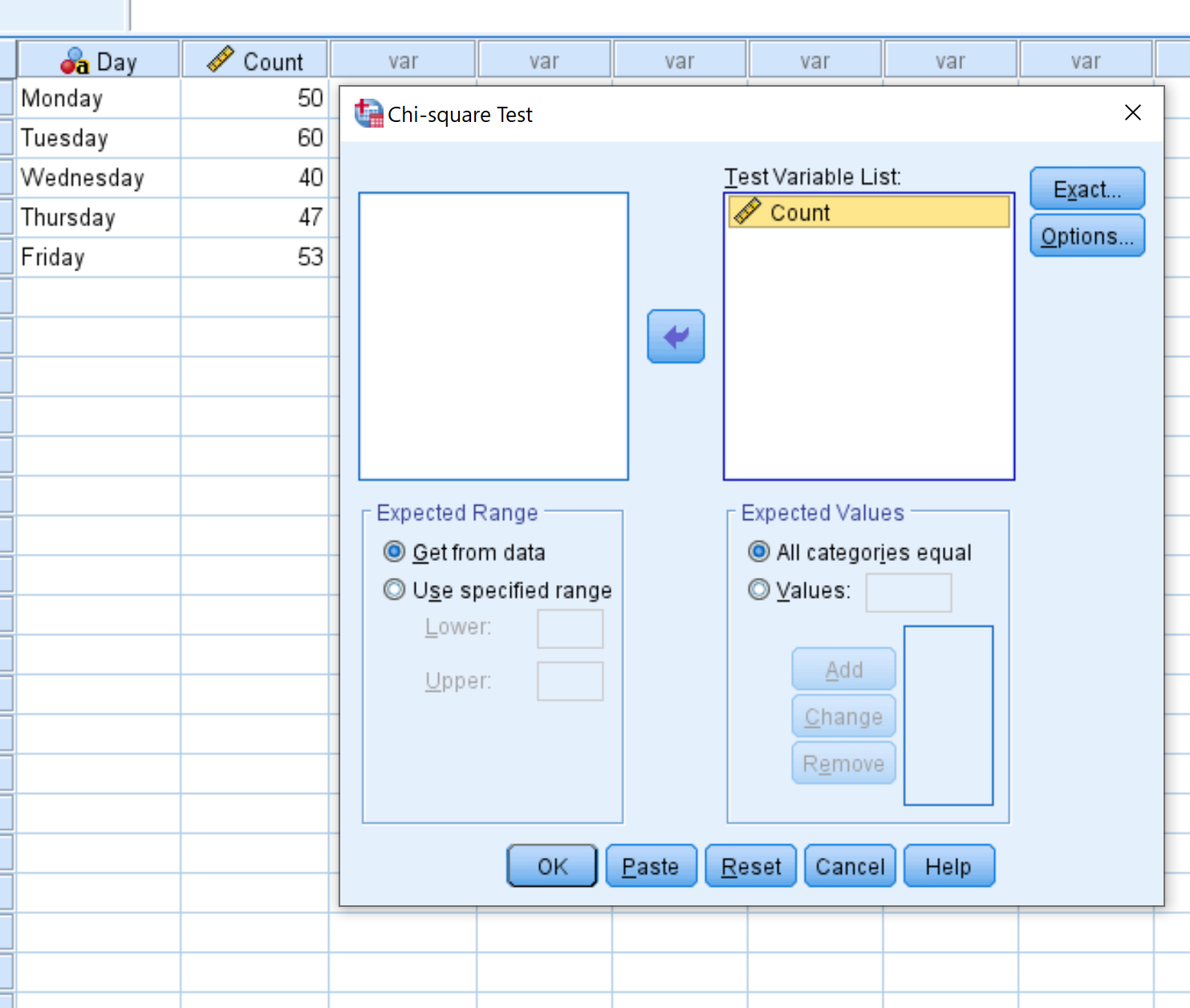
ステップ 3: カイ二乗適合度検定を実行します。
[分析]タブ、 [ノンパラメトリック テスト] 、 [レガシー ダイアログ] 、 [カイ二乗] の順にクリックします。
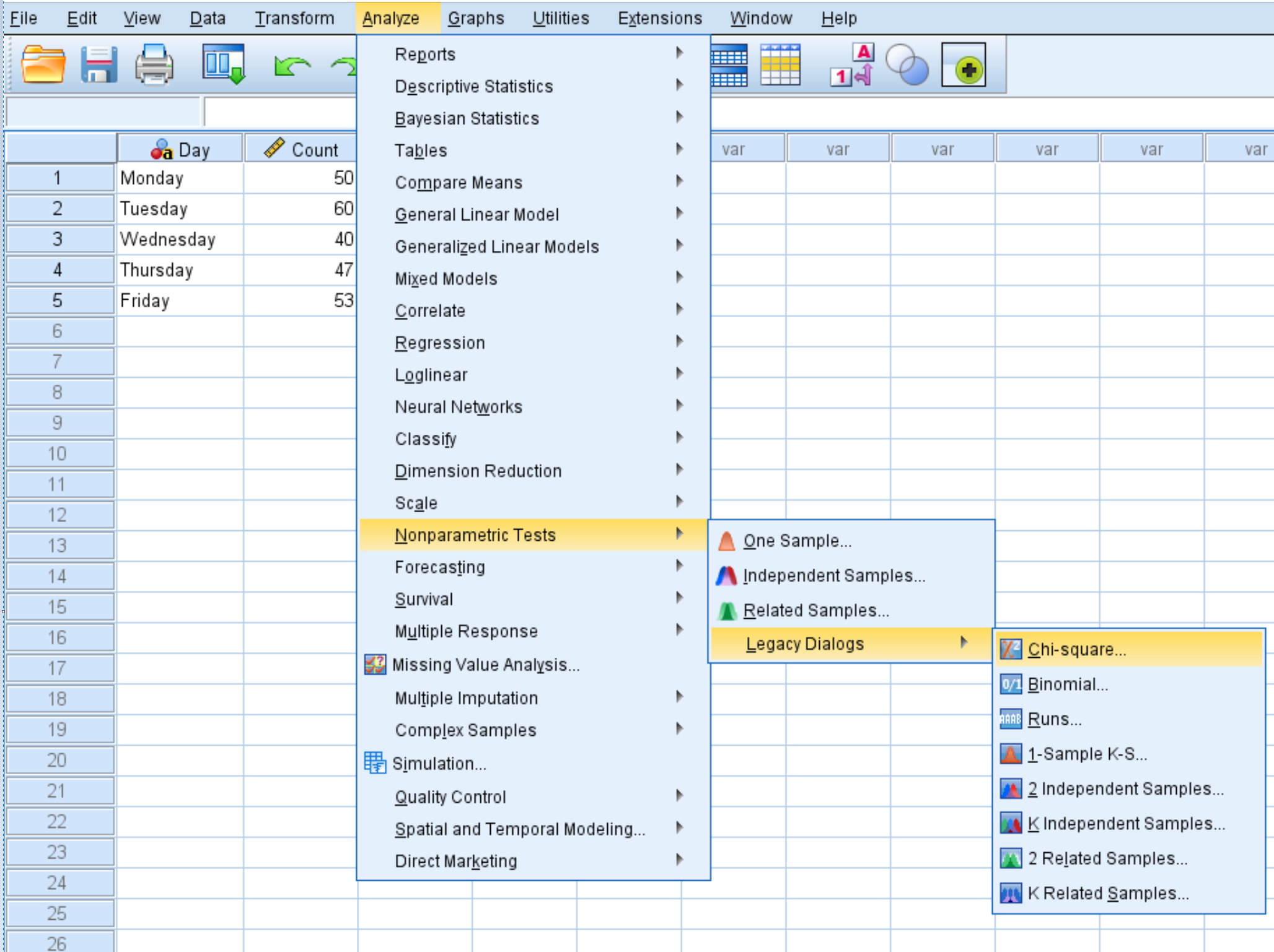
表示される新しいウィンドウで、 Count変数を「Test Variable List」というラベルの付いた領域にドラッグします。
各カテゴリ (つまり、曜日) の毎日の予想訪問者数は同じであるため、[すべてのカテゴリが等しい]の横にあるラベルはオンのままにしておきます。次に、 「OK」をクリックします。
ステップ 4: 結果を解釈する。
[OK]をクリックすると、カイ二乗適合度検定の結果が表示されます。
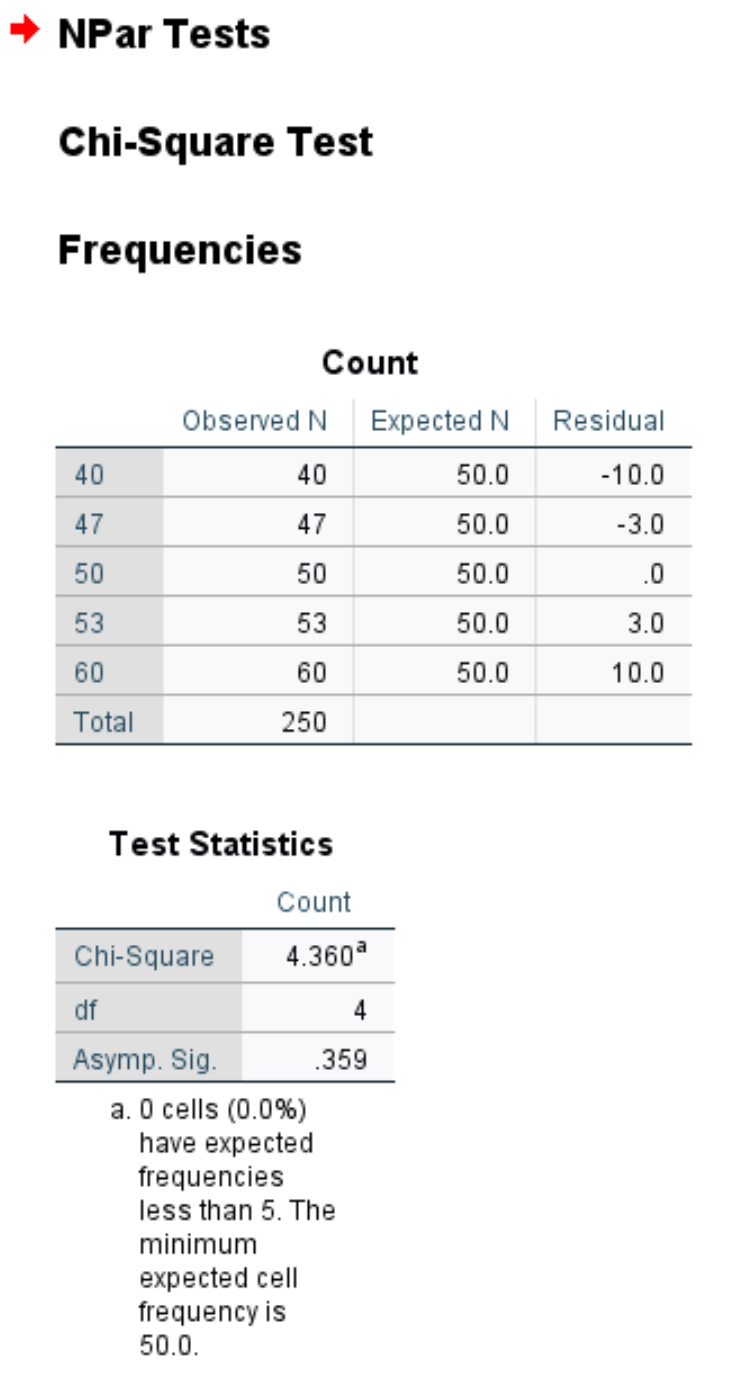
最初の表は、曜日ごとに観測された顧客数と予測される顧客数、および観測された顧客と予測された顧客の残差 (つまり差) を示しています。
2 番目の表には、次の数値が表示されます。
カイ二乗:カイ二乗検定統計量、4.36。
df: #categories-1 = 5-1 = 4 として計算される自由度。
無症状。 Sig: 4 自由度のカイ 2 乗値 4.36、つまり 0.359 に対応する p 値。この値は、カイ二乗スコアから P 値への計算を使用して求めることもできます。
p 値 (0.359) は 0.05 未満ではないため、帰無仮説を棄却できません。これは、顧客の本当の分布が店主が報告したものと異なると言える十分な証拠がないことを意味します。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る